LV18-01-LCD应用编程-07-字符的编码
本文主要是LCD应用编程——字符的编码的相关笔记,若笔记中有错误或者不合适的地方,欢迎批评指正😃。
点击查看使用工具及版本
| PC端开发环境 | Windows | Windows11 |
| Ubuntu | Ubuntu20.04.2的64位版本 | |
| VMware® Workstation 17 Pro | 17.6.0 build-24238078 | |
| 终端软件 | MobaXterm(Professional Edition v23.0 Build 5042 (license)) | |
| Win32DiskImager | Win32DiskImager v1.0 | |
| Linux开发板环境 | Linux开发板 | 正点原子 i.MX6ULL Linux 阿尔法开发板 |
| uboot | NXP官方提供的uboot,NXP提供的版本为uboot-imx-rel_imx_4.1.15_2.1.0_ga(使用的uboot版本为U-Boot 2016.03) | |
| linux内核 | linux-4.15(NXP官方提供) |
点击查看本文参考资料
| 分类 | 网址 | 说明 |
| 官方网站 | https://www.arm.com/ | ARM官方网站,在这里我们可以找到Cotex-Mx以及ARMVx的一些文档 |
| https://www.nxp.com.cn/ | NXP官方网站 | |
| https://www.nxpic.org.cn/ | NXP 官方社区 | |
| https://u-boot.readthedocs.io/en/latest/ | u-boot官网 | |
| https://www.kernel.org/ | linux内核官网 | |
| 其他网站 | kernel - Linux source code (v4.15) - Bootlin | linux内核源码在线查看 |
点击查看相关文件下载
| 分类 | 网址 | 说明 |
| NXP | https://github.com/nxp-imx | NXP imx开发资源GitHub组织,里边会有u-boot和linux内核的仓库 |
| https://elixir.bootlin.com/linux/latest/source | 在线阅读linux kernel源码 | |
| nxp-imx/linux-imx/releases/tag/rel_imx_4.1.15_2.1.0_ga | NXP linux内核仓库tags中的rel_imx_4.1.15_2.1.0_ga | |
