LV05-03-Kernel-06-VFS-01-虚拟文件系统简介
本文主要是kernel——虚拟文件系统简介的相关笔记。若笔记中有错误或者不合适的地方,欢迎批评指正😃。
点击查看使用工具及版本
| PC端开发环境 | Windows | Windows11 |
| Ubuntu | Ubuntu20.04.2的64位版本 | |
| VMware® Workstation 17 Pro | 17.6.0 build-24238078 | |
| 终端软件 | MobaXterm(Professional Edition v23.0 Build 5042 (license)) | |
| Win32DiskImager | Win32DiskImager v1.0 | |
| Linux开发板环境 | Linux开发板 | 正点原子 i.MX6ULL Linux 阿尔法开发板 |
| uboot | NXP官方提供的uboot,使用的uboot版本为U-Boot 2019.04 | |
| linux内核 | linux-4.19.71(NXP官方提供) |
点击查看本文参考资料
| 分类 | 网址 | 说明 |
| 官方网站 | https://www.arm.com/ | ARM官方网站,在这里我们可以找到Cotex-Mx以及ARMVx的一些文档 |
| https://www.nxp.com.cn/ | NXP官方网站 | |
| https://www.nxpic.org.cn/ | NXP 官方社区 | |
| https://u-boot.readthedocs.io/en/latest/ | u-boot官网 | |
| https://www.kernel.org/ | linux内核官网 |
点击查看相关文件下载
| 分类 | 网址 | 说明 |
| NXP | https://github.com/nxp-imx | NXP imx开发资源GitHub组织,里边会有u-boot和linux内核的仓库 |
| nxp-imx/linux-imx/releases/tag/v4.19.71 | NXP linux内核仓库tags中的v4.19.71 | |
| nxp-imx/uboot-imx/releases/tag/rel_imx_4.19.35_1.1.0 | NXP u-boot仓库tags中的rel_imx_4.19.35_1.1.0 | |
| I.MX6ULL | i.MX 6ULL Applications Processors for Industrial Products | I.MX6ULL 芯片手册(datasheet,可以在线查看) |
| i.MX 6ULL Applications ProcessorReference Manual | I.MX6ULL 参考手册(下载后才能查看,需要登录NXP官网) | |
| Source Code | https://elixir.bootlin.com/linux/latest/source | linux kernel源码 |
| https://elixir.bootlin.com/u-boot/latest/source | uboot源码 |
一、文件系统
在《02IMX6ULL平台/LV06-驱动开发/LV06-01-驱动程序-01-驱动程序基础.md》中大概了解过文件系统,这里再深入了解一下。
1. 什么是文件系统
先来看看什么叫文件系统。直接查百度吧,操作系统中负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统。但其实维基百科的解释可能更为精准一些:File system:
1 | In computing, a file system or filesystem (often abbreviated to FS or fs) governs file organization and access. A local file system is a capability of an operating system that services the applications running on the same computer. A distributed file system is a protocol that provides file access between networked computers. |
