LV04-01-文件操作-文件的相关概念
本文主要是C语言——文件相关笔记,若笔记中有错误或者不合适的地方,欢迎批评指正😃。
点击查看使用工具及版本
| Windows | windows11 |
| Ubuntu | Ubuntu16.04的64位版本 |
| VMware® Workstation 16 Pro | 16.2.3 build-19376536 |
| SecureCRT | Version 8.7.2 (x64 build 2214) - 正式版-2020年5月14日 |
| 开发板 | 正点原子 i.MX6ULL Linux阿尔法开发板 |
| uboot | NXP官方提供的uboot,NXP提供的版本为uboot-imx-rel_imx_4.1.15_2.1.0_ga(使用的uboot版本为U-Boot 2016.03) |
| linux内核 | linux-4.15(NXP官方提供) |
| STM32开发板 | 正点原子战舰V3(STM32F103ZET6) |
点击查看本文参考资料
| 参考方向 | 参考原文 |
| --- | --- |
一、一些基本概念
1. 文件
在操作系统中,为了统一对各种硬件的操作,简化接口,不同的硬件设备也都被看成一个文件,对这些文件的操作,等同于对磁盘上普通文件的操作。常见的硬件设备所对应的文件如下:
| 文件 | 硬件设备 |
| stdin | 标准输入文件,一般指键盘;scanf()、getchar() 等函数默认从 stdin 获取输入。 |
| stdout | 标准输出文件,一般指显示器;printf()、putchar() 等函数默认向 stdout 输出数据。 |
| stderr | 标准错误文件,一般指显示器;perror() 等函数默认向 stderr 输出数据(后续会讲到)。 |
| stdprn | 标准打印文件,一般指打印机。 |
2. 文件流
所有的文件(保存在磁盘)都要载入内存才能被处理,所有的数据必须写入文件(磁盘)才不会丢失,数据在文件和内存之间传递的过程叫做文件流。可以说,打开文件就是打开了一个流。
数据在数据源和程序(内存)之间传递的过程叫做数据流( Data Stream )。数据从数据源到程序(内存)的过程叫做输入流( Input Stream ),从程序(内存)到数据源的过程叫做输出流( Output Stream )。