| nxp-imx/uboot-imx/releases/tag/rel_imx_4.1.15_2.1.0_ga | NXP u-boot仓库tags中的rel_imx_4.1.15_2.1.0_ga | |
| I.MX6ULL | i.MX 6ULL Applications Processors for Industrial Products | I.MX6ULL 芯片手册(datasheet,可以在线查看) |
| i.MX 6ULL Applications ProcessorReference Manual | I.MX6ULL 参考手册(下载后才能查看,需要登录NXP官网) |
一、编码与字体
这一部分看这一篇笔记吧:《01嵌入式开发/01HQ课程体系/LV16-STM32开发/LV16-26-LCD-05-字符编码.md》
二、指定编码格式
在 C 源文件中要是有中文的话,这个中文的编码方式是 GB2312 还是 UTF-8?编译出的可执行程序,其中的汉字编码方式是 GB2312 还是 UTF-8?
注意:一般不会使用 UTF-16 的编码方式,在这种方式下 ASCII 字符也是用 2 字节来表示,而其中一个字节是 0,但是在 C 语言中 0 表示字符串的结束符,会引起误会。
我们编写 C 程序时,可以使用 ANSI 编码,或是 UTF-8 编码;在编译程序时,可以使用以下的选项告诉编译器:
1 | -finput-charset=GB2312 |
如果不指定“ -finput-charset”, GCC 就会默认 C 程序的编码方式为 UTF-8,即使我们是以 ANSI 格式保存,也会被当作 UTF-8 来对待。
对于编译出来的可执行程序,可以指定它里面的字符是以什么方式编码,可以使用以下的选项编译器:
1 | -fexec-charset=GB2312 |
如果不指定“ -fexec-charset”, GCC 就会默认编译出的可执行程序中字符的编码方式为 UTF-8。
如果“ -finput-charset”与“-fexec-charset”不一样,编译器会进行格式转换。
三、编码格式实验
1. 准备两个文件
我们准备两个文件,内容都是这样的:
1 |
|
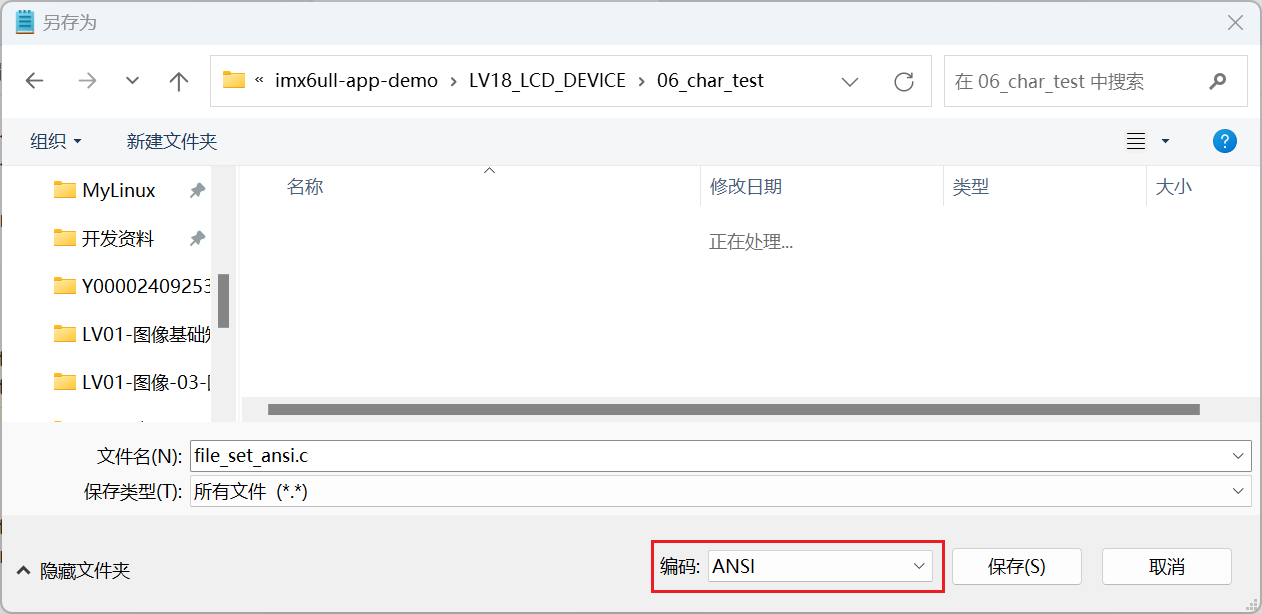
一个名为file_set_ansi.c,编码格式为ANSI:
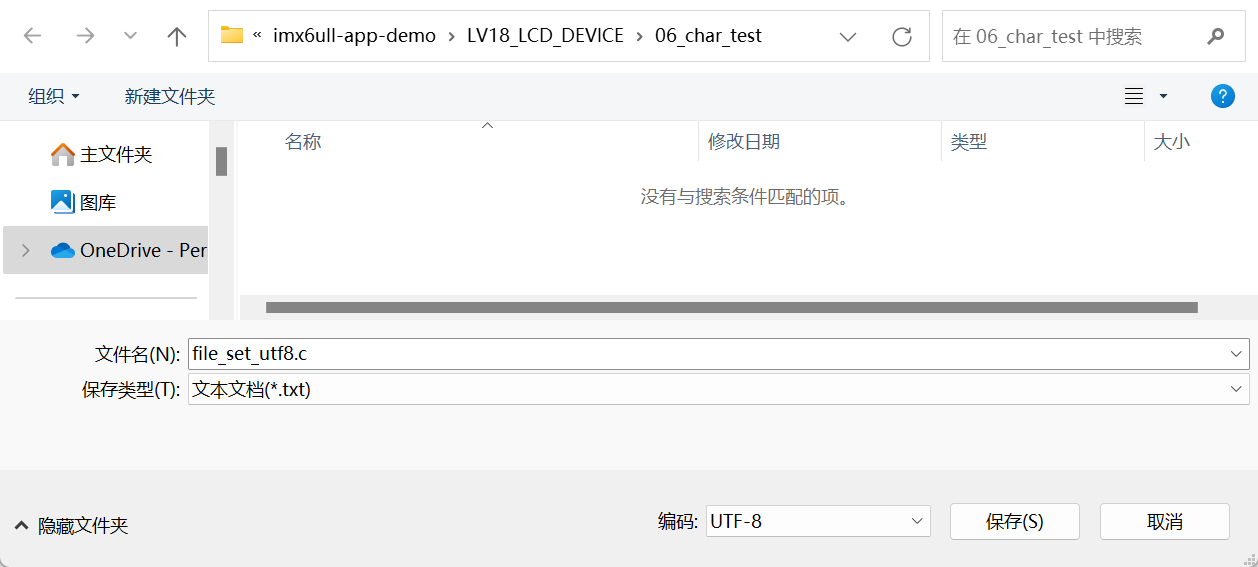
另一个命名为file_set_utf8.c:
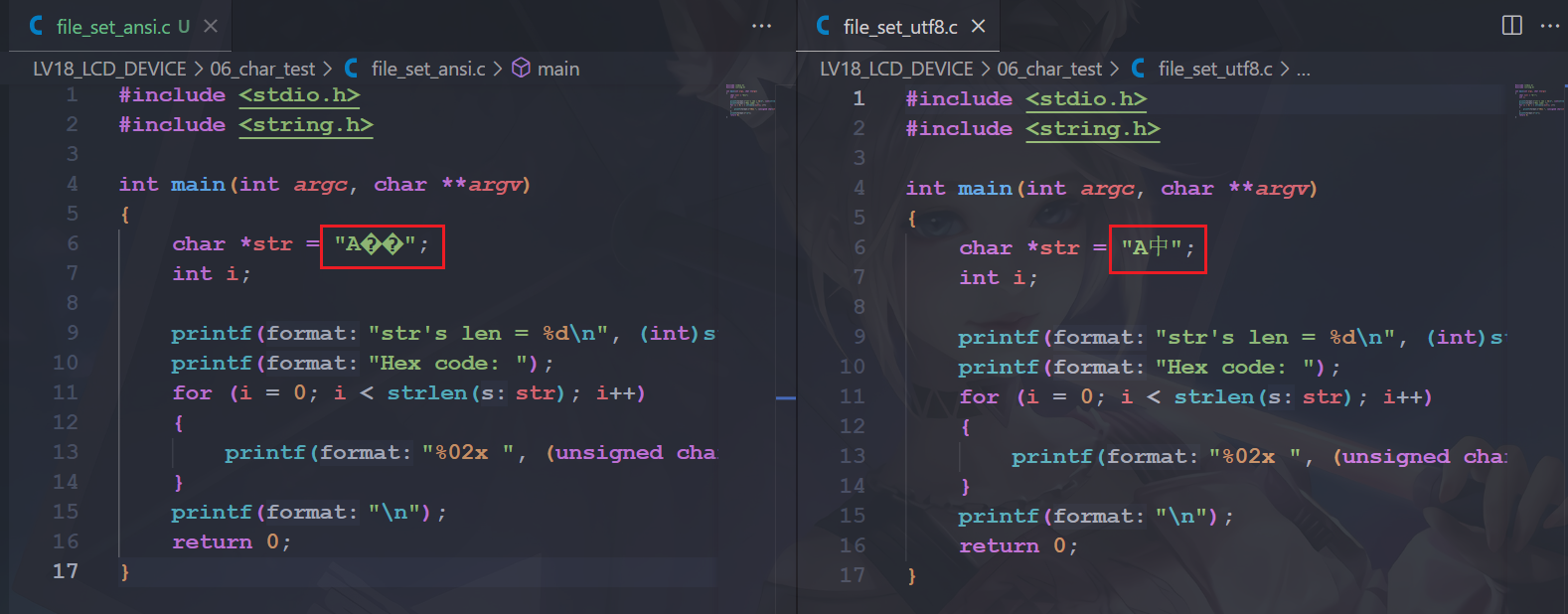
然后在VScode打开的时候是这样的:
2. 默认编码
我们不指定不指定“-finput-charset”与“ -fexec-charset”时, 编译上面两个文件并执行:
1 | gcc -o file_set_ansi file_set_ansi.c |

由于input-charset和 exec-charset 默认都是 UTF-8,不会进行编码转换。即使 C 文件是 ANSI,也会被认为是 UTF-8,所以不会导致编码转换。
3. GB2312 转为 UTF-8
1 | gcc -finput-charset=GB2312 -fexec-charset=UTF-8 -o file_set_ansi file_set_ansi.c |

从上面的输出信息可以看出来, GB2312 的“0xd6 0xd0”可以转换为 UTF-8的“ 0xe4 0xb8 0xad”。而如果把原本就是 UTF-8 格式的 file_set_utf8.c 当作 GB2312 格式,会引起错误。
4. UTF-8 转为 GB2312
1 | gcc -finput-charset=UTF-8 -fexec-charset=GB2312 -o file_set_ansi file_set_ansi.c |

从上面的输出信息可以看出来,如果把原本就是 GB2312 格式的file_set_ansi.c 当作 UTF-8 格式,会引起错误。而 UTF-8 格式的“中”编码值为“ 0xe4 0xb8 0xad”,可以转换为 GB2312 的“0xd6 0xd0”。在代码中使用汉字这类非 ASCII 码时,要特别留意编码格式。
四、C语言中的wchar_t类型
要显示一个字符,首先要确定它的编码值。常用的是 UNICODE 编码,在程序里使用这样的语句定义字符串时, str 中保存的要么是 GB2312 编码值,要么是UTF-8 格式的编码值,即使编译时使用“ -fexec-charset=UTF-8”, str 中保存的也不是直接能使用的 UNICODE 值:
1 | char *str = “中”; |
如果想在代码中能直接使用 UNICODE 值,需要使用 wchar_t,宽字符类型:
1 |
|
我们编译运行一下:
1 | gcc -o wchar wchar.c |

每个 wchar_t 占据 4 字节,可执行程序里 wchar_t 中保存的就是字符的 UNICODE值。
注意:如果 wchar.c 是以 ANSI(GB2312)格式保存,那么需要使用以下命令来编译:
1 | gcc -finput-charset=GB2312 -fexec-charset=UTF-8 -o wchar wchar.c |