这里就不翻译了,前面学习单片机的时候,肯定会接触到SPI FLASH、SD卡等存储介质,我们是可以将文件存放在这些存储设备上的,一开始的时候,我们将数据直接写入到某个地址中,然后读取的时候再从这个地址读出来,这已经很底层了。但是这是很麻烦的,需要很懂底层的原理才行,后来会接触到fatfs文件系统,这个系统其实就是一堆的api函数,需要我们实现一些对存储介质的初始化、读写相关操作,当我们移植完成后,它会代替我们完成对存储介质的操作,而我们只需要给出一个文件名,它就可以替我们找到这个文件在存储介质中的位置,而不是自己去记文件存放的地址,这对于不懂底层原理的开发者来说就很方便了。
所以其实文件系统是用于存储和组织文件的一种机制,便于对文件进行方便的查找与访问。文件系统是对文件存储设备的空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索的系统。它负责为用户建立文件,存入、读出、修改、转储文件,控制文件的存取,当用户不再使用时撤销文件等。
简单来说,文件系统是用来管理存储设备(storage devices,storage medium,比如机械硬盘HDD,SSD,磁带,光盘,SD卡等)上存储的数据的。
2. file system’s architecture
来啊看一下文件系统的结构,还是看File system,维基百科不一定能访问,这里贴一下原文:
1 | A local file system's architecture can be described as layers of abstraction even though a particular file system design may not actually separate the concepts.[7] |
翻译一下大概就是:
本地文件系统的体系结构可以被描述为抽象层,即使特定的文件系统设计实际上可能没有分离这些概念。
逻辑文件系统层通过应用程序编程接口(API)为文件操作提供相对高级的访问,包括打开、关闭、读和写——将操作委托给较低的层。这一层管理打开的文件表项和每个进程的文件描述符提供文件访问、目录操作、安全保护等功能。
虚拟文件系统是一个可选层,它支持物理文件系统的多个并发实例,每个实例称为一个文件系统实现。
物理文件系统层提供对存储设备(如磁盘)的相对低级的访问。它读取和写入数据块,提供缓冲和其他内存管理,并控制块在存储介质上特定位置的放置。该层使用设备驱动程序或通道I/O来驱动存储设备。
其实VFS这一层是可选的(optional,即不是必须的)。这个接口对多个并行的物理文件系统实例(每一个都叫做文件系统的实现)提供支持。意思是: 如果只有一个文件系统,那么我可以不要VFS,但是在有多个文件系统的时候,VFS就不可或缺了,其在中间起协调、管理作用。
有一个资料就是参考资料中的【7】The File System,是个PPT好像,对文件系统有一些说明,这里描述了文件系统的结构:File System Architecture
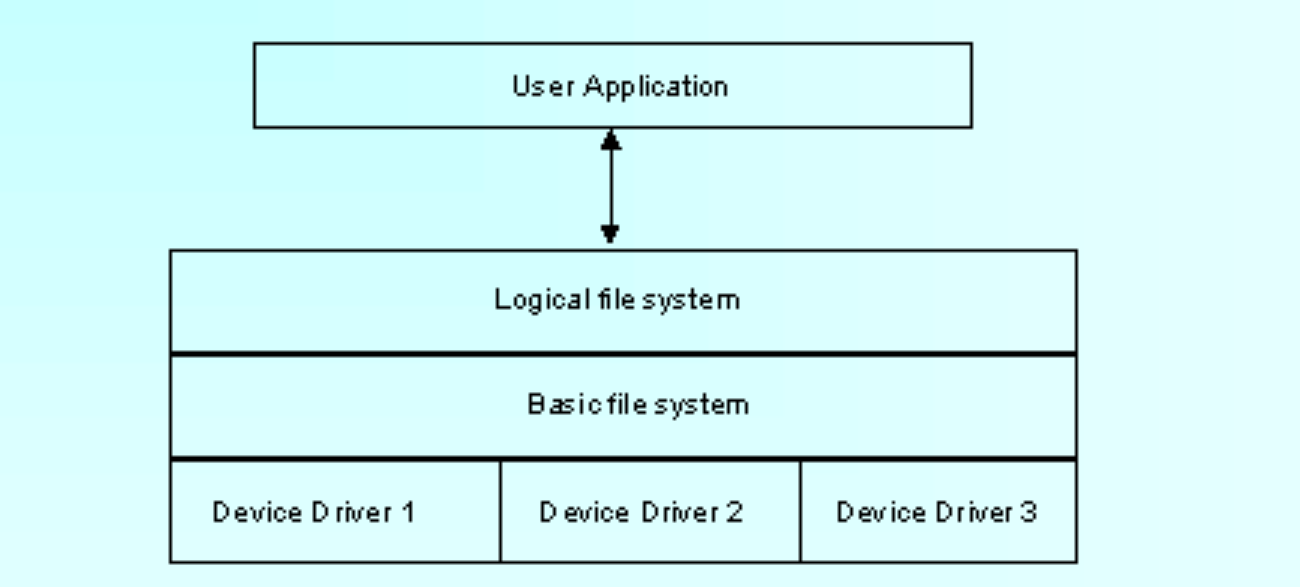
3. file system components
- Device Drivers
(1)直接与外围设备(磁盘、磁带等)通信。
(2)负责在设备上启动物理I/O操作。
(3)处理I/O请求的完成。
(4)安排对设备的访问以优化性能。
- Basic File System
(1)使用特定的设备驱动程序。
(2)处理与物理设备交换的数据块。
(3)与磁盘上块的位置有关。
(4)与主存中的缓冲块有关。
- Logical File System
负责向用户提供前面讨论的界面,包括:文件访问、目录操作、安全与保护。
4. 常见的文件系统
4.1 磁盘文件系统
磁盘文件系统是指本地主机中实际可以访问到的文件系统,包括硬盘、CD-ROM、DVD、USB存储器、磁盘阵列等。常见文件系统格式有:
- Ext系列:
(1)Ext:专门为Linux设计的第一个文件系统,最大支持2GB的容量。
(2)Ext2:由Rémy Card设计,用以代替Ext,最大支持32TB的容量,单个文件最大限制为2TB。
(3)Ext3:一种日志文件系统,最大支持32TB的容量,单个文件最大限制为16TB。
(4)Ext4:Theodore Tso领导的开发团队实现,是许多Linux发行版的默认文件系统,提供了良好的性能和可靠性。它支持大文件、大分区、文件压缩、在线碎片整理等特性。最大支持1EB的容量,单个文件最大限制也为16TB。