3. 文件类型
文件也分有不同的类型,常见的如下:
| r | 常规文件 |
| d | 目录文件 |
| c | 字符设备文件 |
| b | 块设备文件 |
| p | 管道文件 |
| s | 套接字文件 |
| l | 符号链接文件 |
4. 文件描述符
在 Linux 系统中一切皆可以看成是文件,文件又可分为普通文件、目录文件、链接文件和设备文件等等。在操作文件的时候,我们每操作一次就找一次名字,这会耗费大量的时间和效率。所以 Linux 中规定每一个文件对应一个索引,这样要操作文件的时候,直接找到文件对应的索引就可以对其进行操作。
文件描述符( file descriptor )就是内核为了高效管理这些已经被打开的文件所创建的索引,文件描述符是一个非负整数。文件描述符从 0 开始分配,依次递增。例如,
| 标准输入流 | 0 | STDIN_FILENO | stdin |
| 标准输出流 | 1 | STDOUT_FILENO | stdout |
| 标准错误流 | 2 | STDERR_FILENO | stderr |
二、两种 I/O
1. 标准 I/O
1.1 简介
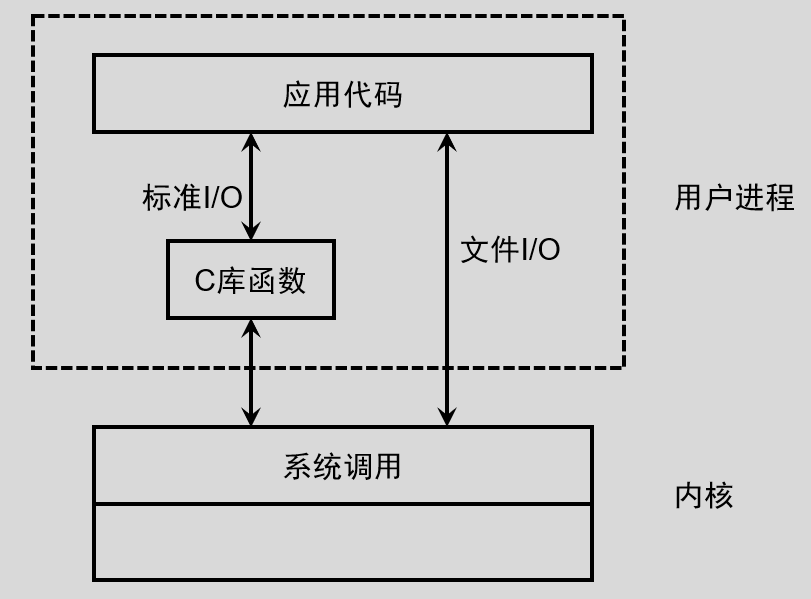
标准 I/O 由 ANSI C 标准定义的 I/O 模型,也叫高级磁盘 I/O ,采用库函数的方式对文件进行读写操作(对文件读写的函数接口出自于库),不依赖系统内核,所以移植性强。它遵循 ANSI C 相关标准。只要开发环境中有标准 I/O 库,标准 I/O 就可以使用。标准 I/O 通过缓冲机制减少系统调用,可以具有更高的效率。( Linux 中使用的是 glibc ,它是标准 C 库的超集,不仅包含 ANSI C 中定义的函数,还包括 POSIX 标准中定义的函数,因此, Linux 下既可以使用标准 I/O ,也可以使用文件 I/O )。
1.2 FILE 结构体
标准 I/O 用一个结构体类型来存放打开的文件的相关信息,标准 I/O 的所有操作都是围绕 FILE 来进行。 FILE 是 <stdio.h> 头文件中的一个结构体,它专门用来保存文件信息。
