LV16-26-LCD-05-字符编码
本文主要是字符编码基础知识的相关笔记,若笔记中有错误或者不合适的地方,欢迎批评指正😃。
点击查看使用工具及版本
| Windows | windows11 |
| Ubuntu | Ubuntu16.04的64位版本 |
| VMware® Workstation 16 Pro | 16.2.3 build-19376536 |
| SecureCRT | Version 8.7.2 (x64 build 2214) - 正式版-2020年5月14日 |
| 开发板 | 正点原子 i.MX6ULL Linux阿尔法开发板 |
| uboot | NXP官方提供的uboot,NXP提供的版本为uboot-imx-rel_imx_4.1.15_2.1.0_ga(使用的uboot版本为U-Boot 2016.03) |
| linux内核 | linux-4.15(NXP官方提供) |
| STM32开发板 | 正点原子战舰V3(STM32F103ZET6) |
点击查看本文参考资料
- 通用
| 分类 | 网址 | 说明 |
| 官方网站 | https://www.arm.com/ | ARM官方网站,在这里我们可以找到Cotex-Mx以及ARMVx的一些文档 |
| https://www.st.com/content/st_com/zh.html | ST官方网站,在这里我们可以找到STM32的相关文档 | |
| https://www.stmcu.com.cn/ | 意法半导体ST中文官方网站,在这里我们可以找到STM32的相关中文参考文档 | |
| http://elm-chan.org/fsw/ff/00index_e.html | FatFs文件系统官网 | |
| 教程书籍 | 《ARM Cortex-M3权威指南》 | ARM公司专家Joseph Yiu(姚文祥)的力作,中文翻译是NXP的宋岩 |
| 《ARM Cortex-M0权威指南》 | ||
| 《ARM Cortex-M3与Cortex-M4权威指南》 | ||
| 开发论坛 | http://47.111.11.73/forum.php | 开源电子网,正点原子的资料下载及问题讨论论坛 |
| https://www.firebbs.cn/forum.php | 国内Kinetis开发板-野火/秉火(刘火良)主持的论坛,现也做STM32和i.MX RT | |
| https://www.amobbs.com/index.php | 阿莫(莫进明)主持的论坛,号称国内最早最火的电子论坛,以交流Atmel AVR系列单片机起家,现已拓展到嵌入式全平台,其STM32系列帖子有70W+。 | |
| http://download.100ask.net/index.html | 韦东山嵌入式资料中心,有些STM32和linux的相关资料也可以来这里找。 | |
| 博客参考 | http://www.openedv.com/ | 开源网-原子哥个人博客 |
| http://blog.chinaaet.com/jihceng0622 | 博主是原Freescale现NXP的现场应用工程师 | |
| cortex-m-resources | 这其实并不算是一个博客,这是ARM公司专家Joseph Yiu收集整理的所有对开发者有用的官方Cortex-M资料链接(也包含极少数外部资源链接) |
- STM32
| STM32 | STM32 HAL库开发实战指南——基于F103系列开发板 | 野火STM32开发教程在线文档 |
| STM32库开发实战指南——基于野火霸道开发板 | 野火STM32开发教程在线文档 |
- SD卡
| SD Association | 提供了SD存储卡和SDIO卡系统规范 |
- 字符编码参考网站
| 千千秀字 (qqxiuzi.cn) | 字符编码及转换测试 |
| Unicode – The World Standard for Text and Emoji | Unicode官网 |
点击查看相关文件下载
| STM32F103xx英文数据手册 | STM32F103xC/D/E系列的英文数据手册 |
| STM32F103xx中文数据手册 | STM32F103xC/D/E系列的中文数据手册 |
| STM32F10xxx英文参考手册(RM0008) | STM32F10xxx系列的英文参考手册 |
| STM32F10xxx中文参考手册(RM0008) | STM32F10xxx系列的中文参考手册 |
| Arm Cortex-M3 处理器技术参考手册-英文版 | Cortex-M3技术参考手册-英文版 |
| STM32F10xxx Cortex-M3编程手册-英文版(PM0056) | STM32F10xxx/20xxx/21xxx/L1xxxx系列Cortex-M3编程手册-英文版 |
| SD卡相关资料——最新版本 | 有关SD卡的一些资料可以从这里下载 |
| SD卡相关资料——历史版本 | 有关SD卡的一些历史版本资料可以从这里下载,比如后边看的SD卡2.0协议 |
| SD 2.0 协议标准完整版 | 这是一篇关于SD卡2.0协议的中文文档,还是比较有参考价值的,可以一看 |
一、字符编码概述
在计算机上,我们看到的字符“ A”可能长这样 :