JFS:IBM开发的一种文件系统,用于大型数据库和文件服务器,支持文件系统级别的压缩。JFS2是一种字节级日志文件系统,主要是为满足服务器的高吞吐量和可靠性需求而设计、开发的。
XFS:由SGI开发,用于高性能的写入密集型应用,如数据库和文件服务器。XFS支持非常大的文件和卷,以及高并发操作,最大支持8 exbibytes的文件系统容量。
ReiserFS:一种性能优异的文件系统,特别是在小文件写入和大数量文件系统操作方面表现出色。
Btrfs:一种现代化的文件系统,支持高级特性,如数据完整性校验、快照、文件系统级压缩和写入时复制(COW)。
ZFS:由Sun Microsystems开发,以其数据完整性、可扩展性和性能而闻名。ZFS是一个复杂的文件系统,提供了类似RAID的数据保护特性。
FAT系列:
(1)FAT:一种较旧的文件系统,广泛用于USB闪存驱动器和移动存储设备。
(2)FAT16:采用16位的文件分配表,支持最大2GB的分区。
(3)FAT32:采用32位的文件分配表,突破了FAT16的容量限制,但运行速度相对较慢。
(4)VFAT:长文件名系统,与Windows系统兼容,支持长文件名。
NTFS:微软Windows的默认文件系统。Linux可以通过第三方驱动如ntfs-3g来读取和写入NTFS文件系统。
exFAT:专为闪存存储设计的文件系统,支持大于4GB的文件和大容量存储设备。Linux对exFAT的支持正在逐渐改善。
ISO9660:光盘的标准化文件系统,广泛用于数据CD和DVD。
UDF:通用磁盘格式,常用于光学介质和DVD视频。
4.2 网络文件系统
网络文件系统是可以远程访问的文件系统,这种文件系统在服务器端仍是本地的磁盘文件系统,客户机通过网络远程访问数据。常见文件系统格式有:
- NFS(Network File System):由Sun开发并发展起来的一项在不同机器、不同操作系统之间通过网络共享文件的技术。
- SMB/CIFS:由微软开发的网络文件系统协议,用于Windows和Linux之间的文件共享。
- AFP(Apple Filling Protocol):Apple文件归档协议,用于Mac和Linux之间的文件共享。
- WebDAV:基于HTTP协议的网络文件系统,允许用户通过Web浏览器访问和修改服务器上的文件。
4.3 专有/虚拟文件系统
专有/虚拟文件系统是不驻留在磁盘上的文件系统。常见格式有:
- TMPFS:基于内存的临时文件系统,通常用于存储临时文件。
- PROCFS(Process File System):进程文件系统,用于管理内存存储目录/proc,存储当前内核运行状态的一系列特殊文件。
- SYSFS:与PROCFS一样,也是基于内存的虚拟文件系统,用来管理内存存储目录/sysfs。
- LOOPBACKFS(Loopback File System):回送文件系统,允许用户将文件当作块设备来处理。
- SWAP:虽然不是传统意义上的文件系统,但swap空间在Linux中用于虚拟内存,允许系统在物理内存不足时使用磁盘空间作为临时存储。
4.4 linux中支持的文件系统
我们可以使用下面的命令查看当前linux系统支持的文件系统:
1 | cat /proc/filesystems |
/proc/filesystems 文件列出了当前内核支持的所有文件系统。
二、虚拟文件系统
前面其实已经提到了VFS,它其实就是虚拟文件系统,在学习linux的时候会接触到,下面来了解一下。
1. VFS是什么?
VFS,全称:Virtual File System,即虚拟文件系统,但是其还有一个称呼:virtual filesystem switch (它是维基百科的定义)。
虚拟文件系统是操作系统内核中的一种抽象层,它提供了一个统一的接口,使得不同的文件系统可以被操作系统内核一致地处理。VFS允许操作系统支持多种文件系统,而无需为每种文件系统编写特定的代码。通过VFS,操作系统可以透明地与各种文件系统交互,而无需关心底层文件系统的具体实现细节。
Tips:
A Virtual File System (VFS) or virtual filesystem switch is an abstract layer on top of a more concrete file system。
翻译一下就是:VFS是一个在更具体文件系统之上的抽象层。
需要知道的是VFS是一种软件机制,只存在于内存中,每次系统初始化期间Linux都会先在内存中构造一棵VFS的目录树(也就是源码中的namespace)。
2. 它有什么用?
