LV05-01-进程-01-进程的基础知识
本文主要是进程的基础知识相关笔记,若笔记中有错误或者不合适的地方,欢迎批评指正😃。
点击查看使用工具及版本
| Windows | windows11 |
| Ubuntu | Ubuntu16.04的64位版本 |
| VMware® Workstation 16 Pro | 16.2.3 build-19376536 |
| SecureCRT | Version 8.7.2 (x64 build 2214) - 正式版-2020年5月14日 |
| 开发板 | 正点原子 i.MX6ULL Linux阿尔法开发板 |
| uboot | NXP官方提供的uboot,NXP提供的版本为uboot-imx-rel_imx_4.1.15_2.1.0_ga(使用的uboot版本为U-Boot 2016.03) |
| linux内核 | linux-4.15(NXP官方提供) |
| STM32开发板 | 正点原子战舰V3(STM32F103ZET6) |
点击查看本文参考资料
| 参考方向 | 参考原文 |
| --- | --- |
点击查看相关文件下载
| --- | --- |
一、进程与程序
1. 基本概念
| 程序 | 程序是存放在磁盘上的指令和数据的有序集合(文件),是静态的文件。 |
| 进程 | 进程是执行一个程序所分配的资源的总称,它是程序的一次执行过程,是动态的,包括创建、调度、执行和消亡等。当程序被加载到内存中运行之后它就称为了一个进程,当程序运行结束后也就意味着进程终止,这就是进程的一个生命周期。 |
| 进程号 | Linux系统下的每一个进程都有一个进程号(process ID,简称PID),进程号是一个正数,用于唯一标识系统中的某一个进程。 |
| 主进程 | 程序执行的入口,我们自己编写的C语言程序中,一般是main函数。 |
| 父进程 | 已经创建了一个或者多个子进程的进程, 任何进程都有父进程,追根溯源是系统启动程序。我们一般写的程序,主进程是最初始的父进程。 |
| 子进程 | 父进程创建的进程,一个子进程只能对应一个父进程。 |
2. 程序的结束
我们都知道 C 语言程序总是从 main 函数开始执行,但它是怎么结束的呢?程序结束其实就是进程终止,进程终止的方式通常有多种,大体上分为正常终止和异常终止。
前边的三种较为常见,后边两种暂时还未使用过,也还未见过。
(1) main() 函数中通过 return 语句返回来终止进程。
(2)程序中调用 exit() 函数终止进程。
(3)程序中调用 _exit() 或 _Exit() 终止进程。
(4)最后一个线程从其启动例程返回。
(5)最后一个线程调用 pthread_exit 。
(1)应用程序中调用 abort() 函数终止进程。
(2)进程接收到一个信号,譬如 SIGKILL 信号。
(3)最后一个线程对取消请求做出响应。
3. 几个函数
3.1 abort()
3.1.1 函数说明
在 linux 下可以使用 man abort 命令查看该函数的帮助手册。
1 |
|
【函数说明】该函数使程序异常终止,会直接从调用的地方跳出。
【函数参数】 none
【返回值】 none
【注意事项】
(1)函数首先解除 SIGABRT 信号的阻塞,然后为调用进程发出该信号,就像调用了 raise (后边会学习到),这将导致进程异常终止,除非捕获 SIGABRT 信号并且信号处理程序不返回。
(2)使用 abort() 终止进程运行,会生成核心转储文件,可用于判断程序调用 abort() 时的程序状态。
3.1.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会显示以下信息:
1 | before abort! |
3.2 atexit()
3.2.1 函数说明
在 linux 下可以使用 man atexit 命令查看该函数的帮助手册。
1 |
|
【函数说明】该函数会在程序正常终止时,调用指定的函数 function ,该函数也可以被称之为登记函数。
【函数参数】
- function :在程序终止时被调用的函数。
点击查看参数解读
- *function 表示定义了一个指针变量 function ;
- 后边的括号中的 void 表示这个指针变量可以指向一个没有参数的函数;
- 前边的 void 表示这个指针变量可以指向返回值类型为 void 的函数。
总的来说,就是定义了一个指向无形参无返回值的函数的指针变量 function ,它可以指向符合条件的函数。
【返回值】如果函数成功注册,则该函数返回 0 ,否则返回一个非 0 值。
【注意事项】
(1)我们可以在任何地方注册终止函数,它会在程序终止的时候被调用。
(2)后注册的函数在程序正常结束时将会被先调用。