对于同一个 TXT 文件中的内容,我们在 Notepad++ 上选择不同字体时,字符显示的形状也可能不一样。 所以 TXT 文件中保存的是字符的核心:它的编码值。而 Notepad++ 上显示时,这些字符对应什么样的形状态,这是由字符文件决定的。
编码值,字体是两个不一样的东西,比如 A 的编码值是 0x41,但是在屏幕上显示出来时可以使用不同的形状。什么叫编码?就是一个字符用什么数字来表示。在计算机里一切都是用数字来表示,比如字符 A,用 0x01 还是 0x02 来表示它?我们使用 0x41 来表示它。当我们去打开一个 TXT 文件时,发现里面含有数值 0x41,我们就知道了:哦,这里有一个字符 A。
一个字符用哪个数字来表示?有很多标准 ,我们这就来了解一下吧。
二、ASCII编码
1. 简介
由于计算机只能识别0和1,文字也只能以0和1的形式在计算机里存储,所以我们需要对文字进行编码才能让计算机处理,编码的过程就是规定特定的01数字串来表示特定的文字,最简单的字符编码例子是ASCII码。
ASCII码,就是“American Standard Code for Information Interchange”的缩写, 美国信息交换标准代码。电脑毕竟是西方人发明的,他们常用字母就 26 个,区分大小写、加上标点符号也没超过 127 个,每个字符用一个字节来表示就足够了。一个字节的 7 位就可以表示 128 个数值,所以在 ASCII 码中最高位永远是 0。
在程序设计中使用的ASCII编码表约定了一些控制字符、英文及数字。它们在存储器中,本质也就是二进制数,只是我们约定这些二进制数可以表示某些特殊意义,如以ASCII编码解释数字“0x41”时,它表示英文字符“A”。
2. ASCII编码表
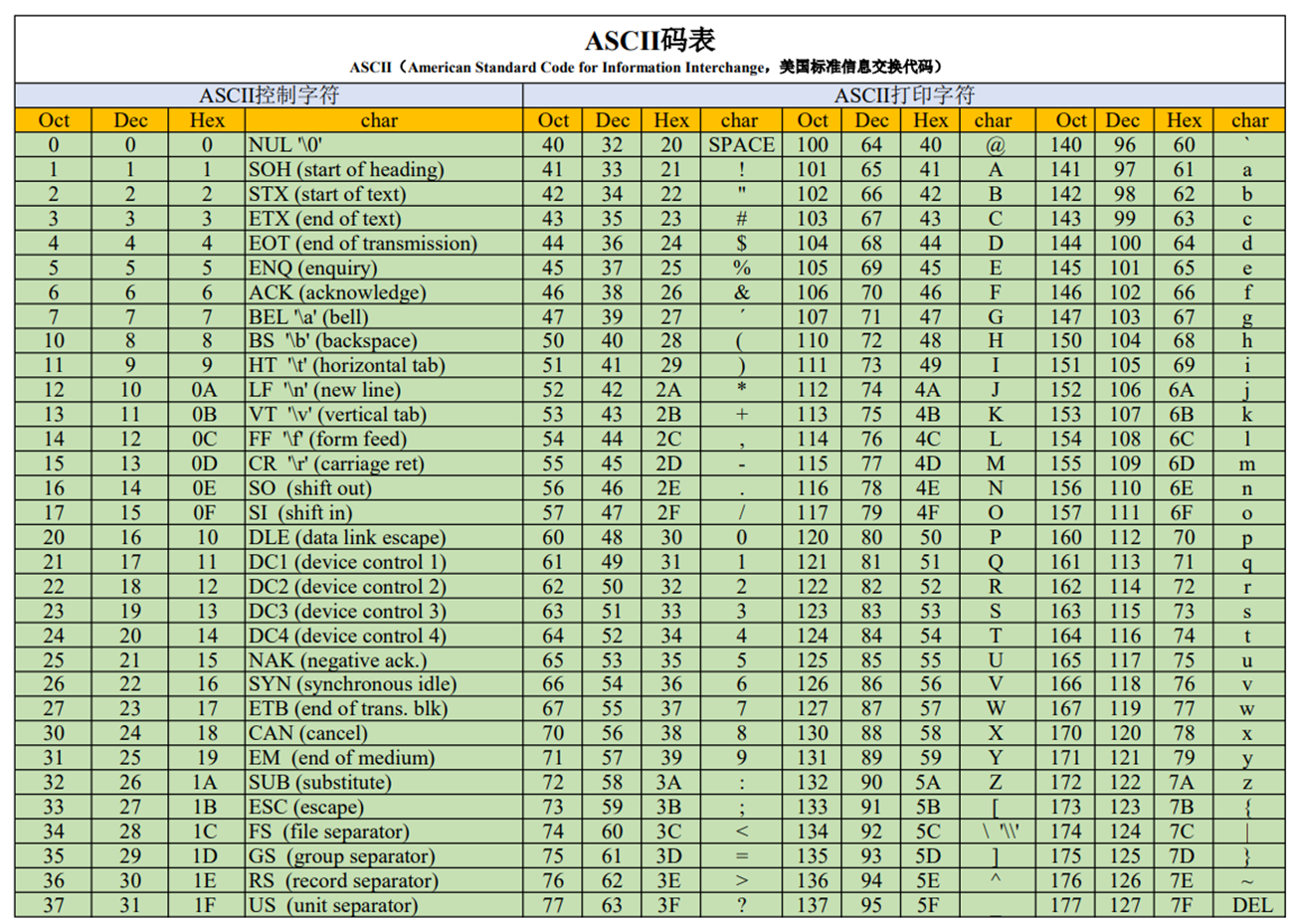
ASCII码表分为两部分:
(1)第一部分是控制字符或通讯专用字符,它们的数字编码从0~31,它们并没有特定的图形显示,但会根据不同的应用程序,而对文本显示有不同的影响。
(2)的第二部分包括空格、阿拉伯数字、标点符号、大小写英文字母以及“DEL(删除控制)”,这部分符号的数字编码从32~127,除最后一个DEL符号外,都能以图形的方式来表示,它们属于传统文字书写系统的一部分。
三、ANSI编码
1. 记事本保存没有ASCII?
我们打开记事本,保存一个文件,并指定编码方式:
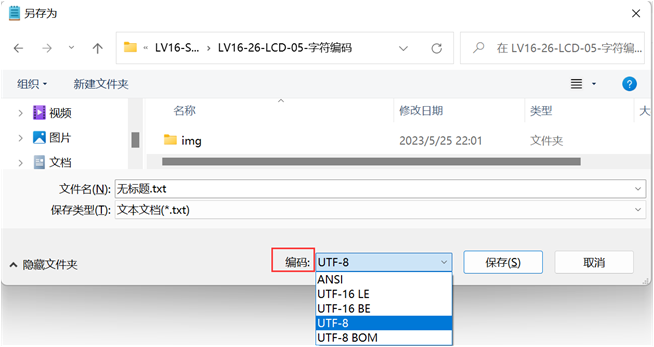
使用记事本保存文件时,可以选择“ ANSI”编码,却没有“ ASCII”,这是怎么回事?
2. ASNI简介
2.1 ANSI是什么编码
这部分主要参考ANSI是什么编码? - malecrab - 博客园 (cnblogs.com),防止原文找不到,这里自己做一遍笔记备份一下。
用Notepad++创建一个文本文件text.txt,其默认编码格式为ANSI(不仔细看还以为是ASCII),输入汉字居然不是乱码:
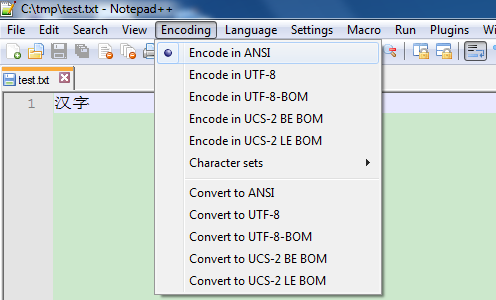
保存为test.txt,发送给自己美国的同事Bob(假装有这么一个同事)。他也用Notepad++,不幸的是,却发现我们的文件内容是这样的:
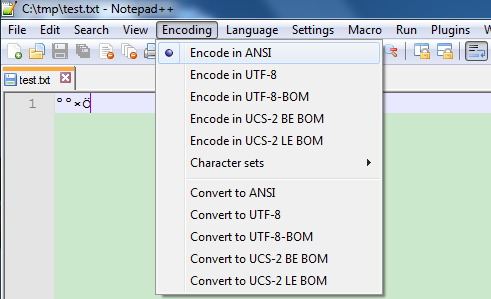
也许我们会认为:我们用的是中文系统,能正常显示中文;他用的是英文系统,不能显示中文!这么想,是不是很有道理。但是再细想一下:一个系统显示乱码,说明它不支持这种编码格式(或者解码方式不对)。难道英文系统不支持ANSI?难道ANSI是一种中文编码?
如果我们身边有一个韩文系统,也装一个Notepad++,默认还是ANSI编码,我们可以输入“한국어”,发现也能正常显示:
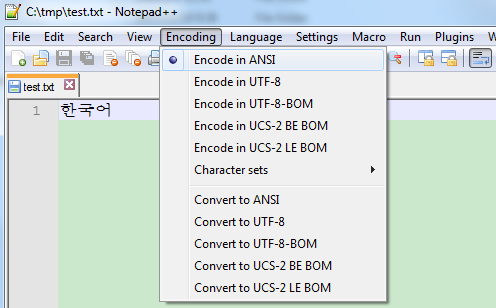
但是我们要输入“汉字”可能就会发现是乱码了。通过这个反例,就可以说明ANSI不是一种中文编码。那么,ANSI到底是什么编码?
用十六进制编辑器打开内容为“汉字”的test.txt文件:

