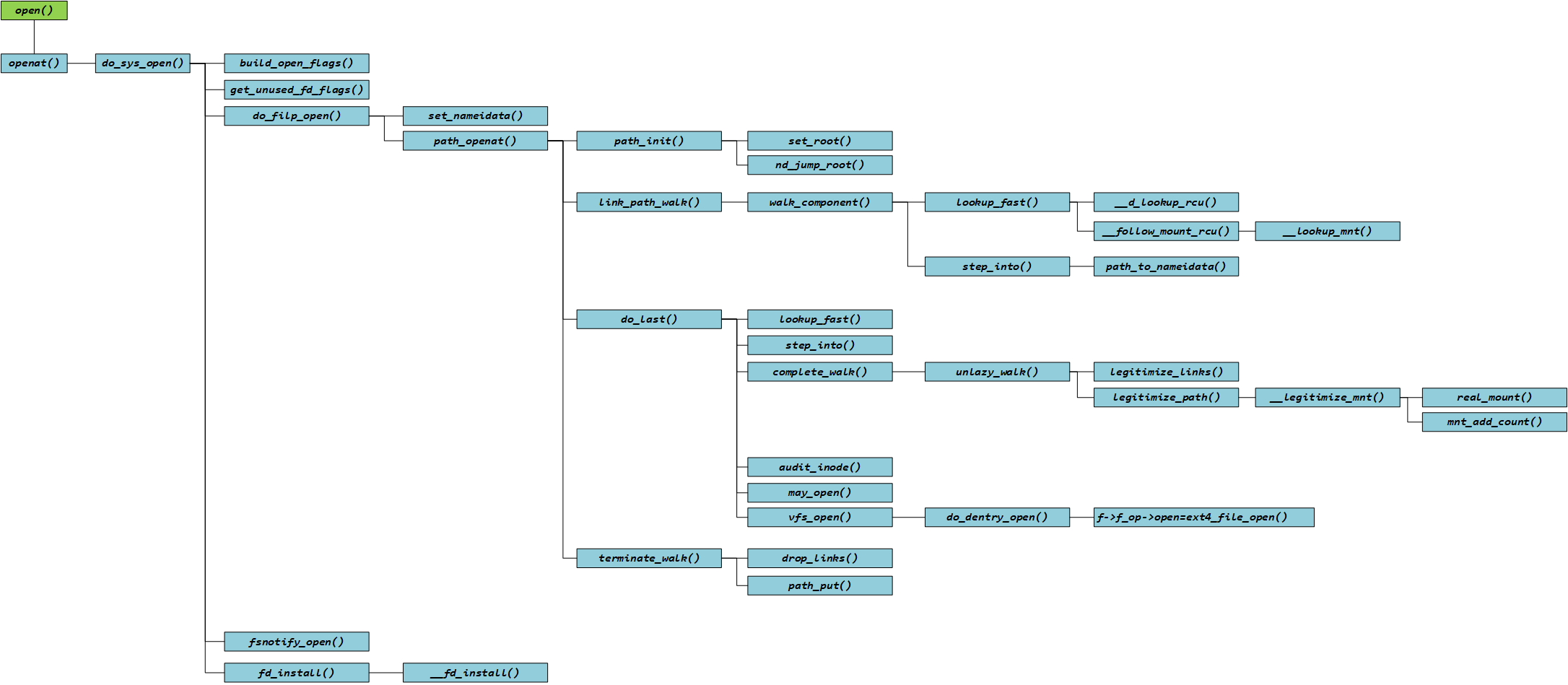
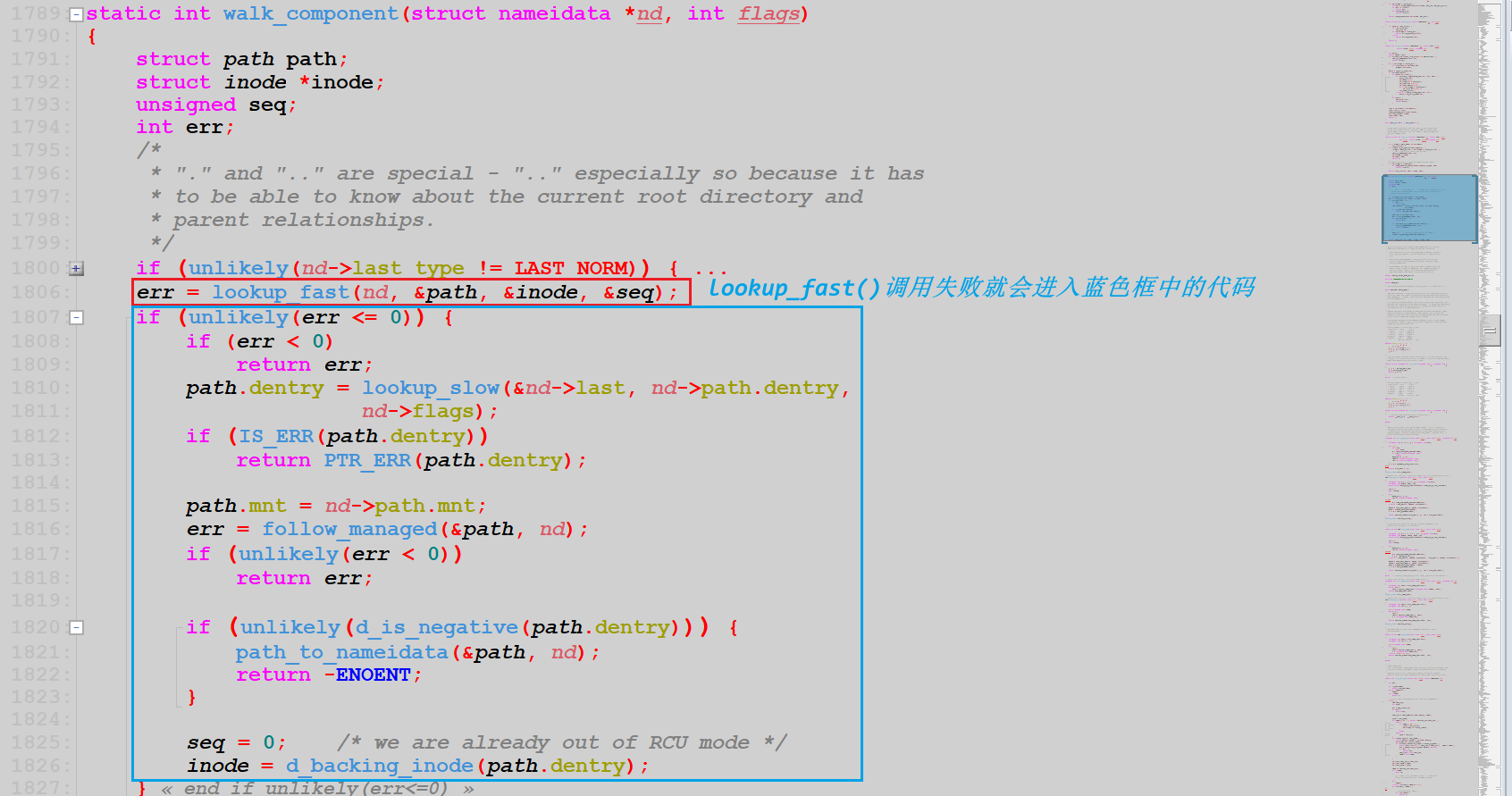
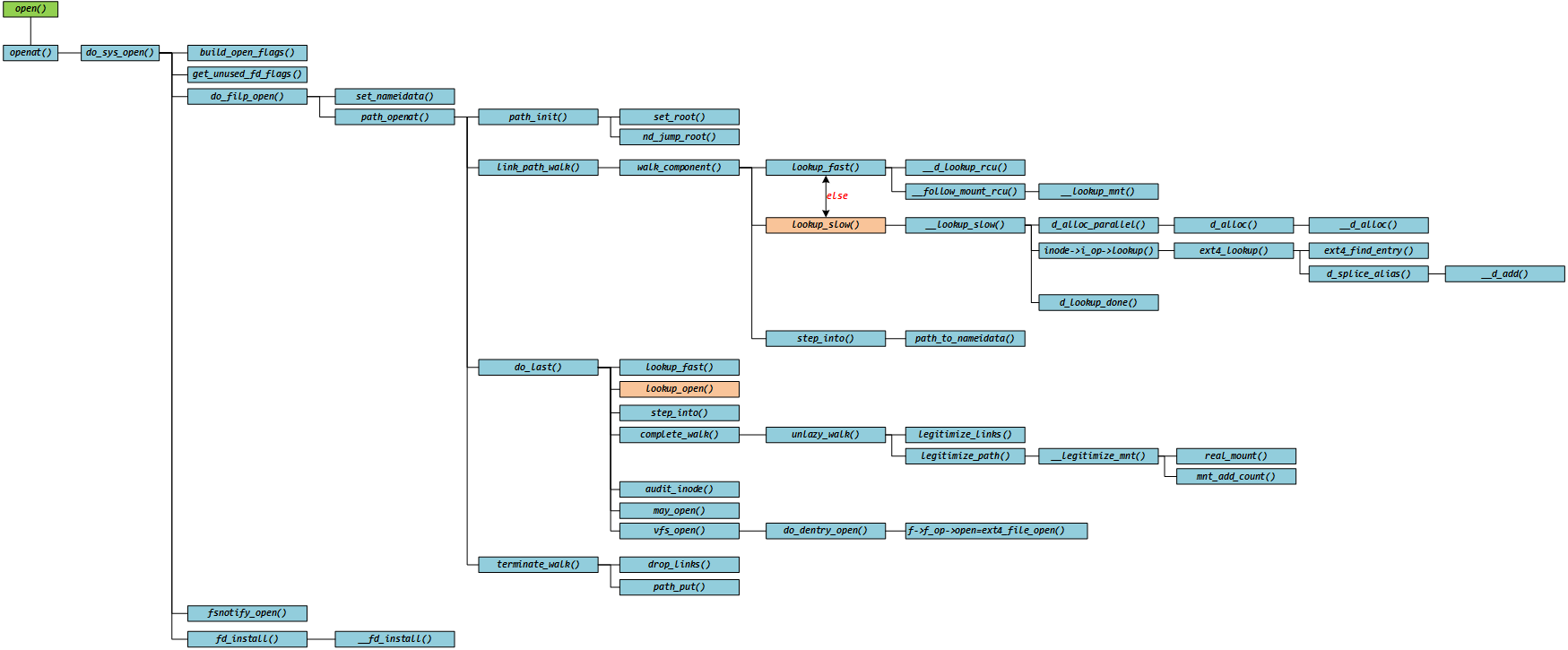
/* Fast lookup failed, do it the slow way */ staticstructdentry *__lookup_slow(conststruct qstr *name, struct dentry *dir, unsignedint flags) { structdentry *dentry, *old; structinode *inode = dir->d_inode; DECLARE_WAIT_QUEUE_HEAD_ONSTACK(wq);
/* Don't go there if it's already dead */ if (unlikely(IS_DEADDIR(inode))) // if 判断为 0 //...... again: dentry = d_alloc_parallel(dir, name, &wq); if (IS_ERR(dentry)) // if 判断为 0 //...... if (unlikely(!d_in_lookup(dentry))) { // 不考虑并发性问题, if 判断为 0 //...... } else { old = inode->i_op->lookup(inode, dentry, flags);// 一般情况下,返回NULL d_lookup_done(dentry); if (unlikely(old)) { // if 判断为 0 //...... } } return dentry; }
if (unlikely(!new)) // if 判断为 0 //...... retry: rcu_read_lock(); seq = smp_load_acquire(&parent->d_inode->i_dir_seq); r_seq = read_seqbegin(&rename_lock); dentry = __d_lookup_rcu(parent, name, &d_seq); if (unlikely(dentry)) { // if 判断为 0(dentry 刚刚被创建和初始化,但尚未被加入哈希表中 (不考虑并发性问题)) //...... } if (unlikely(read_seqretry(&rename_lock, r_seq))) {// 暂不考虑并发性问题,假设此时无需 retry, if 判断为 0 //...... }