(3)如果⼀个函数被多次注册,也会被多次调用。
(4)此函数可以用于注册一些清理工作的函数,例如清理内存等。
3.2.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会显示以下信息:
1 | before atexit! |
3.3 sleep()
3.3.1 函数说明
在 linux 下可以使用 man 3 sleep 命令查看该函数的帮助手册。
1 |
|
【函数说明】该函数会使进程休眠,此时该进程不占用 CPU 资源。
【函数参数】
- seconds : unsigned int 类型,程序休眠的时间,以 s (秒)为单位。
【返回值】返回值为 unsigned int 类型,若进程或者线程挂起到参数所指定的时间则返回 0 ,若有信号中断则返回剩余秒数。
【注意事项】 none
3.3.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会每隔 1s 输出一次 i 的值:
1 | i = 0! |
3.4 usleep()
3.4.1 函数说明
在 linux 下可以使用 man 3 usleep 命令查看该函数的帮助手册。
1 |
|
【函数说明】该函数会使进程休眠,此时该进程不占用 CPU 资源。
【函数参数】
- usec : useconds_t 类型,程序休眠的时间,以 us (微秒)为单位。
【返回值】返回值为 int 类型,若进程或者线程挂起到参数所指定的时间则返回 0 ,若有信号中断则返回剩余秒数。
【注意事项】 1s = 1000ms = 1000 000us
3.4.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会每隔 2s 输出一次 i 的值:
1 | i = 0! |
4. 常用 Shell 命令
这一部分可以查看前边学习shell的时候的相关命令
二、进程的ID
1. 进程ID
在维基百科中是这样说的:在计算机领域,进程标识符(英语:process identifier,又略称为进程ID(英语:process ID)、PID)是大多数操作系统的内核用于唯一标识进程的一个数值。这一数值可以作为许多函数调用的参数,以使调整进程优先级、杀死进程之类的进程控制行为成为可能。
2. 获取进程ID
2.1 getpid()
2.1.1 函数说明
在 linux 下可以使用 man getpid 命令查看该函数的帮助手册。
1 |
|
【函数说明】该函数会获取当前进程的进程号,也就是进程的 PID 。
【函数参数】 none
【返回值】返回值为 pid_t 类型,表示当前进程的进程号。
【注意事项】 none
2.1.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会显示以下信息:
1 | This process PID: 3877 |
每次运行获得的 PID 可能会不同。
2.2 getppid()
2.2.1 函数说明
在 linux 下可以使用 man getppid 命令查看该函数的帮助手册。
1 |
|
【函数说明】该函数会获取当前进程父进程的进程号。
【函数参数】 none
【返回值】返回值为 pid_t 类型,表示当前进程父进程的进程号。
【注意事项】 none
2.2.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会显示以下信息:
1 | This process's father PID: 1813 |
每次运行获得的 PID 可能会不同。
三、进程的环境变量
每一个进程都有一组与其相关的环境变量,这些环境变量以字符串形式存储在一个字符串数组列表中,把这个数组称为环境列表。每个字符串都是以名称 = 值( name=value )形式定义。
1. shell 命令
1 | env # 查看shell进程的所有环境变量 |
2. 环境变量作用
环境变量常见的用途之一是在 shell 中,每一个环境变量都有它所表示的含义,例如 HOME 环境变量表示用户的家目录, USER 环境变量表示当前用户名, SHELL 环境变量表示 shell 解析器名称, PWD 环境变量表示当前所在目录等,在自己的应用程序当中,也可以使用进程的环境变量。
3. 获取环境变量
3.1 environ
3.1.1 变量说明
在程序当中也可以获取当前进程的环境变量,进程的环境变量是从其父进程中继承过来的,例如在 shell 终端下执行一个应用程序,那么该进程的环境变量就是从其父进程( shell 进程)中继承过来的。
环境变量存放在一个字符串数组中,在应用程序中,通过 environ 变量指向它, environ 是一个全局变量,在我们的程序中只需申明它就使用.