会发现:其中baba和d7d6正好是“汉”和“字”两个字的GBK 编码值。同样,用十六进制编辑器打开内容为“한국어”的test.txt文件:

会发现:其中c7d1、b1b9和beee正好是“한”、“국”和“어”三个字符的EUC-KR编码值。
由此可以看出:其实ANSI并不是某一种特定的字符编码,而是在不同的系统中,ANSI表示不同的编码。我们美国同事Bob的系统中ANSI编码其实是ASCII编码(ASCII编码不能表示汉字,所以汉字为乱码),而我们的系统中(“汉字”正常显示)ANSI编码其实是GBK编码,而韩文系统中(“한국어”正常显示)ANSI编码其实是EUC-KR编码。
一个类似野史的小故事:
话说计算机是由美国佬搞出来的嘛,他们觉得一个字节(可以表示256个编码)表示英语世界里所有的字母、数字和常用特殊符号已经绰绰有余了(其实ASCII只用了前127个编码)。后来欧洲人不干了,法国人说:我需要在小写字母加上变音符号(如:é),德国人说:我也要加几个字母(Ä ä、Ö ö、Ü ü、ß)。于是,欧洲人就将ASCII没用完的编码(128-255)为自己特有的符号编码(后来称之为“扩展字符集”)。等到我们中国人开始使用计算机的时候,尼玛,256个编码哪够?我泱泱大中华,汉字起码也得N多万吧,就连小学生都得要求掌握两三千字。国标局最后拍板:一个字节不够,那我们就用多个字节来为汉字编码吧,但是,国情那么穷,字节那么贵,三个字节伤不起,那就用俩字节吧,先给常用的几千汉字编个码,等以后国家强盛了人民富裕了,咱再扩展呗—于是GB2312就产生了。台湾同胞一看,尼玛,全是简体字,还让不让我们写繁体字的活了,于是台湾同胞也自己弄了个繁体字编码—大五码(Big-5)。同时,其它国家也在为自己的文字编码。最后,微软苦逼了:顾客就是上帝啊,你们的编码我都得满足啊,这样吧,卖给美国国内的系统默认就用ASCII编码吧,卖给中国人的系统默认就用GBK编码吧,卖给韩国人的系统默认就用EUC-KR编码,…但是为了避免你们误会我卖给你们的系统功能有差异,我就统一把你们的默认编码都显示成ANSI吧。—本故事纯属虚构,但“ANSI编码”确实只存在于Windows系统。
所以其实ASNI 是 ASCII 的扩展,向下包含 ASCII。对于 ASCII 字符仍以一个字节来表示,对于非 ASCII 字符则使用 2 字节来表示。并没有固定的 ASNI 编码,它跟“**本地化”(local)**密切相关。比如在中国大陆地区, ANSI 的默认编码是 GBK;在港澳台地区默认编码是 BIG5。以数值“ 0xd0d6”为例,对于 GB2312 编码它表示“中”;对于 BIG5 编码它表示“ 笢”。
2.2 Windows如何区分?
那么Windows系统是如何区分ANSI背后的真实编码的呢?
微软用一个叫“Windows code pages”(在命令行下执行chcp命令可以查看当前code page的值)的值来判断系统默认编码,比如:简体中文的code page值为936(它表示GBK编码,win95之前表示GB2312,详见:Microsoft Windows’ Code Page 936),繁体中文的code page值为950(表示Big-5编码)。