if (unlikely(seq & 1)) { rcu_read_unlock(); goto retry; }
hlist_bl_lock(b); if (unlikely(READ_ONCE(parent->d_inode->i_dir_seq) != seq)) { // 暂不考虑,假设 if 判断为 0 //...... } /* * No changes for the parent since the beginning of d_lookup(). * Since all removals from the chain happen with hlist_bl_lock(), * any potential in-lookup matches are going to stay here until * we unlock the chain. All fields are stable in everything * we encounter. */ // 遍历 in_lookup_hashtable,在不考虑并发性的问题情况下,新创建的这个 dentry 在 in_lookup_hashtable 中也找不到 hlist_bl_for_each_entry(dentry, node, b, d_u.d_in_lookup_hash) { if (dentry->d_name.hash != hash) //if 判断始终为 1, 直到整个遍历结束 continue; //...... } rcu_read_unlock(); /* we can't take ->d_lock here; it's OK, though. */ new->d_flags |= DCACHE_PAR_LOOKUP; new->d_wait = wq; // 将新创建的 dentry 加入到 in_lookup_hashtable 中,以便并发访问的其他程序能够找到,不会重复创建相同 dentry hlist_bl_add_head_rcu(&new->d_u.d_in_lookup_hash, b); hlist_bl_unlock(b); returnnew; // 函数返回 mismatch: //...... } EXPORT_SYMBOL(d_alloc_parallel);