其实前面解决VFS是什么问题的时候就大概可以知道了:
(1)使得用户应用能够访问不同类型的具体文件系统,比如,一个VFS能够用来访问一个本地或者网络存储设备且同时不需要让用户知道区别;
(2)VFS可以用来连接(brige)Windows,经典的Mac OS以及Unix文件系统,使得应用能够访问这些类型的本地文件系统上的文件,而不需要知道他们正在访问的是哪个文件系统;
(3)VFS明确了内核(kernel)和具体文件系统之间的接口(或者说契约contract),所以通过实现对应的契约,我们就能够很轻松的给内核添加对新文件系统的支持;
Tips:
其实有一个更贴切的描述:To ease the addition of new file systems and provide a generic file API, VFS, a virtual file system layer, was added to the Linux kernel. The extended file system (ext), was released in April 1992 as the first file system using the VFS API and was included in Linux version 0.96c.
上面这段可以在这里看到:Ext2 Linux File System | DiskInternals 或者在维基百科:ext2
3. 谁在使用VFS
(1)device drivers,设备驱动(可以看维基百科:Device driver)
(2)filesystems,文件系统
4. VFS和文件系统是什么关系?
前面了解文件系统结构的时候其实已经说明了: 如果只有一个文件系统,那么我可以不要VFS,但是在有多个文件系统的时候,VFS就不可或缺了,其在中间起协调、管理作用。
大概可以这么理解吧,就是不同的文件系统,它的实现方式可能多少有些区别,但是一个系统中存储介质可能使用的是不同的文件系统,比如硬盘1使用FAT32,硬盘2使用NTFS,那么他们的接口多少可能会有些区别,但是对于开发人员来说,还要去记这些区别就显得很麻烦,就相当于在文件系统上层又加了一层,将各个接口统一,这一层就是VFS了。
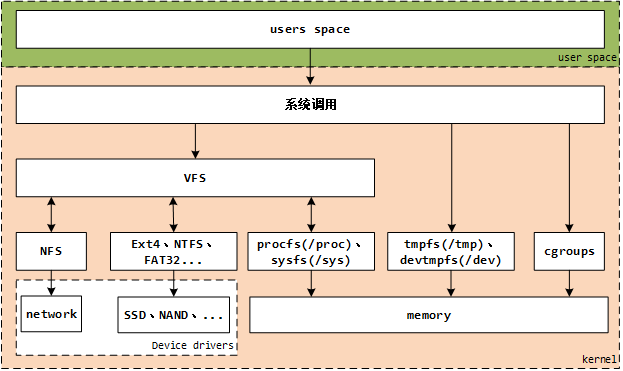
5. VFS在linux中的位置
虚拟文件系统在linux架构中位于哪里?