我们能否通过修改Windows code pages的值来改变“ANSI编码”呢?命令提示符下,我们可以通过chcp命令来修改当前终端的active code page,例如:
(1) 执行:chcp 437,code page改为437,当前终端的默认编码就为ASCII编码了(汉字就成乱码了);
(2) 执行:chcp 936,code page改为936,当前终端的默认编码就为GBK编码了(汉字又能正常显示了)。
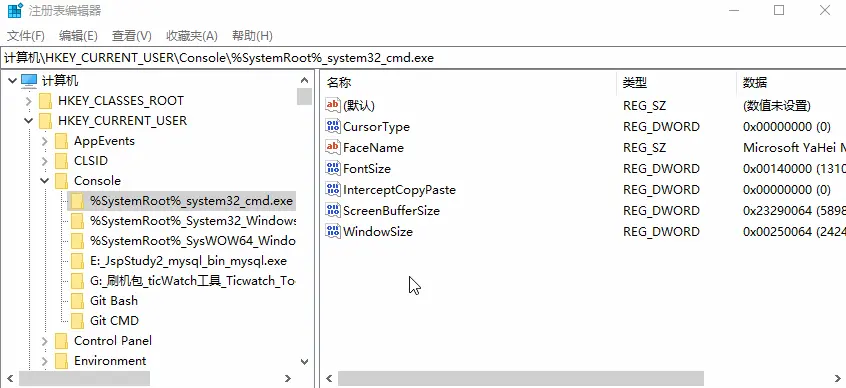
上面的操作只在当前终端起作用,并不会影响系统默认的“ANSI编码”。若是之前是无法使用 chcp 命令,可以这样操作:打开注册表编辑器,定位到这里路径(网上找的,但是我的是win11,似乎没有这一项,这里大概了解一下就是了):
1 | 计算机\HKEY_CURRENT_USER\Console%SystemRoot%_system32_cmd.exe |
说明:
十六进制”000003a8”或十进制”936”,表示“936 (ANSI/OEM - 简体中文 GBK)”。
十六进制”000001b5”或十进制”437”,表示“437 (OEM - 美国)”。
通过修改注册表的这一项后,重新打开一个 cmd 窗口,输入 “chcp”就能显示当前的活动代码页面了。重新打开一个 cmd 窗口,又会改为默认的 936 编码,这只是权宜之计。如何永久修改?我们打开到这一项:
1 | 计算机\HKEY_CURRENT_USER\Software\Microsoft\Command Processor |
添加 autorun 字符串值:
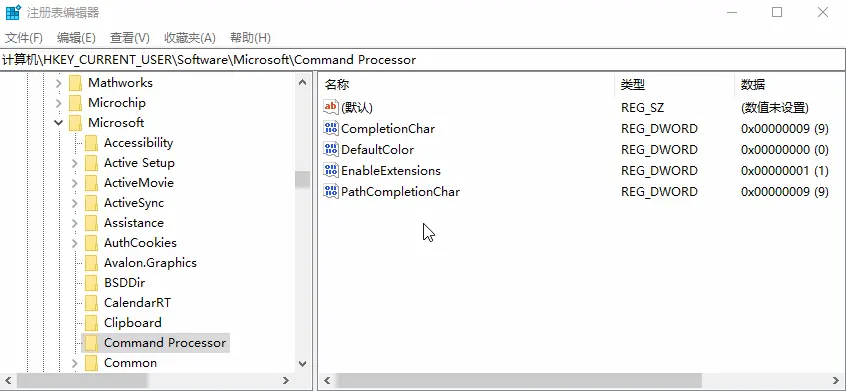
现在无论你什么时候运行 cmd 命令行(哪怕是任意程序,调用 cmd 程序运行一些指令)都会默认使用 UTF-8 的编码显示了。如果需要显示特殊字体,修改编码后仍然无法正常显示,则需要额外安装命令行字体,另外这里如果影响某些程序运行,可以删除这第二处注册表的值。
那图形界面能改吗?也可以,Windows下code page是根据当前系统区域(locale)来设置的,要想修改系统默认的“ANSI编码”,我们可以通过修改系统区域来实现(“控制面板” →“时钟、语言和区域”→“区域和语言”→“管理”→“更改系统区域设置”):
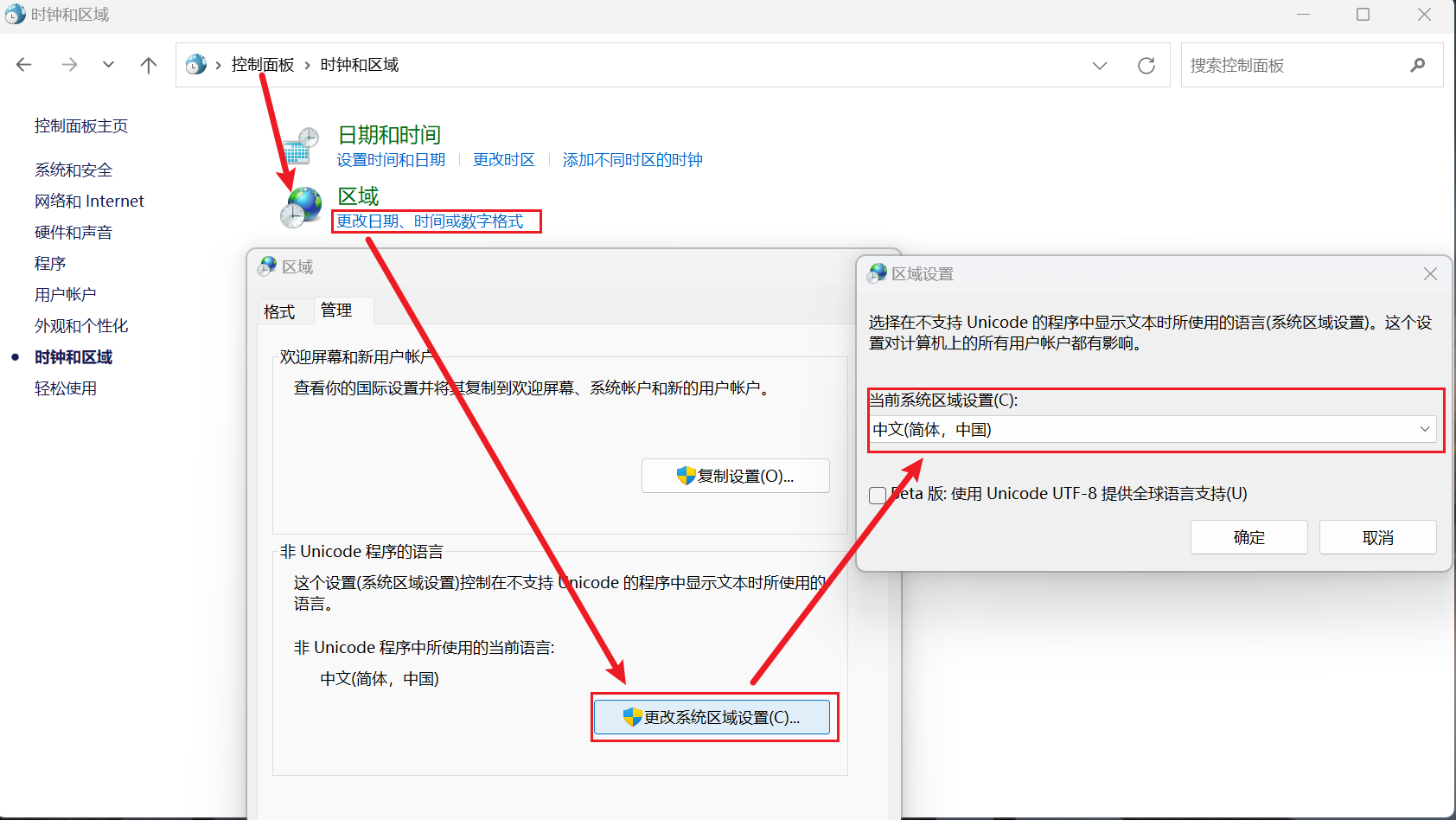
图中的系统locale为简体中文,意味着当前“ANSI编码”实际是GBK编码。当把它改成Korean(Korea)时,“ANSI编码”实际是EUC-KR编码,“한국어”就能正常显示了;当把它改成English(US)时,“ANSI编码”实际是ASCII编码,“汉字”和“한국어”都成乱码了。(改了之后需要重启系统的)
说明:locale是国际化与本地化中重要的概念,这里就不再更深入了解了。
2.3 linux呢?
将前述内容为“汉字”的文件test.txt拷贝至Linux下,用Emacs打开:

也是乱码!原因也是locale的问题:
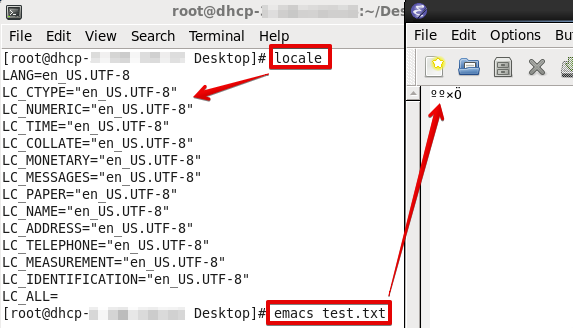
更改locale后再打开:
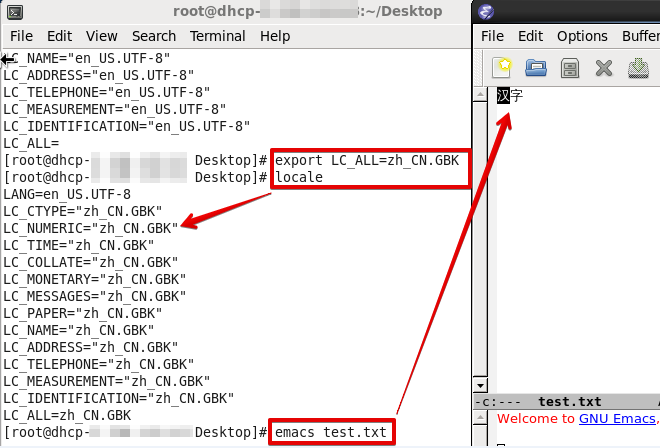
3. 具体编码
通过对上面的了解,我们知道对于 ANSI 编码的 TXT 文件,如果我们打开它发现乱码,那么还得再次细分它的具体编码。我们新建一个ANSI编码的txt文本文档,并输入以下数据:
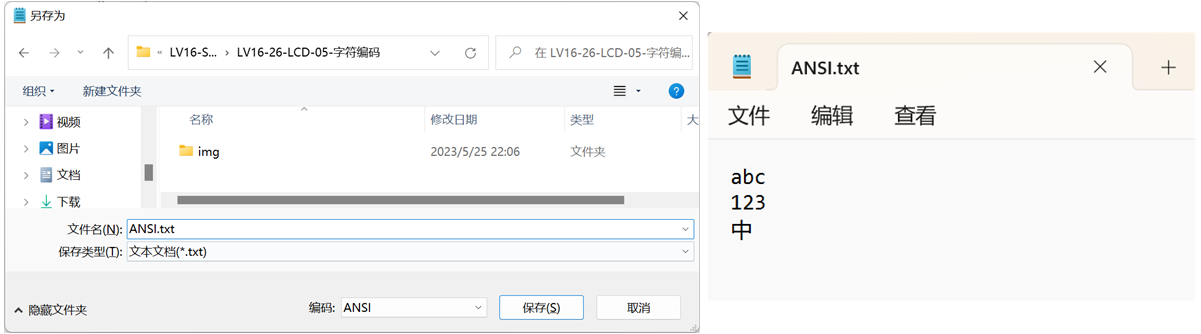
然后我们通过Notepad++打开,为什么用这个软件?因为它可以很方便的帮我们转换各种字符编码:

我们查看文件的十六进制编码的话需要装一个插件,名字叫HEX-Editor,安装完毕后,我们就可以将文件内容编程十六进制的形式显示啦,就像上图。我们现在选择不同的编码格式打开这个文件:

这仅仅是在中国地区就出现这些不兼容的问题。对于不同国家,它们默认的ANSI 编码各不相同,所以同一个 TXT 文件在不同国家就很有可能出现乱码。根本的原理在于没有“统一的编码”,那解决方法自然就是使用“统一的编码”: UNICODE。这个我们后面再详细说。
四、中文编码
1. 概述
英文书写系统都是由26个基本字母组成,利用26个字母组可合出不同的单词,所以用ASCII码表就能表达整个英文书写系统。而中文书写系统中的汉字是独立的方块,若参考单词拆解成字母的表示方式,汉字可以拆解成部首、笔画来表示,但这样会非常复杂(可参考五笔输入法编码),所以中文编码直接对方块字进行编码,一个汉字使用一个号码。
由于汉字非常多,常用字就有6000多个,如果像ASCII编码表那样只使用1个字节最多只能表示256个汉字,所以我们使用2个字节来编码。
2. GB2312标准
2.1 简介
我国首先定义的是GB2312标准。它把ASCII码表127号之后的扩展字符集直接取消掉,并规定小于127的编码按原来ASCII标准解释字符。当2个大于127的字符连在一起时,就表示1个汉字,第1个字节使用 (0xA1-0xFE) 编码,第2个字节使用(0xA1-0xFE)编码,这样的编码组合起来可以表示了7000多个符号,其中包含6763个汉字。可以看到从 0x7F 到 0xA1 中间其实还是有空余的,这一部分在GB2312中没有使用。
在这些编码里,我们还把数学符号、罗马字母、日文假名等都编进表中,就连原来在ASCII里原本就有的数字、标点以及字母也重新编了2个字节长的编码,这就是平时在输入法里可切换的“全角”字符,而标准的ASCII码表中127号以下的就被称为“半角”字符。
2.2 兼容ASCII?
下表说明了GB2312是如何兼容ASCII码的,当我们设定系统使用GB2312标准的时候,它遇到一个字符串时,会按字节检测字符值的大小,若遇到连续两个字节的数值都大于127(0x7F)时就把这两个连续的字节合在一起,用GB2312解码,若遇到的数值小于127(0x7F),就直接用ASCII把它解码。
| 第1字节 | 第2字节 | 表示的字符 | 说明 |
|---|---|---|---|
| 0x68 | 0x69 | (hi) | 两个字节的值都小于127(0x7F),使用ASCII解码 |
| 0xB0 | 0xA1 | (啊) | 两个字节的值都大于127(0x7F),使用GB2312解码 |
2.3 区位码
在 GB2312 编码的实际使用中,有时会用到区位码的概念。GB2312编码对所收录字符进行了“分区”处理,共94个区,每区含有94个位,共8836个码位。
区位码实际是GB2312编码的内部形式,它规定对收录的每个字符采用两个字节表示:第一个字节为“高字节”,对应94个区;第二个字节为“低字节”,对应94个位。所以它的区位码范围是:0101-9494。
为兼容ASCII码,区号和位号分别加上0xA0偏移就得到GB2312编码。在区位码上加上0xA0偏移,可求得GB2312编码范围:0xA1A1-0xFEFE,其中汉字的编码范围为0xB0A1-0xF7FE,第一字节0xB0-0xF7(对应区号:16-87),第二个字节0xA1-0xFE(对应位号:01-94)。
例如,“啊”字是GB2312编码中的第一个汉字,它位于16区的01位,所以它的区位码就是1601,加上0xA0偏移,其GB2312编码为0xB0A1。其中区位码为0101的码位表示的是“空格”符。我们可以看一下GB2312 编码范围, GB2312 编码表 (qqxiuzi.cn)这个网站这里的趣味码表:

1 | 16 + 0xA0 = 0xB0 |
3. GBK标准
3.1 简介
据统计,GB2312编码中表示的6763个汉字已经覆盖中国大陆99.75%的使用率,单看这个数字已经很令人满意了,但是不能因为那些文字不常用就不让它进入信息时代,而且生僻字在人名、文言文中的出现频率是非常高的。
为此我们在GB2312标准的基础上又增加了14240个新汉字(包括所有后面介绍的Big5中的所有汉字)和符号,这个方案被称为GBK标准。增加这么多字符,按照GB2312原来的格式来编码,2个字节已经存储不下,我们的程序员修改了一下格式,不再要求第2个字节的编码值必须大于127,只要第1个字节大于127就表示这是一个汉字的开始,这样就做到兼容ASCII和GB2312标准了。
3.2 兼容GB2312?
下表说明了GBK是如何兼容ASCII和GB2312标准的,当我们设定系统使用GBK标准的时候,它按顺序遍历字符串,按字节检测字符值的大小,若遇到一个字符的值大于127时,就再读取它后面的一个字符,把这两个字符值合在一起,用GBK解码,解码完后,再读取第3个字符,重新开始以上过程,若该字符值小于127,则直接用ASCII解码。
| 第1字节 | 第2字节 | 第3字节 | 表示的字符 | 说明 |
|---|---|---|---|---|
| 0x68(<7F) | 0xB0(>7F) | 0xA1(>7F) | (h啊) | 第1个字节小于127,使用ASCII解码,每2个字节大于127,直接使用GBK解码,兼容GB2312 |
| 0xB0(>7F) | 0xA1(>7F) | 0x68(<7F) | (啊h) | 第1个字节大于127,直接使用GBK码解释,第3个字节小于127,使用ASCII解码 |
| 0xB0(>7F) | 0x56(<7F) | 0x68(<7F) | (癡h) | 第1个字节大于127,第2个字节虽然小于127,直接使用GBK解码,第3个字节小于127,使用ASCII解码 |
3.3 区位码
与GB2312一样,GBK编码也有区位码,我们可以参考这里:GBK 编码范围, GBK 编码表 (qqxiuzi.cn),上边我们知道每个GBK码由2个字节组成,第一个字节为0X810XFE,第二个字节分为两部分,一是0X400X7E,二是0X80~0XFE。我们把第一个字节代表的意义称为区,那么GBK里面总共有126个区(0XFE-0X81+1),每个区内有190个汉字(0XFE-0X80+0X7E-0X40+2),总共就有126*190=23940个汉字。

4. GB18030标准
随着计算机技术的普及,我们后来又在GBK的标准上不断扩展字符,这些标准被称为GB18030,如GB18030-2000、GB18030-2005等(“-”号后面的数字是制定标准时的年号),GB18030的编码使用4个字节,它利用前面标准中的第2个字节未使用的“0x30-0x39”编码表示扩充四字节的后缀,兼容GBK、GB2312及ASCII标准。
GB18030-2000主要在GBK基础上增加了“CJK(中日韩)统一汉字扩充A”的汉字。加上前面GBK的内容,GB18030-2000一共规定了27533个汉字(包括部首、部件等)的编码,还有一些常用非汉字符号。
GB18030-2005的主要特点是在GB18030-2000基础上增加了“CJK(中日韩)统一汉字扩充B”的汉字。增加了42711个汉字和多种我国少数民族文字的编码(如藏、蒙古、傣、彝、朝鲜、维吾尔文等)。加上前面GB18030-2000的内容,一共收录了70244个汉字。
5. Big5编码
在台湾、香港等地区,使用较多的是Big5编码,它的主要特点是收录了繁体字。而从GBK编码开始,已经把Big5中的所有汉字收录进编码了。即对于汉字部分,GBK是Big5的超集,Big5能表示的汉字,在GBK都能找到那些字相应的编码,但他们的编码是不一样的,两个标准不兼容,如GBK中的“啊”字编码是“0xB0A1”,而Big5标准中的编码为“0xB0DA”。我们可以参考这里:BIG5 编码范围, BIG5 编码表 (qqxiuzi.cn)
6. 各个标准的对比
B2312、GBK及GB18030是汉字的国家标准编码,新版向下兼容旧版,各个标准简要说明见下表,目前比较流行的是GBK编码,因为每个汉字只占用2个字节,而且它编码的字符已经能满足大部分的需求,但国家要求一些产品必须支持GB18030标准。

五、Unicode编码
1. 概述
由于各个国家或地区都根据使用自己的文字系统制定标准,同一个编码在不同的标准里表示不一样的字符,各个标准互不兼容,而又没有一个标准能够囊括所有的字符,即无法用一个标准表达所有字符。国际标准化组织(ISO)为解决这一问题,它舍弃了地区性的方案,重新给全球上所有文化使用的字母和符号进行编号,对每个字符指定一个唯一的编号(ASCII中原有的字符编号不变),这些字符的号码从0x000000 到 0x10FFFF(有 1,114,111 即 100 多万个数值,可以表示 100 多万个字符,足够地球人使用了。 ),该编号集被称为 Universal Multiple-Octet Coded Character Set,简称UCS,也被称为Unicode。最新版的Unicode标准还包含了表情符号(聊天软件中的部分emoji表情),可访问Unicode官网了解:Unicode – The World Standard for Text and Emoji。
Unicode字符集只是对字符进行编号,但具体怎么对每个字符进行编码,Unicode并没指定,因此也衍生出了多种unicode编码方案(Unicode Transformation Format)。
2. UNICODE 编码实现
所谓编码实现,就是对于一个数值,怎么表示它。这很奇怪,数值还能怎么表示?比如“中”的 UNICODE 值是 0x4e2d,在 TXT 文件中怎么表示 0x4e2d?直接写入 0x4e2d?不行的。
比如在 TXT 文件中写入 2 字节数据“ 0x2d 0x4e”,它可以用来表示“中”字吗?这肯定是不行的,它们对应 ASCII 字符“-N”。
问题的关键在于:怎么断字。在 TXT 文件中, 2 字节数据“ 0x2d 0x4e”是作为一个整体看待,还是拆成两部分看待?
所以,需要用一定的技巧来表示数值,这就对应不同的编码实现。现在我们知道: 我们知道以下几点:
(1)ASCII 编码中使用一个字节来表示一个字符,只用到其中的 7 位,最高位恒为 0;
(2)ANSI 编码中,对于 ASCII 字符仍使用一个字节来表示(BIT7 是 0),对于非ASCII 字符一般使用 2 个字节来表示,非 ASCII 字符的数值 BIT7 都是 1。
(3)UNICODE:这就有点复杂了,下面一一了解。
2.1 新建测试文件
先用记事本新建 3 个文件: utf-16_le.txt、 utf-16_be.txt、 utf-8.txt、bom_utf-8.txt,里面的内容都是“ ab 中”,保存时编码分别选择“ UTF-16 LE”、“ UTF-16 BE”、“UTF-8”、“带有 BOM 的 UTF-8” :

