LV01-03-Cortex-A7架构-04-三级流水线
本文主要是Cortex-A7的三级流水线介绍的相关笔记,若笔记中有错误或者不合适的地方,欢迎批评指正😃。
点击查看使用工具及版本
| Windows版本 | windows11 |
| Ubuntu版本 | Ubuntu16.04的64位版本 |
| VMware® Workstation 16 Pro | 16.2.3 build-19376536 |
| 终端软件 | MobaXterm(Professional Edition v23.0 Build 5042 (license)) |
| Linux开发板 | 正点原子 i.MX6ULL Linux 阿尔法开发板 |
| uboot | NXP官方提供的uboot,NXP提供的版本为uboot-imx-rel_imx_4.1.15_2.1.0_ga(使用的uboot版本为U-Boot 2016.03) |
| linux内核 | linux-4.15(NXP官方提供) |
| Win32DiskImager | Win32DiskImager v1.0 |
点击查看本文参考资料
| 分类 | 网址 | 说明 |
| 官方网站 | https://www.arm.com/ | ARM官方网站,在这里我们可以找到Cotex-Mx以及ARMVx的一些文档 |
| https://www.nxp.com.cn/ | NXP官方网站 | |
| https://www.nxpic.org.cn/ | NXP 官方社区 | |
| https://u-boot.readthedocs.io/en/latest/ | u-boot官网 | |
| https://www.kernel.org/ | linux内核官网 |
点击查看相关文件下载
| 分类 | 网址 | 说明 |
| NXP | https://github.com/nxp-imx | NXP imx开发资源GitHub组织,里边会有u-boot和linux内核的仓库 |
| https://elixir.bootlin.com/linux/latest/source | 在线阅读linux kernel源码 | |
| nxp-imx/linux-imx/releases/tag/rel_imx_4.1.15_2.1.0_ga | NXP linux内核仓库tags中的rel_imx_4.1.15_2.1.0_ga | |
| nxp-imx/uboot-imx/releases/tag/rel_imx_4.1.15_2.1.0_ga | NXP u-boot仓库tags中的rel_imx_4.1.15_2.1.0_ga | |
| I.MX6ULL | i.MX 6ULL Applications Processors for Industrial Products | I.MX6ULL 芯片手册(datasheet,可以在线查看) |
| i.MX 6ULL Applications ProcessorReference Manual | I.MX6ULL 参考手册(下载后才能查看,需要登录NXP官网) | |
| ARM | Cortex-A7 MPCore Technical Reference Manual | Cortex-A7 MPCore技术参考手册 |
| ARM Architecture Reference Manual ARMv7-A and ARMv7-R edition | ARM架构参考手册ARMv7-A和ARMv7-R版 | |