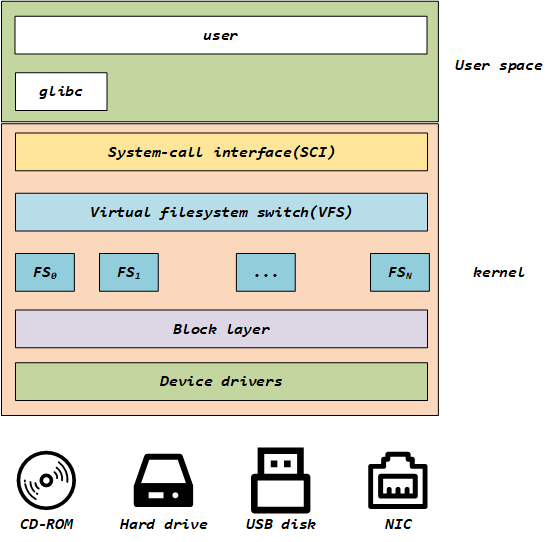
Linux系统的User使用GLIBC(POSIX标准、GUN C运行时库)作为应用程序的运行时库,然后通过操作系统,将其转换为系统调用SCI(system-call interface),SCI是操作系统内核定义的系统调用接口,这层抽象允许用户程序的 I/O 操作转换为内核的接口调用。VFS提供了一个抽象层,将POSIX API接口与不同存储设备的具体接口实现进行了分离,使得底层的文件系统类型、设备类型对上层应用程序透明。
6. 两个示例
6.1 接口适配示例
用户写入一个文件,使用 POSIX 标准的 write 接口,会被操作系统接管,转调 sys_write 这个系统调用(属于SCI层)。然后 VFS 层接受到这个调用,通过自身抽象的模型,转换为对给定文件系统、给定设备的操作,这一关键性的步骤是VFS的核心,需要有统一的模型,使得对任意支持的文件系统都能实现系统的功能。这就是VFS提供的统一的文件模型(common file model),底层具体的文件系统负责具体实现这种文件模型,负责完成POSIX API的功能,并最终实现对物理存储设备的操作。

VFS这一层建模和抽象是有必要的,如果放在SCI层会导致操作系统的系统调用的功能过于复杂,易出bug。那么就只能让底层文件系统都遵循统一实现,这对于已经出现的各种存储设备来说天然就有不同的特性,也是无法实现的。因此VFS这样一层抽象是有其必要性的。
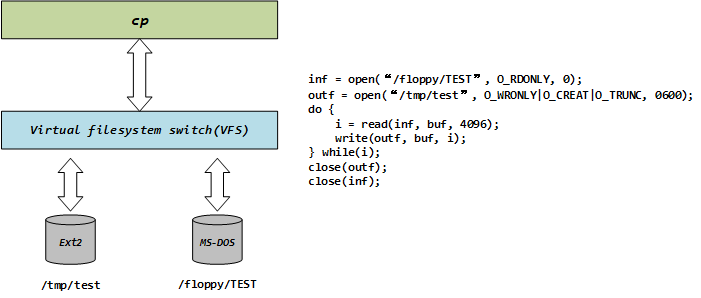
6.2 跨设备/文件系统示例
VFS为不同设备或文件系统间的访问提供了媒介,下面的示意图和代码中,用户通过cp命令进行文件的拷贝,对用户来说是不用关心底层是否跨越文件系统和设备的,具体都通过VFS抽象层实现对不同文件系统的读写操作。
三、VFS的构成
1. 统一文件模型
文件是存储在硬盘上的,硬盘的最小存储单位叫做扇区sector,每个扇区存储512字节。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个块block。这种由多个扇区组成的块,是文件存取的最小单位。块的大小,最常见的是4KB,即连续八个sector组成一个block。
文件数据存储在块中,那么还必须找到一个地方存储文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种存储文件元信息的区域就叫做inode,中文译名为索引节点,也叫i节点。
Tips:
元信息→inode
数据→ block
VFS为了提供对不同底层文件系统的统一接口,需要有一个高度的抽象和建模,这就是VFS的核心设计——统一文件模型。目前的Linux系统的VFS都是源于Unix家族,因此这里所说的VFS对所有Unix家族的系统都适用。Unix家族的VFS的文件模型定义了四种对象,这四种对象构建起了统一文件模型。
- superblock:存储文件系统基本的元数据。如文件系统类型、大小、状态,以及其他元数据相关的信息(元元数据)一个超级块对应一个文件系统(已经安装的文件系统类型如ext2,此处是实际的文件系统,不是VFS)。之前我们已经说了文件系统用于管理这些文件的数据格式和操作之类的,系统文件有系统文件自己的文件系统,同时对于不同的磁盘分区也有可以是不同的文件系统。
- index node(inode):保存一个文件相关的元数据。包括文件的所有者(用户、组)、访问时间、文件类型等,但不包括这个文件的名称。文件和目录均有具体的inode对应。
- directory entry(dentry):保存了文件(目录)名称和具体的inode的对应关系,用来粘合二者,同时可以实现目录与其包含的文件之间的映射关系。另外也作为缓存的对象,缓存最近最常访问的文件或目录,提示系统性能。
- file:一组逻辑上相关联的数据,被一个进程打开并关联使用。
统一文件模型是一个标准,各种具体文件系统的实现必须以此模型定义的各种概念来实现。
1.1 Superblock
静态:superblock保存了一个文件系统的最基础的元信息,一般都保存在底层存储设备的开头;
动态:挂载之后会读取文件系统的superblock并常驻内存,部分字段是动态创建时设置的。
superblock对应的结构体定义在 fs.h « linux « include - struct super_block
1.2 Index node
静态:创建文件系统时生成inode,保存在具体存储设备上,记录了文件系统的元信息;
动态:VFS在内存中使用inode数据结构,来管理文件系统的文件对象,记录了文件对象的详细信息,部分字段与关联的文件对象有关,会动态创建;
索引节点inode:保存的其实是实际的数据的一些信息,这些信息称为“元数据”(也就是对文件属性的描述)。例如:文件大小,设备标识符,用户标识符,用户组标识符,文件模式,扩展属性,文件读取或修改的时间戳,链接数量,指向存储该内容的磁盘区块的指针,文件分类等等。