/** * d_alloc - allocate a dcache entry * @parent: parent of entry to allocate * @name: qstr of the name * * Allocates a dentry. It returns %NULL if there is insufficient memory * available. On a success the dentry is returned. The name passed in is * copied and the copy passed in may be reused after this call. */ structdentry *d_alloc(struct dentry * parent, conststruct qstr *name) { structdentry *dentry = __d_alloc(parent->d_sb, name); if (!dentry) returnNULL; spin_lock(&parent->d_lock); /* * don't need child lock because it is not subject * to concurrency here */ __dget_dlock(parent); dentry->d_parent = parent; list_add(&dentry->d_child, &parent->d_subdirs);//将新创建的 dentry->d_child 加入 父目录的 dentry->d_subdirs 链后面,此处不做详细分析 spin_unlock(&parent->d_lock);
dentry = kmem_cache_alloc(dentry_cache, GFP_KERNEL); if (!dentry) returnNULL;
/* * We guarantee that the inline name is always NUL-terminated. * This way the memcpy() done by the name switching in rename * will still always have a NUL at the end, even if we might * be overwriting an internal NUL character */ dentry->d_iname[DNAME_INLINE_LEN-1] = 0; if (unlikely(!name)) {//这里if 判断结果为0 //...... } elseif (name->len > DNAME_INLINE_LEN-1) {//DNAME_INLINE_LEN=32,name ~ sumu/7Linux/test.txt, if 判断为0 //...... } else { dname = dentry->d_iname; }