| Arm Generic Interrupt Controller Architecture Specification- version 3 and version 4 | Arm通用中断控制器架构规范-版本3和版本4 | |
| ARM Generic Interrupt Controller Architecture Specification - Version 2.0 | Arm通用中断控制器架构规范-版本2.0 | |
| ARM Cortex-A Series Programmer's Guide for ARMv7-A | Cortex-A系列ARMv7-A编程指南 |
前边知道了PC的值 = 当前正在执行指令在内存中的地址 + 8 可是这是为什么呢?下边我们来简单了解一下。
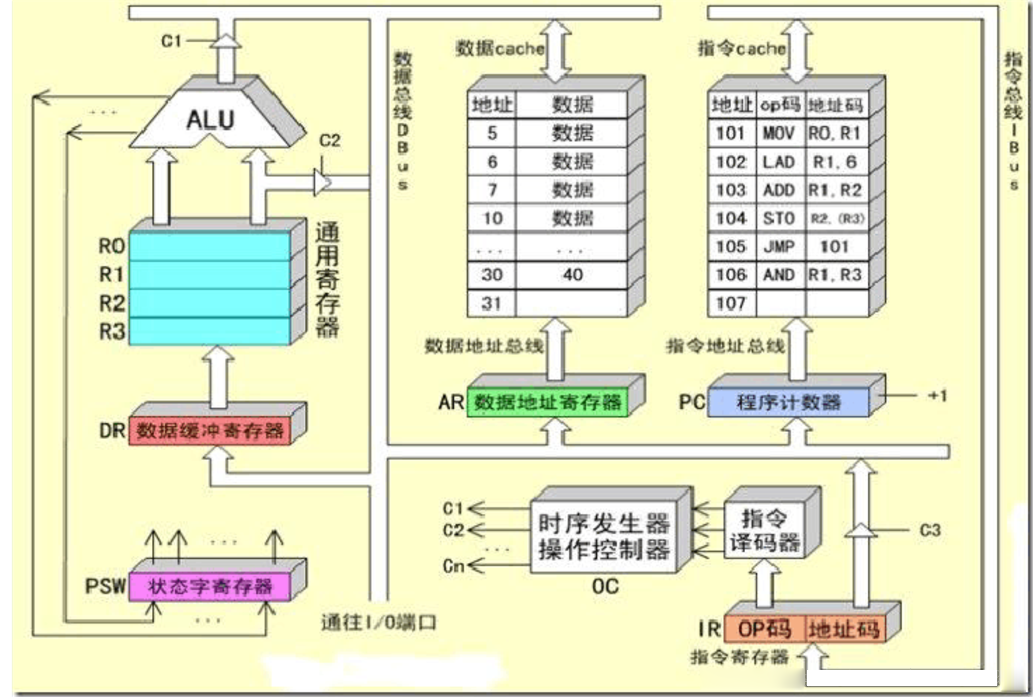
从上图中我们看到CPU内部有3个主要组成部分:指令寄存器,指令译码器,指令执行单元(包括ALU和通用寄存器组)。 CPU在执行1条指令的时候,主要有3个步骤:取指(将指令从内存或指令cache中取入指令寄存器);译码(指令译码器对指令寄存器中的指令进行译码操作,从而辨识出该指令是要执行add,或是sub,或是其它操作,从而产生各种时序控制信号);执行(指令执行单元根据译码的结果进行运算并保存结果) 。
现在我们假设一下:CPU串行执行程序(即:执行完1条指令后,再执行下一条指令);指令执行的3个步骤中每个步骤都耗时1秒;整个程序共10条指令。那么,这个程序总的执行时间是多少呢?显然,是30秒。但这个结果令我们非常不满意,因为它太慢了。有没有办法让它座上京津高铁提速3倍呢?当然有!仔细观察上图,我们发现:取指阶段占用的CPU硬件是指令通路和指令寄存器;译码阶段占用的CPU硬件是指令译码器;执行阶段占用的CPU硬件是指令执行单元和数据通路。三者占用的CPU硬件完全不同,这样就使得如下的操作得以进行:在对第1条指令进行译码的时候,可以同时对第2条指令进行取指操作;在对第1条指令进行执行的时候,可以同时对第2条指令进行译码操作,对第3条指令进行取指操作。显然,这样就可以将该程序的运行总时间从30秒缩减为12秒,提速近3倍。上面所述并行运行指令的方式就被称为流水线操作。可见:流水线操作的本质是利用指令运行的不同阶段使用的CPU硬件互不相同,并发的运行多条指令,从而提高时间效率。
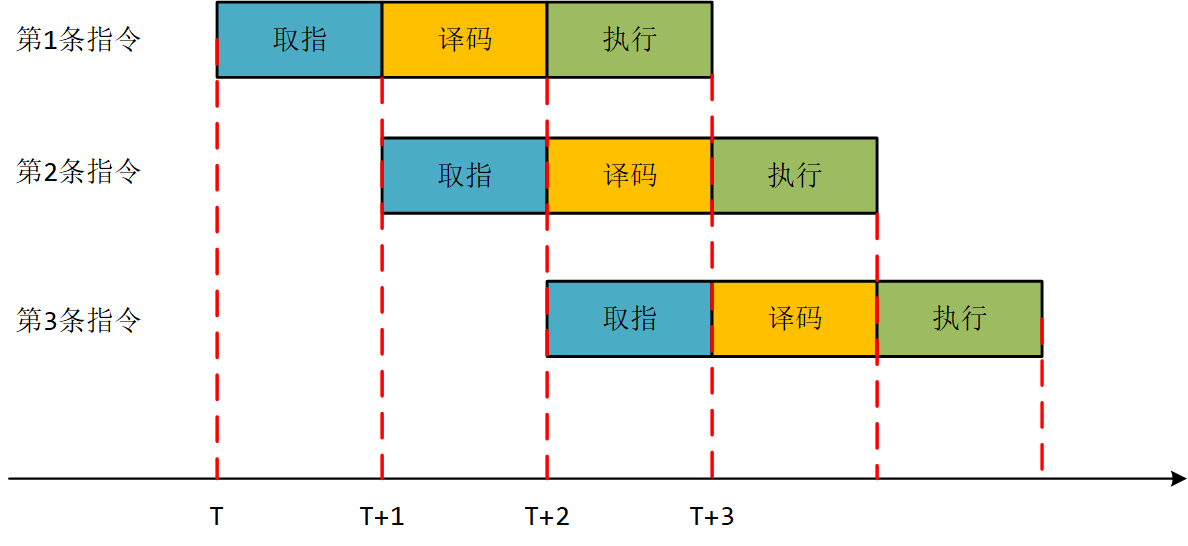
流水线的引入,的确提高了CPU运行指令的时间效率,但却为我们的汇编程序编写引入了新的问题。为什么这么说?
寄存器PC的值是即将被取指的指令的地址,正常情况下,在该条指令被取入CPU后执行期间,PC的值保持不变,在该条指令执行完成的时间点上,硬件会自动将PC的值增加一个单位的大小,这样PC就指向了下一条将被取指和执行的指令。而在引入流水线后,PC值的情况发生了变化,假定第1条指令的内存地址为X:
在时刻T,PC的值变为X,并在时刻T至时刻T+1期间维持不变;
在时刻T+1,PC的值变为X+1个单位,并在时刻T+1至时刻T+2期间维持不变;
在时刻T+2,PC的值变为X+2个单位,并在时刻T+2至时刻T+3期间维持不变;
在时刻T+3,PC的值将变为X+3个单位。
(PC的值为什么一直在增加,因为要保证流水线正常工作就得不停取指,每次取值PC值当然增加,对照上图理解)由此可见,在第1条指令的执行阶段,PC的值不再是该指令在内存中的位置,而是该指令在内存中的位置+2个单元。对于ARM指令集而言,每条指令的长度为32bit,占4byte,所以1条指令在内存中需要4byte存储。
因此,我们的结论是: 指令执行时, PC的值 = 当前正在执行指令在内存中的地址 + 8 。