Tips:数据分成:元数据+数据本身
注意:inode有两种,一种是VFS的 inode,一种是具体文件系统的inode。前者在内存中,后者在磁盘中。所以每次其实是将磁盘中的inode调进填充内存中的inode,这样才是算使用了磁盘文件inode。
inode怎样生成的?每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定(现代OS可以动态变化),一般每2KB就设置一个inode。一般文件系统中很少有文件小于2KB的,所以预定按照2KB分,一般inode是用不完的。所以inode在文件系统安装的时候会有一个默认数量,后期会根据实际的需要发生变化。
inode号:inode号是唯一的,表示不同的文件。其实在Linux内部的时候,访问文件都是通过inode号来进行的,所谓文件名仅仅是给用户容易使用的。当我们打开一个文件的时候,首先,系统找到这个文件名对应的inode号;然后,通过inode号,得到inode信息,最后,由inode找到文件数据所在的block,现在可以处理文件数据了。
inode和文件的关系:当创建一个文件的时候,就给文件分配了一个inode。一个inode只对应一个实际文件,一个文件也会只有一个inode。inodes最大数量就是文件的最大数量。
inode对应的结构体定义在 fs.h « linux « include - struct inode:
1 | struct inode { |
i_dentry字段指定当前inode标识的文件对象的名称,也就是dentry,是一个链表的,因为可能由多个dentry都指向这个inode(硬链接)。然后除了文件的一些权限信息、访问时间、大小等信息之外,最重要的就是记录了inode和file对象所提供的操作,分别是i_fop和i_op。
inode在内存中创建后会有inode cache进行缓存,并执行延迟的write back策略保存到底层存储设备。
1.3 Directory entry
目录项:目录项是描述文件的逻辑属性,只存在于内存中,并没有实际对应的磁盘上的描述,更确切的说是存在于内存的目录项缓存,为了提高查找性能而设计。注意不管是文件夹还是最终的文件,都是属于目录项,所有的目录项在一起构成一颗庞大的目录树。
dentry是用来记录具体的文件名与对应的inode间的对应关系的,同时可以用来实现硬链接、缓存、多级目录等树状文件系统的特性。VFS的dentry设计上就是为了实现整个文件系统树状层次结构的,每个文件系统拥有一个没有父dentry的根目录(root dentry),这个dentry会被superblock引用,用来作为进行树形结构的查找入口。其余的所有dentry都是有唯一的父dentry,并可以由若干个子dentry。示例:对于一个文件”/home/user/a”,会存在“/”、“home”、“user”、“a”四个dentry,依次构成父子关系,每个dentry也都有一个inode与之关联,存储了具体的数据。
dentry没有在磁盘等底层存储设备上存储,是一个动态创建的内存数据结构,主要是为了构建出树状组织结构而设计,用来进行文件、目录的查找。dentry创建之后会被操作系统进行缓存,目的是为了提升对文件系统进行操作的性能。
dentry的结构定义在 dcache.h « linux « include - struct dentry。
1 | struct dentry { |
其中最重要的有两个字段,一个是d_inode指针指向了当前dentry关联的inode。另一个就是d_op字段,指向了一系列dentry支持的操作的集合。
- dentry在需要使用时动态创建,并会被缓存。每个dentry有三种状态:
(1)used:与一个inode关联,正处于被VFS使用的状态,不能被损坏和丢弃
(2)unused:与inode关联,但处于被缓存状态,没有被VFS使用
(3)negative:没有与具体的inode关联(相当于是一个无效的路径)
- dentry由于会被动态创建,为了提升系统性能,设计了一个dentry cache进行缓存,包括三个部分:
(1)used dentries 链表:记录每个正在使用的dentry,将其关联的inode的i_dentry字段指向的dentry链表连接起来形成一个dentry链表的链表
(2)LRU双向环链表:用于维护unused和negative状态的dentry对象,从头部插入,离头部越近就是最近访问过的。当需要删除dentry时,从队列尾部删除最旧的dentry
(3)hash table和hash function:用来快速查询一个给定的路径到dentry对象
1.4 File
文件对象描述的是进程已经打开的文件。因为一个文件可以被多个进程打开,所以一个文件可以存在多个文件对象。但是由于文件是唯一的,那么inode就是唯一的,目录项也是定的!