一共创建四个文件:
2.2 使用3个字节表示一个Unicode
这样不可行,太浪费了。UNICODE 的最大值是 0x10FFFF,那使用 3 个字节来表示一个 Unicode 数值?这当然是很省事的方法,但是会造成浪费,比如字符 A 的 Unicode 值是0x41,总不能也用“0x41 0x00 0x00”这 3 个字节来表示吧,毕竟内存是很珍贵的东西。
2.3 UCS-2 Little endian/UTF-16 LE
每个 Unicode 值用 3 字节来表示有点浪费,那只用 2 字节呢?它可以表示2^16=65536 个字符,全世界常用的字符都可以表示了。
Little endian 表示小字节序,数值中权重低的字节放在前面,比如字符“ A 中 ”在 TXT 文件中的数值如下,其中的“ A ”使用“ 0x41 0x00 ”两字节表示;“ 中 ”使用“ 0x2d 0x4e ”两字节表示。文件开头的“ 0xff 0xfe ”表示“UTF-16 LE”。

2.4 UCS-2 Big endian/UTF-16 BE
Big endian 表示大字节序,数值中权重低的字节放在后面,比如字符“ A中 ”在 TXT 文件中的数值如下,其中的“ A ”使用“ 0x00 0x41 ”两字节表示;“ 中 ”使用“ 0x4e 0x2d ”两字节表示。文件开头的“ 0xfe 0xff ”表示“UTF-16 BE”。

2.5 UTF8
2.5.1 简介
UTF-8 是目前 Unicode 字符集中使用得最广的编码方式,目前大部分网页文件已使用 UTF-8 编码,如使用浏览器查看百度首页源文件,可以在前几行 HTML 代码中找到如下代码:
1 | <meta http-equiv=Content-Type content="text/html;charset=utf-8"> |
其中“charset”等号后面的“utf-8”即表示该网页字符的编码方式 UTF-8。 UTF-8 也是一种变长的编码方式,它的编码有 1、 2、 3、 4 字节长度的方式,每个 Unicode 字符根据自己的编号范围去进行对应的编码,见表格 UTF-8 编码原理 _x 的位置用于填充 Unicode 编号。它的编码符合以下规律:
(1)对于 UTF-8 单字节的编码,该字节的第 1 位设为 0(从左边数起第 1 位,即最高位),剩余的位用来写入字符的 Unicode 编号。即对于 Unicode 编号从 0x0000 0000 - 0x0000 007F 的字符, UTF-8 编码只需要 1 个字节,因为这个范围 Unicode 编号的字符与 ASCII 码完全相同,所以 UTF-8 兼容了 ASCII 码表。
(2)对于 UTF-8 使用 N 个字节的编码 (N>1),第一个字节的前 N 位设为 1,第 N+1 位设为 0,后面字节的前两位都设为 10,这 N 个字节的其余空位填充该字符的 Unicode 编号,高位用0 补足。
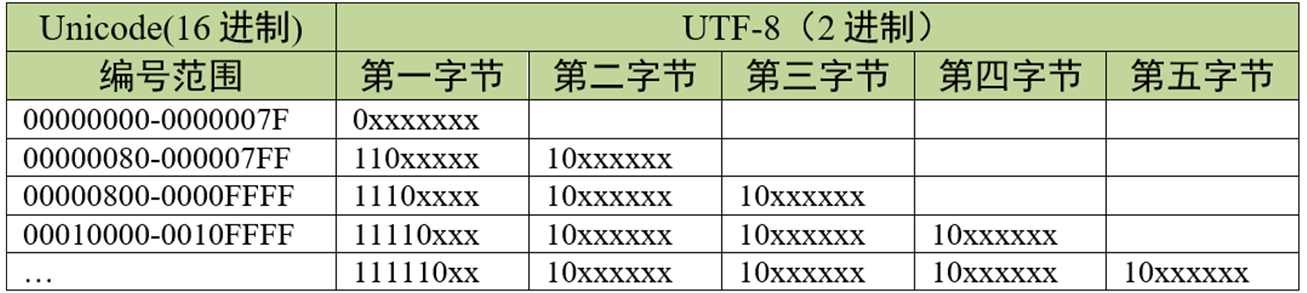
注意:实际上 utf-8 编码长度最大为四个字节,所以最多只能表示 Unicode 编码值的二进制数为 21 位的 Unicode 字符。但是已经能表示所有的 Unicode 字符,因为 Unicode 的最大码位 0x10FFFF 也只有 21 位。
UTF-8 解码的时候以字节为单位去看,如果第一个字节的 bit 位以 0 开头,那就是 ASCII 字符,以单字节进行解析。如果第一个字节的数据位以“110”开头,就按双字节进行解析, 3、 4 字节的解析方法类似。UTF-8 的优点是兼容了 ASCII 码,节约空间,且没有字节顺序的问题,它直接根据第 1 个字节前面数据位中连续的 1 个数决定后面有多少个字节。不过使用 UTF-8 编码汉字平均需要 3 个字节,比 GBK 编码要多一个字节。
2.5.2 实例分析
在上面 2 种方法中,每一个 Unicode 使用 2 字节来表示,这有 3 个缺点:表示的字符数量有限、对于 ASCII 字符有空间浪费、如果文件中有某个字节丢失,这会使得后面所有字符都因为错位而无法显示。使用 UTF8 可以解决上述所有问题。 UTF8 是变长的编码方法,有 2 种 UTF8格式的文件:带有头部、不带头部。