说实话,我找了 stdio.h 文件,似乎并没有发现这个结构体定义在哪里,即便是在 Linux 中使用 man 命令也没有找到它的定义,应该是有的,可能我没找到吧,于是在网上搜了下,其实都是大同小异的:
1 | struct _iobuf { |
1.3 流
文件经过打开后,相关信息存储在 FILE 定义的结构体中,它又被称为流( stream )。流可以分为文本流和二进制流,分别对应着文本文件和二进制文件。
点击查看文本文件和二进制文件
这两种其实并没有什么本质上的区别,只是对于换行符的处理不同。
C语言程序将 \n 作为换行符,类 UNIX/Linux 系统在处理文本文件时也将 \n 作为换行符,所以程序中的数据会原封不动地写入文本文件中,读取时也是这样的。
Windows 系统将 \r\n 作为文本文件的换行符,当读取文件时,程序会将文件中所有的 \r\n 转换成一个字符 \n 。如果文本文件中有连续的两个字符是 \r\n ,则程序会丢弃前面的 \r ,只读入 \n 。当写入文件时,程序会将 \n 转换成 \r\n 写入。即如果要写入的内容中有字符 \n ,则在写入该字符前,程序会自动先写入一个 \r 。
所以若是使用文本方式打开二进制文件进行读写,读写的内容就可能和文件的内容有出入。
| 流 | Windows | Linux |
| 二进制流 | \n | \n |
| 文本流 | \r\n | \n |
1.4 缓冲区
缓冲区( Buffer )又称为缓存( Cache ),是内存空间的一部分。也就是说,在内存中预留了一定的存储空间,用来暂时保存输入或输出的数据,这部分预留的空间就叫做缓冲区。
| 全缓冲 | 当流的缓冲区无数据或无空间时才执行实际I/O操作 |
| 行缓冲 | 当在输入和输出中遇到换行符(‘\n’)时,进行I/O操作。典型代表是标准输入(stdin)和标准输出(stdout)。 |
| 无缓冲 | 数据直接写入文件,流不进行缓冲 |
【注意】
(1) stdin 和 stdout 默认是行缓冲。
(2) stderr 没有缓冲。
1.5 缓冲区的刷新
系统怎么控制缓冲区呢?当我们从键盘输入数据的时候,我们并不会直接得到键盘输入的数据,这些数据是先放在了缓冲区中,然后我们再从缓冲区中得到我们想要的数据 。