进程其实是通过文件描述符来操作文件的,注意每个文件都有一个32位的数字来表示下一个读写的字节位置,这个数字叫做文件位置。一般情况下打开文件后,打开位置都是从0开始,除非一些特殊情况。Linux用file结构体来保存打开的文件的位置,所以file称为打开的文件描述。file结构形成一个双链表,称为系统打开文件表。
文件对象是打开一个具体文件之后创建的一个内存数据结构,与具体的进程和用户相联系。一个文件对象包括的内容就是编程语言支持设置的各种文件打开的flag、mode,文件名称、当前的偏移等,其中非常重要的一个字段就是f_op,指向了当前文件所支持的操作集合。
file结构体定义在fs.h « linux « include - struct file。
1.5 VFS抽象组件关系
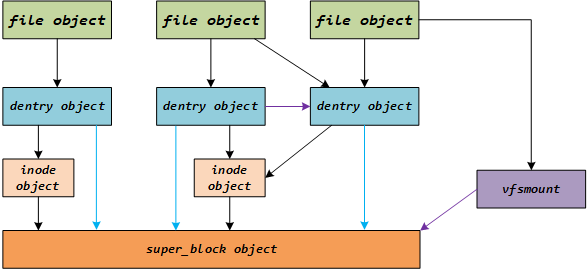
每个打开的文件对用户来说有一个文件描述符,也就是VFS抽象的file object。file object指向一个dentry,dentry指向新的dentry或一个inode,inode最终代表了一个具体存储设备上的数据。
2. VFS由什么构成?
上面已经了解了统一文件模型,现在再来看这个问题,大概就好理解一点了。这里主要参考的是这个文章【8】The Linux kernel: The Linux Virtual File System和【9】虚拟文件系统 |Linux 教程。
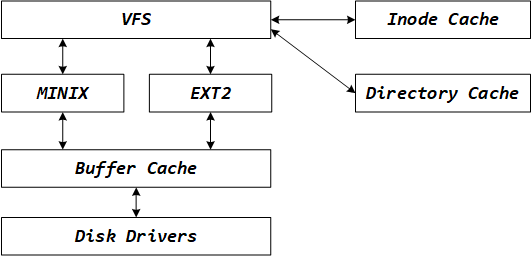
VFS用 superblocks 和 inodes 来描述系统文件(和EXT2的文件系统使用 superblocks,inodes非常相似)。其中 inodes 用来描述系统内的文件和目录。
每个文件系统在初始化的时候,它会用VFS注册它自己(我理解的是:每个真实文件系统挂载上来时,都会在VFS上登记备案 ),这通常发生在操作系统在系统引导(system boot time)时初始化它自己的过程。
【9】虚拟文件系统 |Linux 教程中有这么一段:
The real file systems are either built into the kernel itself or are built as loadable modules. File System modules are loaded as the system needs them, so, for example, if the VFAT file system is implemented as a kernel module, then it is only loaded when a VFAT file system is mounted. When a block device based file system is mounted, and this includes the root file system, the VFS must read its superblock. Each file system type’s superblock read routine must work out the file system’s topology and map that information onto a VFS superblock data structure. The VFS keeps a list of the mounted file systems in the system together with their VFS superblocks. Each VFS superblock contains information and pointers to routines that perform particular functions. So, for example, the superblock representing a mounted EXT2 file system contains a pointer to the EXT2 specific inode reading routine. This EXT2 inode read routine, like all of the file system specific inode read routines, fills out the fields in a VFS inode. Each VFS superblock contains a pointer to the first VFS inode on the file system. For the root file system, this is the inode that represents the “/“ directory. This mapping of information is very efficient for the EXT2 file system but moderately less so for other file systems.