1 | extern char **environ; /* 声明外部全局变量environ */ |
3.1.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会显示以下信息:
1 | SHELL=/bin/bash |
3.2 getenv()
3.2.1 函数说明
在 linux 下可以使用 man getenv 命令查看该函数的帮助手册。
1 |
|
【函数说明】该函数会获取指定的环境变量。
【函数参数】
- name :字符指针类型,指向指定要获取的 name=value 形式的字符串的 name 。
【返回值】返回值为 char * 类型,如果存在环境变量,则返回该环境变量的值对应字符串的指针;如果不存在,则返回 NULL 。
【注意事项】 none
3.2.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会显示以下信息:
1 | /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/snap/bin:/usr/local/arm/gcc-linaro-4.9.4-2017.01-x86_64_arm-linux-gnueabihf/bin |
4. 清空环境变量
4.1 environ 置 NULL
可以通过将全局变量 environ 赋值为 NULL 来清空所有变量。
1 | extern char **environ; /* 声明外部全局变量environ */ |
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会显示以下信息:
1 | SHELL=/bin/bash |
4.2 clearenv()
4.2.1 函数说明
在 linux 下可以使用 man clearenv 命令查看该函数的帮助手册。
1 |
|
【函数说明】该函数会清除所有环境表中的变量。
【函数参数】 none
【返回值】返回值为 int 类型,清空成功返回 0 ,否则返回 -1 。
【注意事项】只能影响到操作进程和子进程,对其父进程没有影响。
4.2.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会显示以下信息:
1 | SHELL=/bin/bash |
5. 增删改
5.1 putenv()
5.1.1 函数说明
在 linux 下可以使用 man putenv 命令查看该函数的帮助手册。
1 |
|
【函数说明】该函数会向当前进程的环境变量数组中添加一个新的环境变量,或者修改一个已经存在的环境变量对应的值。
【函数参数】
- string :字符指针类型,指向 name=value 形式的字符串。
【返回值】返回值为 int 类型,成功返回 0 ;失败将返回非 0 值,并设置 errno 。
【注意事项】
(1)该函数调用成功之后,参数 string 所指向的字符串就成为了进程环境变量的一部分了,也就是说 putenv() 函数将设定 environ 变量(字符串数组)中的某个元素(字符串指针)指向该 string 字符串,而不是指向它的复制副本。因此不能随意修改参数 string 所指向的内容,这将影响进程的环境变量,另外参数 string 不应为自动变量(即在栈中分配的字符数组)。
(2) putenv() 函数并不会为 name=value 字符串分配内存。
(3)只能影响到操作进程和子进程,对其父进程没有影响。