如果我们通过 setbuf() 或 setvbuf() 函数将缓冲区设置 10 个字节的大小,而我们从键盘输入了 20 个字节大小的数据,这样我们输入的前 10 个数据会放在缓冲区中。那么剩下的那 10 个字节大小的数据会暂时存放在输入流中。
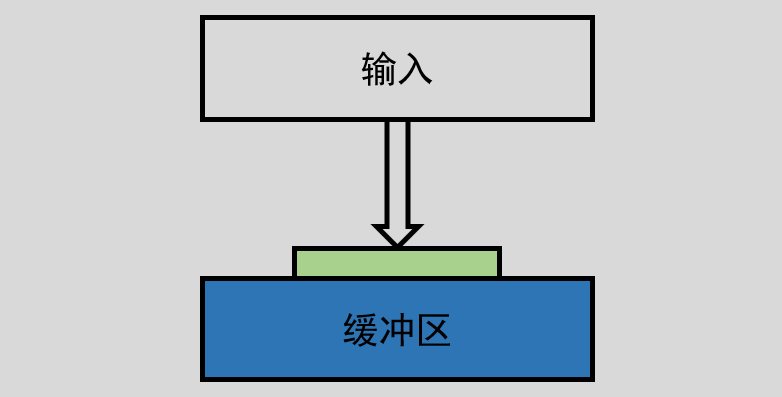
如上图所示,输入的地方相当于一个输入流,绿色部分相当于一个开关,蓝色部分为缓冲区,输入 20 个字节的数据只往缓冲区中放进去了 10 个字节,剩下的 10 个字节的数据就被停留在了输入流里。
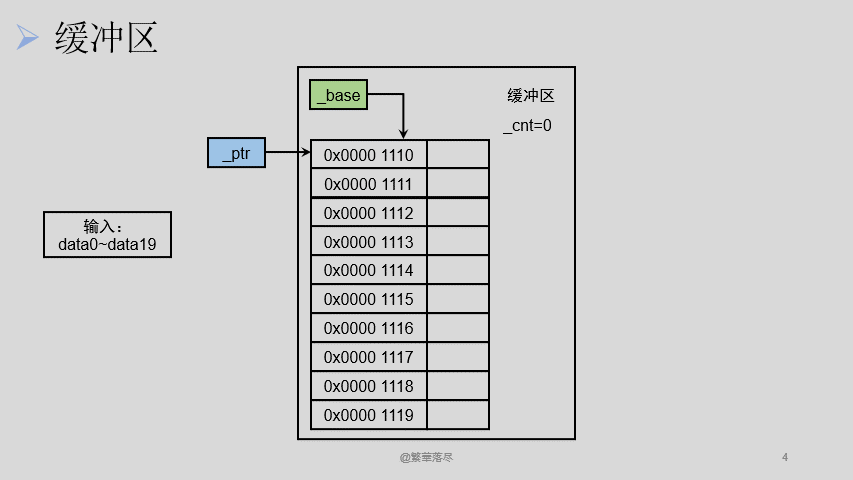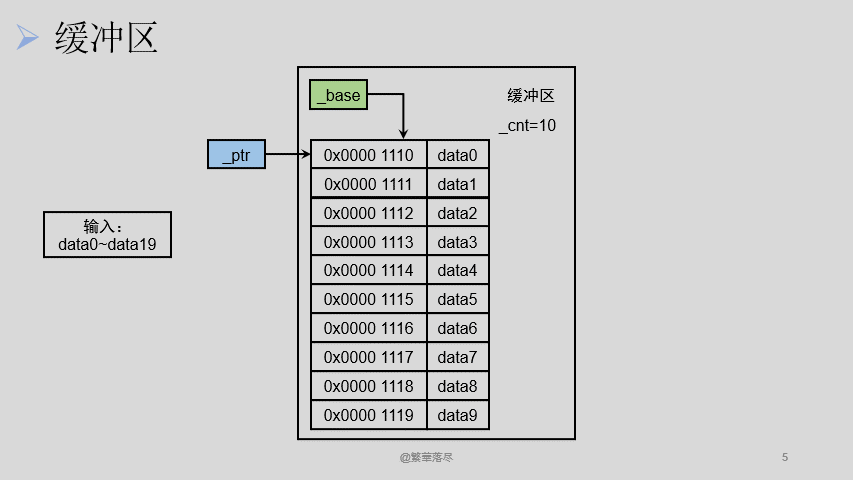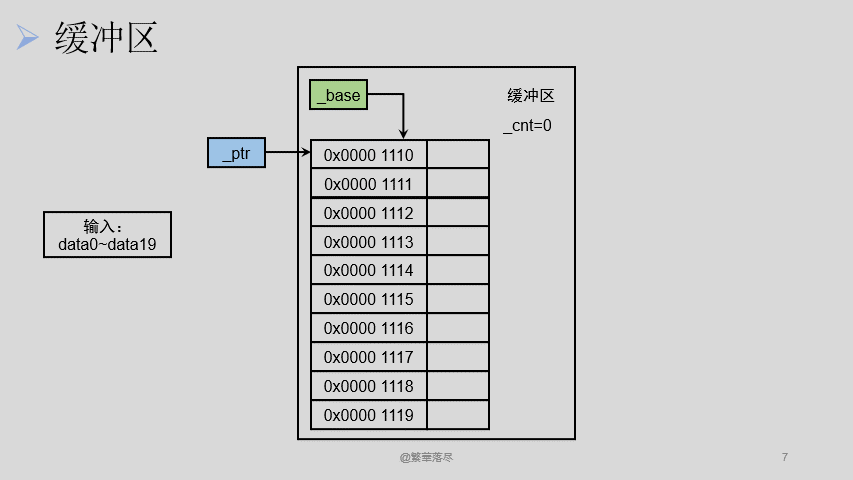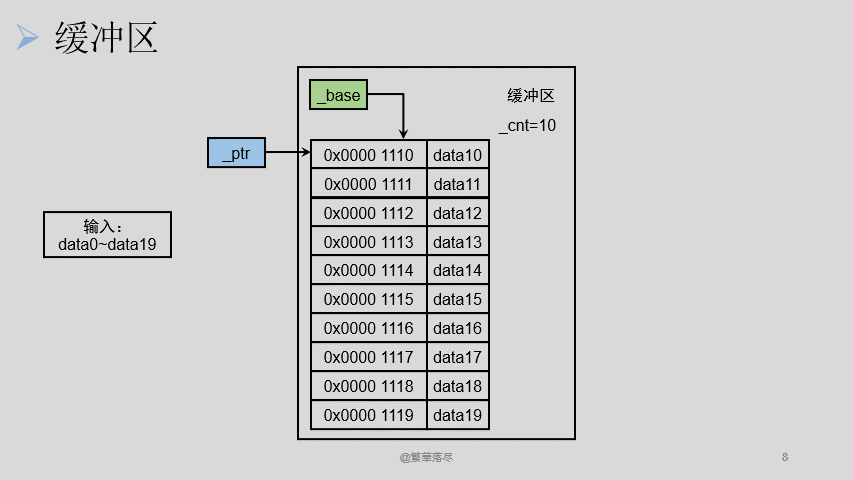
上边的 FILE 结构体中,有三个很关键的成员,分别是表示缓冲区剩余字符的成员 _cnt ,表示下一个要读取字符地址的成员 _ptr 还有一个是缓冲区基地址成员 _base 。
在上面我们向缓冲区中放入了 10 个字节大小的数据, FILE 结构体中的 _cnt 变为了 10 ,说明此时缓冲区中有 10 个字节大小的数据可以读,同时我们假设缓冲区的基地址也就是 _base 是 0x0000 1110 ,它是不变的 ,而此时 _ptr 的值也应该为 0x0000 1110 ,表示从 0x0000 1110 这个位置开始读取数据,当我们从缓冲区中读取 5 个数据的时候, _cnt 变为了 5 ,表示缓冲区还有 5 个数据可以读。 _ptr 则变为了 0x0000 1115 ,表示下次应该从这个位置开始读取缓冲区中的数据。
接下来我们再读取 5 个数据的时候, _cnt 则变为了 0 ,表示缓冲区中已经没有任何数据了, _ptr 应该变为了 0x0000 1120 ,表示下次应该从这个位置开始从缓冲区中读取数据,但是此时缓冲区中已经没有数据了,所以要将输入流中的剩下的那 10 个数据放进来,这样缓冲区中又有了 10 个数据,此时 _cnt 变为了 10 。注刚才 _ptr 的值应该为 0x0000 1120 ,而当缓冲区中重新放进来数据的时候需要重新从基地址开始读取,所以此时 _ptr 的值应该为 0x0000 1110 。