这一段说的大概是:
(1)真实文件系统要么在内核中构建(意思就是直接装在内核里面成为一部分了),要么以可加载模块的方式被构建。文件系统模块只有在系统需要他们的时候,才会被加载。比如,VFAT 文件系统被实现成一个内核模块,只有当一个VFAT 文件系统被挂载的时候,它才会被加载。
(2)当一个基于块设备的文件系统被加载,且这包含根文件系统,VFS就必须读取它的superblocks(应该是叫超级块),每个文件系统类型的超级块read routine必须算出文件系统的拓扑结构,并且把这个信息映射到VFS的超级块数据结构中。
(3)VFS保持着一个在系统(意思就是操作系统)中被挂载文件系统的列表以及他们的VFS超级块。每个VFS超级块包含到routines(指令集 a list of instructions that enable a computer to perform a particular task)的信息和指针。
那上图的cache和directory cache又是什么呢?
【9】虚拟文件系统 |Linux 教程中有这么一段:
As the system’s processes access directories and files, system routines are called that traverse the VFS inodes in the system.
For example, typing ls for a directory or cat for a file cause the the Virtual File System to search through the VFS inodes that represent the file system. As every file and directory on the system is represented by a VFS inode, then a number of inodes will be being repeatedly accessed. These inodes are kept in the inode cache which makes access to them quicker. If an inode is not in the inode cache, then a file system specific routine must be called in order to read the appropriate inode. The action of reading the inode causes it to be put into the inode cache and further accesses to the inode keep it in the cache. The less used VFS inodes get removed from the cache.
All of the Linux file systems use a common buffer cache to cache data buffers from the underlying devices to help speed up access by all of the file systems to the physical devices holding the file systems.
This buffer cache is independent of the file systems and is integrated into the mechanisms that the Linux kernel uses to allocate and read and write data buffers. It has the distinct advantage of making the Linux file systems independent from the underlying media and from the device drivers that support them. All block structured devices register themselves with the Linux kernel and present a uniform, block based, usually asynchronous interface. Even relatively complex block devices such as SCSI devices do this. As the real file systems read data from the underlying physical disks, this results in requests to the block device drivers to read physical blocks from the device that they control. Integrated into this block device interface is the buffer cache. As blocks are read by the file systems they are saved in the global buffer cache shared by all of the file systems and the Linux kernel. Buffers within it are identified by their block number and a unique identifier for the device that read it. So, if the same data is needed often, it will be retrieved from the buffer cache rather than read from the disk, which would take somewhat longer. Some devices support read ahead where data blocks are speculatively read just in case they are needed.
The VFS also keeps a cache of directory lookups so that the inodes for frequently used directories can be quickly found.
As an experiment, try listing a directory that you have not listed recently. The first time you list it, you may notice a slight pause but the second time you list its contents the result is immediate. The directory cache does not store the inodes for the directories itself; these should be in the inode cache, the directory cache simply stores the mapping between the full directory names and their inode numbers.
大概就是再说:
(1)所有的linux文件系统都使用一个常用的buffer cache(缓冲区缓存)来缓存来自底层设备的data buffers,这样可以加速文件系统对保有这个文件系统的物理设备的访问。
(2)VFS也保有了一个文件夹查找(directory lookups)缓存(cache),以便经常被使用的文件夹的inodes能够被快速找到。(所以,通常在ls一个最近从没打开或者ls过的文件夹时,会有一点点停顿,但第二次就会立马显示结果。)
(3)文件夹缓存不存储针对文件夹本身的inodes(这些应该放在inodes 缓存中),它存储了整个文件夹名字和他们的inode号之间的映射。
(4)系统中的每个文件或者文件夹都是用一个VFS inode表示的,放在inode cache里面的inode会被更快的访问,如果某个inode不在cache中,那么一个文件系统的指定routine(指令集)就会被调用来读取对应的inode。读取这个inode使得它被放进缓存中,进一步的访问会将它保持在缓存中。此外,更少被用到的VFS inodes会从cache中移除。
参考资料
【1】linux-0.12/docs/第12章-文件系统/第12章-文件系统.md at master · sumumm/linux-0.12 · GitHub
【2】【Linux】VFS 虚拟文件系统 详解-CSDN博客
【4】[高级操作系统] VFS详解(虚拟文件系统)_操作系统vfs层-CSDN博客
【5】Linux文件系统1—概述 - jasonactions - 博客园
【6】Linux文件系统2—VFS的四个主要对象_vfs主要由哪几种类型的对象组成-CSDN博客
【8】The Linux kernel: The Linux Virtual File System