5.1.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会显示以下信息:
1 | SHELL=/bin/bash |
5.2 setenv()
5.2.1 函数说明
在 linux 下可以使用 man setenv 命令查看该函数的帮助手册
1 |
|
【函数说明】该函数用于向进程的环境变量列表中添加一个新的环境变量或修改现有环境变量对应的值。
【函数参数】
- name :字符指针类型,指向 name=value 形式的字符串中的名称 name 。
- value :字符指针类型,指向环境变量的值。
- overwrite :若参数 name 标识的环境变量已经存在,在参数 overwrite 为 0 时, setenv() 函数将不改变现有环境变量的值,如果参数 overwrite 的值为非 0 ,若参数 name 标识的环境变量已经存在,则覆盖这个环境变量,若不存在则表示添加新的环境变量。
【返回值】返回值为 int 类型,成功返回 0 ;失败将返回 -1 ,并设置 errno 。
【注意事项】
(1) setenv() 函数为形如 name=value 的字符串分配一块内存缓冲区,并将参数 name 和参数 value 所指向的字符串复制到此缓冲区中,以此来创建一个新的环境变量。
(2)此函数既可以用于添加环境变量,也可以用于修改环境变量,相对于 putenv() ,一般更推荐使用 setenv() 函数。
(3) setenv() 函数会为环境变量分配一块内存缓冲区,然后成为进程的一部分;而调用 clearenv() 函数来清空环境变量时没有释放该缓冲区( clearenv() 调用并不知晓该缓冲区的存在,故而也无法将其释放),反复调用者两个函数的程序,会不断产生内存泄漏。
(4)只能影响到操作进程和子进程,对其父进程没有影响。
5.2.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会显示以下信息:
1 | 12345 |
5.3 unsetenv()
5.3.1 函数说明
在 linux 下可以使用 man unsetenv 命令查看该函数的帮助手册。
1 |
|
【函数说明】该函数会从环境变量表中移除参数 name 标识的环境变量。
【函数参数】
- name :字符指针类型,指向 name=value 形式的字符串中的名称 name 。
【返回值】返回值为 int 类型,成功返回 0 ;失败将返回非 0 值,并设置 errno 。
【注意事项】只能影响到操作进程和子进程,对其父进程没有影响。
5.3.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会显示以下信息:
1 | 12345 |
5.4 直接添加
5.4.1 使用格式
还有一种方式,更为简单,可以直接在运行我们写的程序时添加环境变量:
1 | <NAME1=value1 NAME2=value2 ...> ./file_name |
即直接在执行程序的命令前添加环境变量,多个变量之间使用空格分隔开。
5.4.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
程序执行后,终端将会显示以下信息:
1 | FANHUA2=456 |
四、进程的内存布局
进程在内存中一种典型的布局方式大概包括以下部分:
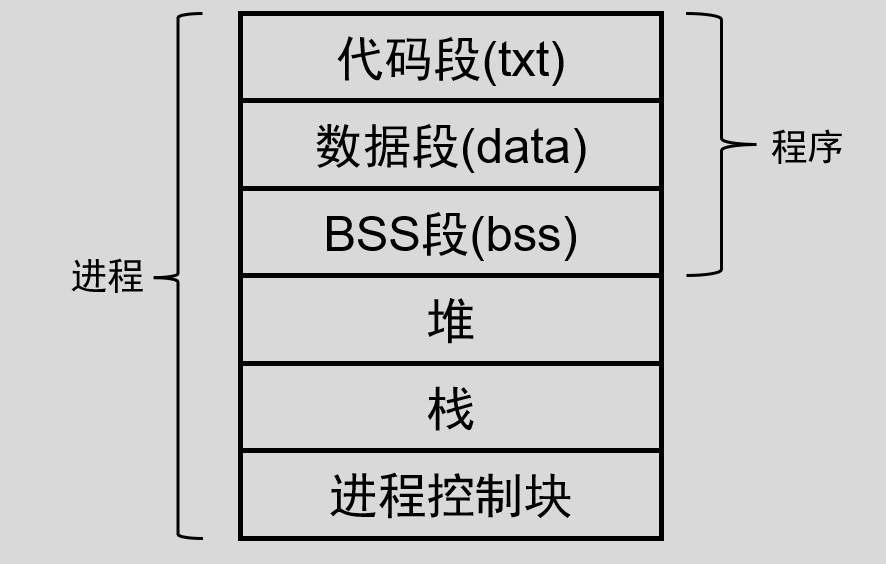
我们可以在终端使用 size file_name 命令来查看一个二进制可执行文件的代码段、数据段、 bss 段的段大小。