对于其中的 ASCII 字符,在 UTF8 文件中直接用其 ASCII 码来表示,比如上图中的 0x41 表示字符 A。上图中的 3 个字节“ 0xe4 0xb8 0xad”表示的数值是 0x4e2d,对应“中”的 Unicode 码。对于非 ASCII 字符,使用变长的编码:每一个字节的高位都自带长度信息。如下图:
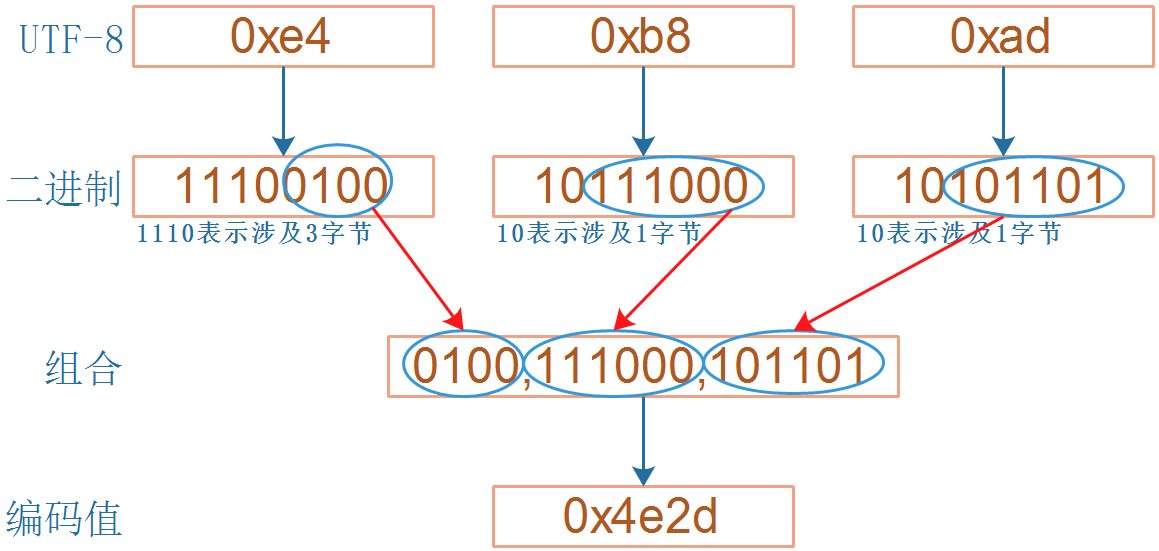
(1)0xe4 的二进制是“ 11100100”,高位有 3 个 1,表示从当前字节起有 3 字节参与表示 Unicode ;
(2)0xb8 的二进制是“10111000”,高位有 1 个 1,表示从当前字节起有 1 字节参与表示 Unicode ;
(3)0xad 的二进制是“10101101”,高位有 1 个 1,表示从当前字节起有 1 字节参与表示 Unicode ;
除去高位的“ 1110”、“ 10”、“ 10”后,剩下的二进制数组合起来得到“ 01001110001101 ”,它就是 0x4e2d,即“中”的 UNICODE 值。使用 UTF8 编码时,即使 TXT 文件中丢失了某些数据,也只会影响到当前字符的显示,后面的字符不受影响。
3. 其他的一些编码格式
3.1 UTF32
对 Unicode 字符集编码,最自然的就是 UTF-32 方式了。编码时,它直接对 Unicode 字符集里的每个字符都用 4 字节来表示,转换方式很简单,直接将字符对应的编号数字转换为 4 字节的二进制数。如表格 UTF-32 编码示例 ,由于 UTF-32 把每个字符都用要 4 字节来存储,因此 UTF-32 不兼容 ASCII 编码,也就是说 ASCII 编码的文件用 UTF-32 标准来打开会成为乱码。

对 UTF-32 数据进行解码的时候,以 4 个字节为单位进行解析即可,根据编码可直接找到 Unicode 字符集中对应编号的字符。UTF-32 的优点是编码简单,解码也很方便,读取编码的时候每次都直接读 4 个字节,不需要加其它的判断。它的缺点是浪费存储空间,大量常用字符的编号只需要 2 个字节就能表示。其次,在存储的时候需要指定字节顺序,是高位字节存储在前 (大端格式),还是低位字节存储在前 (小端格式)。
3.2 UTF-16
针对 UTF-32 的缺点,人们改进出了 UTF-16 的编码方式,如下表:

它采用 2 字节或 4 字节的变长编码方式 (UTF-32 定长为 4 字节)。对 Unicode 字符编号在 0 到 65535 的统一用 2 个字节来表示,将每个字符的编号转换为 2 字节的二进制数,即从 0x0000 到 0xFFFF。而由于 Unicode 字符集在 0xD800-0xDBFF 这个区间是没有表示任何字符的,所以 UTF-16 就利用这段空间,对Unicode 中编号超出 0xFFFF 的字符,利用它们的编号做某种运算与该空间建立映射关系,从而利用该空间表示 4 字节扩展。
注意下面这个字:

TLHH(不支持 GB18030 码的输入法无法找到该字,我们是可搜索它的 Unicode 编号找到这个字)UTF-16 解码时,按两个字节去读取,如果这两个字节不在 0xD800 到 0xDFFF 范围内,那就是双字节编码的字符,以双字节进行解析,找到对应编号的字符。如果这两个字节在 0xD800 到0xDFFF 之间,那它就是四字节编码的字符,以四字节进行解析,找到对应编号的字符。
UTF-16 编码的优点是相对 UTF-32 节约了存储空间,缺点是仍不兼容 ASCII 码,仍有大小端格式问题。
4. BOM
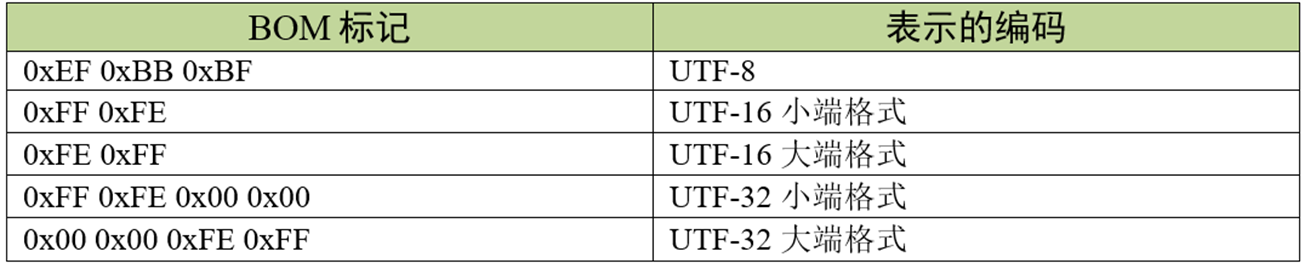
刚才我们了解记事本支持的几种编码格式的时候,有提到过头部这个概念,这是因为 UTF 系列有多种编码方式,而且对于 UTF-16 和 UTF-32 还有大小端的区分,那么计算机软件在打开文档的时候到底应该用什么编码方式去解码呢?有的人就想到在文档最前面加标记,一种标记对应一种编码方式,这些标记就叫做 BOM(Byte Order Mark),它们位于文本文件的开头,见下表:
注意 BOM 是对 Unicode 的几种编码而言的, ANSI 编码没有 BOM。但由于带 BOM 的设计很多规范不兼容,不能跨平台,所以这种带 BOM 的设计没有流行起来。Linux 系统下默认不带 BOM。