缓冲区的刷新就是将指针 _ptr 变为缓冲区的基地址 ,同时 _cnt 的值变为 0 ,当缓冲区刷新后,缓冲区是没有数据的。
【注意】当我们从键盘输入字符串的时候需要敲一下回车键才能够将这个字符串送入到缓冲区中,那么敲入的这个回车键( \r )会被转换为一个换行符 \n ,这个换行符 \n 也会被存储在缓冲区中并且被当成一个字符来计算。比如我们在键盘上敲下了 123 这个字符串,然后敲一下回车键( \r )将这个字符串送入了缓冲区中,那么此时缓冲区中的字节个数是 4 ,而不是 3 。
2. 文件 I/O
文件 I/O 即系统调用 I/O ,也称为不带缓冲的 I/O ( unbuffered I/O ),也就是一般所说的低级磁盘 I/O ,它不提供缓冲机制,每次读写操作都引起系统调用。它遵循 POSIX 相关标准,任何兼容 POSIX (可移植操作系统接口)标准的操作系统上都支持文件 I/O 。
3. 两种I/O的区别
- 缓冲区
标准 I/O 函数接口在对文件进行操作时,首先操作缓存区,等待缓存区满足一定的条件时,然后再去执行系统调用,真正实现对文件的操作。而文件 I/O 不操作任何缓存区,直接执行系统调用。
- 系统开销
执行系统调用时, Linux 必须从用户态切换到内核态,处理相应的请求,然后再返回到用户态。使用标准 I/O 接口,每调用一次函数写入字符,并不会立刻将字符写入文件,而是放到缓存区保存,之后每一次写入字符都放到缓存区保存,直到缓存区满足刷新的条件(如写满)时,再一并将缓存区中的数据写入文件,可以减少系统调用的次数,提高系统效率。而采用文件 I/O 的函数接口,每进行一次读或者写就会产生一次系统调用,频繁地执行系统调用自然会增加系统的开销。
4. 两种I/O基本函数
| 操作 | 标准I/O | 文件I/O(低级I/O) |
| 打开 | fopen,freopen,fdopen | open |
| 关闭 | fclose | close |
| 读取 | getc,fgetc,getchar,fgets,gets,fread | read |
| 写入 | putc,fputc,putchar,fputs,puts,fwrite | write |