- 代码段
代码段通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。代码段具有只读属性,以防止程序由于意外而修改其指令,另外代码段是可以共享的,即使在多个进程间也可同时运行同一段程序。
- 数据段
数据段通常是指用来存放程序中已初始化的全局变量和静态变量的一块内存区域。当程序加载到内存中时,从可执行文件中读取这些变量的值。
- BSS 段
BSS(Block Started by Symbol) 段通常是指用来存放程序中未初始化的全局变量和静态变量的一块内存区域。在程序开始执行之前,系统会将本段内所有内存初始化为 0 ,可执行文件并没有为 bss 段变量分配存储空间,在可执行文件中只需记录 bss 段的位置及其所需大小,直到程序运行时,由加载器来分配这一段内存空间。
- 堆( heap )
堆是用于存放进程运行中被动态分配的内存段,当进程调用 malloc 等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用 free 等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
- 栈( stack )
栈又称堆栈, 是用户存放程序临时创建的局部变量,(但不包括 static 声明的变量, static 意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进后出特点,所以栈特别方便用来保存和恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
- 进程控制块
进程控制块( Processing Control Block ,简称 PCB ),也被称为任务控制块。是操作系统核心中一种数据结构,主要表示进程状态。它是进程管理和控制的最重要的数据结构,每一个进程都有一个 PCB ,在创建进程时,建立 PCB ,伴随进程运行的全过程,直到进程撤销而撤销。通常包含以下信息:
| 进程描述信息 | 进程标识符:标识各个进程,每个进程都有一个并且唯一的标识符; 用户标识符:进程归属的用户,用户标识符主要为共享和保护服务; |
| 进程控制和管理信息 | 进程当前状态,如 new、ready、running、waiting 或 blocked 等; 进程优先级:进程抢占 CPU 时的优先级; |
| 资源分配清单 | 有关内存地址空间或虚拟地址空间的信息,所打开文件的列表和所使用的 I/O 设备信息。 |
| CPU 相关信息 | CPU中各个寄存器的值,当进程被切换时,CPU 的状态信息都会被保存在相应的 PCB 中,以便进程重新执行时,能从断点处继续执行。 |
【说明】在 Linux 中, PCB 控制块的具体实现是 task_struct 结构体,但是我好像没找到这个结构体在哪😅,暂时就了解下好了。
五、进程的类型与状态
1. 进程的类型
根据进程的特点,可以分为以下三类:
- 交互进程
是由 shell 启动的进程,它既可以在前台运行,也可以在后台运行。交互进程在执行过程中,要求与用户进行交互操作。简单来说就是用户需要给出某些参数或者信息,进程才能继续执行。
- 批处理进程:
与 Windows 原来的批处理很类似,是一个进程序列。它和在终端无关,它会被提交到一个作业队列中以便顺序执行。
- 守护进程
是执行特定功能或者执行系统相关任务的后台进程。守护进程只是一个特殊的进程,不是内核的组成部分,也与终端无关。许多守护进程在系统启动时启动,直到系统关闭时才停止运行。而某些守护进程只是在需要时才会启动,比如 FTP 或者 Apache 服务等,可以在需要的时候才启动该服务。
