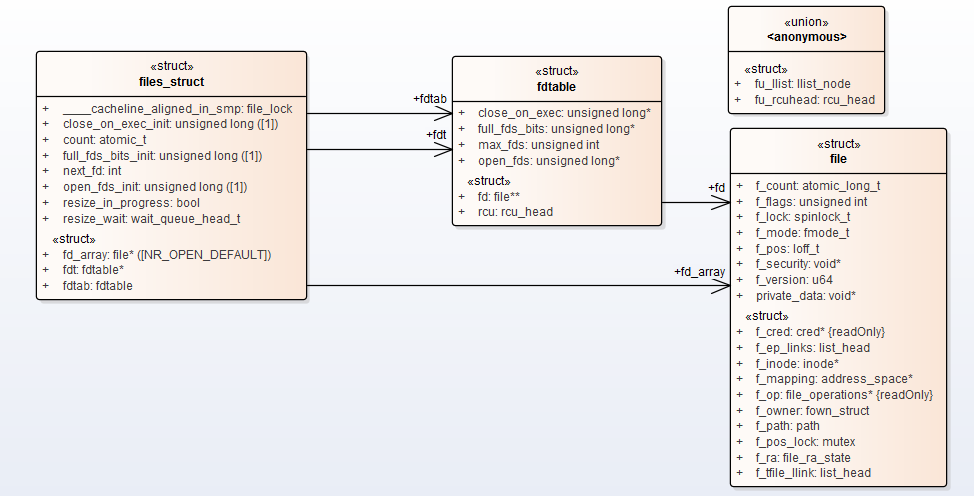
structfdtable __rcu *fdt; structfdtablefdtab; /* * written part on a separate cache line in SMP */ spinlock_t file_lock ____cacheline_aligned_in_smp; unsignedint next_fd; unsignedlong close_on_exec_init[1]; unsignedlong open_fds_init[1]; unsignedlong full_fds_bits_init[1]; structfile __rcu * fd_array[NR_OPEN_DEFAULT]; };
structfile { union { structllist_nodefu_llist; structrcu_headfu_rcuhead; } f_u; structpathf_path; structinode *f_inode;/* cached value */ conststructfile_operations *f_op;
/* * Protects f_ep_links, f_flags. * Must not be taken from IRQ context. */ spinlock_t f_lock; enumrw_hintf_write_hint; atomic_long_t f_count; unsignedint f_flags; fmode_t f_mode; structmutexf_pos_lock; loff_t f_pos; structfown_structf_owner; conststructcred *f_cred; structfile_ra_statef_ra;
u64 f_version; #ifdef CONFIG_SECURITY void *f_security; #endif /* needed for tty driver, and maybe others */ void *private_data;
#ifdef CONFIG_EPOLL /* Used by fs/eventpoll.c to link all the hooks to this file */ structlist_headf_ep_links; structlist_headf_tfile_llink; #endif/* #ifdef CONFIG_EPOLL */ structaddress_space *f_mapping; errseq_t f_wb_err; } __randomize_layout __attribute__((aligned(4))); /* lest something weird decides that 2 is OK */
/* * Purpose : Find next 'zero' bit * Prototype: int find_next_zero_bit(void *addr, unsigned int maxbit, int offset) */ ENTRY(_find_next_zero_bit_le) teq r1, #0 beq 3b ands ip, r2, #7 beq 1b @ If new byte, goto old routine ARM( ldrb r3, [r0, r2, lsr #3] ) THUMB( lsr r3, r2, #3 ) THUMB( ldrb r3, [r0, r3] ) eor r3, r3, #0xff @ now looking for a 1 bit movs r3, r3, lsr ip @ shift off unused bits bne .L_found orr r2, r2, #7 @ if zero, then no bits here add r2, r2, #1 @ align bit pointer b 2b @ loop for next bit ENDPROC(_find_next_zero_bit_le)
if (fd < fdt->max_fds) fd = find_next_fd(fdt, fd); // 起始查找文件描述符小于最大文件描述符,从当前文件描述符表中查找可用的文件描述符(max_fds表示已分配的文件描述符的数量,也就是位图总的bit数,后面会看到文件描述符表扩展的代码,在此先介绍下)
/* * N.B. For clone tasks sharing a files structure, this test * will limit the total number of files that can be opened. */ error = -EMFILE; if (fd >= end) // 可用文件描述符超出函数参数传递的最大值,返回-EMFILE,这是个标准错误码errno goto out;
/* * Expand files. * This function will expand the file structures, if the requested size exceeds * the current capacity and there is room for expansion. * Return <0 error code on error; 0 when nothing done; 1 when files were * expanded and execution may have blocked. * The files->file_lock should be held on entry, and will be held on exit. */ staticintexpand_files(struct files_struct *files, unsignedint nr) __releases(files->file_lock) __acquires(files->file_lock) { structfdtable *fdt; int expanded = 0;