2. 进程的状态
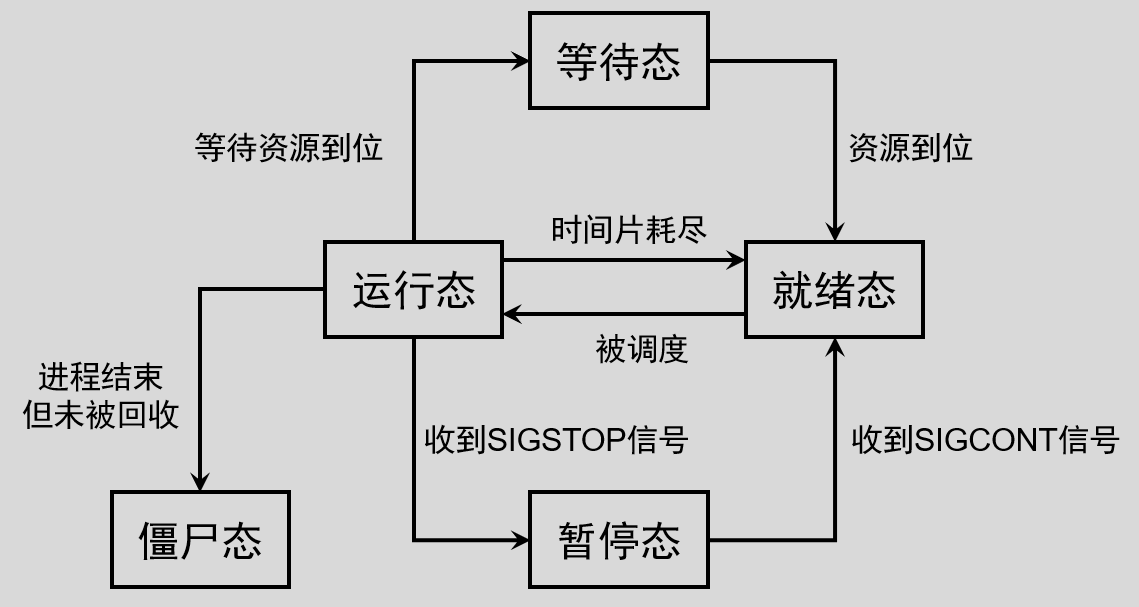
在 Linux 下,进程通常有六种状态:
| 就绪态(Ready) | R | 指该进程满足被CPU调度的所有条件但此时并没有被调度执行,只要得到CPU就能够直接运行;意味着该进程已经准备好被CPU执行,当一个进程的时间片到达,操作系统调度程序会从就绪态链表中调度一个进程 | |
| 运行态(Running) | R | 指该进程当前正在被CPU调度运行,处于就绪态的进程得到CPU调度就会进入运行态 | |
| 僵尸态 | Z | 僵尸态进程其实指的就是僵尸进程,指该进程已经结束、但其父进程还未给它"收尸" | |
| 等待态 | 可中断睡眠状态 | S | 可中断睡眠也称为浅度睡眠,表示睡的不够"死",还可以被唤醒,一般来说可以通过信号来唤醒 |
| 不可中断睡眠状态 | D | 不可中断睡眠称为深度睡眠,深度睡眠无法被信号唤醒,只能等待相应的条件成立才能结束睡眠状态。把浅度睡眠和深度睡眠统称为等待态(或者叫阻塞态),表示进程处于一种等待状态,等待某种条件成立之后便会进入到就绪态;所以,处于等待态的进程是无法参与进程系统调度的 | |
| 暂停态 | T | 暂停并不是进程的终止,表示进程暂停运行,一般可通过信号将进程暂停,譬如SIGSTOP信号;处于暂停态的进程是可以恢复进入到就绪态的,譬如收到SIGCONT信号 | |
(1)很多操作系统的资料会将正在 CPU 上执行的进程定义为 Running 状态、而将可执行但是尚未被调度执行的进程定义为 Ready 状态,这两种状态在 linux 下统一为 TASK_RUNNING 状态。
(2)进程在退出的过程中,处于 TASK_DEAD 状态。在这个退出过程中,进程占有的所有资源将被回收,除了 task_struct 结构(以及少数资源)以外。于是进程就只剩下 task_struct 这么个空壳,故称为僵尸。为啥要保留保留 task_struct 呢,是因为 task_struct 里面保存了进程的退出码、以及一些统计信息,而该进程的父进程很可能会关心这些信息。
(3)进程还有一种死亡状态 X ,也可以说是退出状态,我们使用 ps 命令时几乎不看不到有这样的进程。进程在退出过程中也可能不会保留它的 task_struct ,比如这个进程是多线程程序中被线程分离(后边学习)过的进程,或者父进程通过设置 SIGCHLD 信号的 handler 为 SIG_IGN ,显式的忽略了 SIGCHLD 信号。(这是 posix 的规定,尽管子进程的退出信号可以被设置为 SIGCHLD 以外的其他信号。)此时,进程将被置于 EXIT_DEAD 退出状态,这意味着接下来的代码立即就会将该进程彻底释放,所以 EXIT_DEAD 状态是非常短暂的,几乎不可能通过 ps 命令捕捉到。
(4)进程各状态之间的切换如下图所示:
六、进程的虚拟地址
在 Linux 系统中,采用了虚拟内存管理技术,事实上大多数现在操作系统都是这样的。 Linux 系统中,每一个进程都在自己独立的地址空间中运行,在 32 位系统中,每个进程的逻辑地址空间均为 4GB ,这 4GB 的内存空间按照 3:1 的比例进行分配,其中用户进程享有 3G 的空间,而内核独自享有剩下的 1G 空间

虚拟地址会通过硬件 MMU (内存管理单元)映射到实际的物理地址空间中,建立虚拟地址到物理地址的映射关系后,对虚拟地址的读写操作实际上就是对物理地址的读写操作, MMU 会将物理地址翻译为对应的物理地址,其关系如下所示:

在 Linux 系统下,应用程序运行在一个虚拟地址空间中,所以程序中读写的内存地址对应也是虚拟地址,并不是真正的物理地址,例如应用程序中读写 0x80800000 这个地址,实际上并不对应于硬件的 0x80800000 这个物理地址。
七、进程的上下文切换
各个进程之间是共享 CPU 资源的,在不同的时候进程之间需要切换,让不同的进程可以在 CPU 执行,那么这个一个进程切换到另一个进程运行,称为进程的上下文切换。
1. 什么是上下文切换?
大多数操作系统都是多任务的,通常支持大于 CPU 数量的任务同时运行。实际上,这些任务并不是同时运行的,只是因为系统在很短的时间内,让各个任务分别在 CPU 运行,于是就造成同时运行的错觉。
任务是交给 CPU 运行的,那么在每个任务运行前, CPU 需要知道任务从哪里加载,又从哪里开始运行。所以,操作系统需要事先帮 CPU 设置好 CPU 寄存器和程序计数器。 CPU 寄存器是 CPU 内部一个容量小,但是速度极快的内存(缓存)。程序计数器则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。所以说, CPU 寄存器和程序计数是 CPU 在运行任何任务前,所必须依赖的环境,这些环境就叫做 CPU 上下文。
那什么又是 CPU 上下文切换呢?
CPU 上下文切换就是先把前一个任务的 CPU 上下文( CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。系统内核会存储保持下来的上下文信息,当此任务再次被分配给 CPU 运行时, CPU 会重新加载这些上下文,这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
上面说到所谓的任务,主要包含进程、线程和中断。所以,可以根据任务的不同,把 CPU 上下文切换分成:进程上下文切换、线程上下文切换和中断上下文切换。
2. 上下文切换什么?
进程是由内核管理和调度的,所以进程的切换只能发生在内核态。进程是由内核管理和调度的,所以进程的切换只能发生在内核态。所以,进程的上下文切换不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源。
通常,会把交换的信息保存在进程的 PCB ,当要运行另外一个进程的时候,我们需要从这个进程的 PCB 取出上下文,然后恢复到 CPU 中,这使得这个进程可以继续执行,如下图所示:

进程的上下文开销是很关键的,我们希望它的开销越小越好,这样可以使得进程可以把更多时间花费在执行程序上,而不是耗费在上下文切换。
3. 什么场景会发生?
(1)为了保证所有进程可以得到公平调度, CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,进程就从运行状态变为就绪状态,系统从就绪队列选择另外一个进程运行;
(2)进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行;
(3)当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,也会重新调度;
(4)当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行;
(5)发生硬件中断时, CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序;