repeat: fdt = files_fdtable(files); // 获取文件描述符表 /* Do we need to expand? */ if (nr < fdt->max_fds) // 新的文件描述符<max_fds,旧的文件描述符表已经足够表示该文件描述符了,不需要扩展。 return expanded;
/* Can we expand? */ if (nr >= sysctl_nr_open) // 大于限制的最大文件描述符,返回错误,不运行操作系统设置的最大文件描述符 return -EMFILE;
/* * Expand the file descriptor table. * This function will allocate a new fdtable and both fd array and fdset, of * the given size. * Return <0 error code on error; 1 on successful completion. * The files->file_lock should be held on entry, and will be held on exit. */ staticintexpand_fdtable(struct files_struct *files, unsignedint nr) __releases(files->file_lock) __acquires(files->file_lock) { structfdtable *new_fdt, *cur_fdt;
/* * Figure out how many fds we actually want to support in this fdtable. * Allocation steps are keyed to the size of the fdarray, since it * grows far faster than any of the other dynamic data. We try to fit * the fdarray into comfortable page-tuned chunks: starting at 1024B * and growing in powers of two from there on. */ nr /= (1024 / sizeof(struct file *)); nr = roundup_pow_of_two(nr + 1); nr *= (1024 / sizeof(struct file *)); // nr大小不确定,这之前的步骤就是为了调整nr大小,具体含义看英文说明 /* * Note that this can drive nr *below* what we had passed if sysctl_nr_open * had been set lower between the check in expand_files() and here. Deal * with that in caller, it's cheaper that way. * * We make sure that nr remains a multiple of BITS_PER_LONG - otherwise * bitmaps handling below becomes unpleasant, to put it mildly... */ if (unlikely(nr > sysctl_nr_open)) // nr大于系统设置的文件描述符上限,需要调整不超过系统设置的上限 nr = ((sysctl_nr_open - 1) | (BITS_PER_LONG - 1)) + 1;
fdt = kmalloc(sizeof(struct fdtable), GFP_KERNEL_ACCOUNT); // 申请内存空间 if (!fdt) goto out; fdt->max_fds = nr; // 最大文件描述符 data = kvmalloc_array(nr, sizeof(struct file *), GFP_KERNEL_ACCOUNT); if (!data) goto out_fdt; fdt->fd = data;
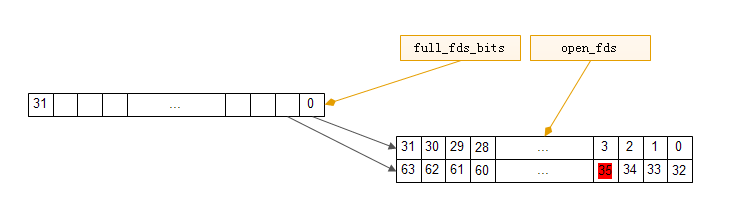
data = kvmalloc(max_t(size_t, 2 * nr / BITS_PER_BYTE + BITBIT_SIZE(nr), L1_CACHE_BYTES), GFP_KERNEL_ACCOUNT); if (!data) goto out_arr; fdt->open_fds = data; // 文件描述符位图(每一位代表一个文件描述符) data += nr / BITS_PER_BYTE; fdt->close_on_exec = data; // close_on_exec文件描述符位图(用于在exec创建替换父进程时,确定哪些文件描述符需要关闭) data += nr / BITS_PER_BYTE; fdt->full_fds_bits = data; // 文件描述符组位图(每一位代表一个文件描述符组,一组文件描述符有32个文件描述符,当该组文件描述符都被使用了的时候,将该组对应的bit位设置为1,表示该组已经没有可用文件描述符了) return fdt;