LV01-19-C语言-大小端模式
本文主要是C语言基础——大小端模式相关笔记,若笔记中有错误或者不合适的地方,欢迎批评指正😃。
点击查看使用工具及版本
| Windows | windows11 |
| Ubuntu | Ubuntu16.04的64位版本 |
| VMware® Workstation 16 Pro | 16.2.3 build-19376536 |
| SecureCRT | Version 8.7.2 (x64 build 2214) - 正式版-2020年5月14日 |
| 开发板 | 正点原子 i.MX6ULL Linux阿尔法开发板 |
| uboot | NXP官方提供的uboot,NXP提供的版本为uboot-imx-rel_imx_4.1.15_2.1.0_ga(使用的uboot版本为U-Boot 2016.03) |
| linux内核 | linux-4.15(NXP官方提供) |
| STM32开发板 | 正点原子战舰V3(STM32F103ZET6) |
点击查看本文参考资料
| 参考方向 | 参考原文 |
| --- | --- |
先来看一下什么是大端小端,由于我之前学过单片机,所以看到这个概念并不陌生。
一、什么是大小端模式?
大端模式( Big-endian )是指将数据的低位放在内存的高地址上,而数据的高位放在内存的低地址上。
小端模式( Little-endian )是指将数据的低位放在内存的低地址上,而数据的高位放在内存的高地址上。这种存储模式将地址的高低和数据的大小结合起来,高地址存放数值较大的部分,低地址存放数值较小的部分。
二、在内存中的不同
如数据 0x87654321 ,共 4 个字节数据,高位到低位分别为: 0x87 、 0x65 、 0x43 和 0x21 共 4 个字节。假设这个数据存放在 64 位系统下 0x7fff1635a610 地址中,那么它所占用的连续四个字节的空间在大端模式下和小端模式下的存储情况如下图所示。
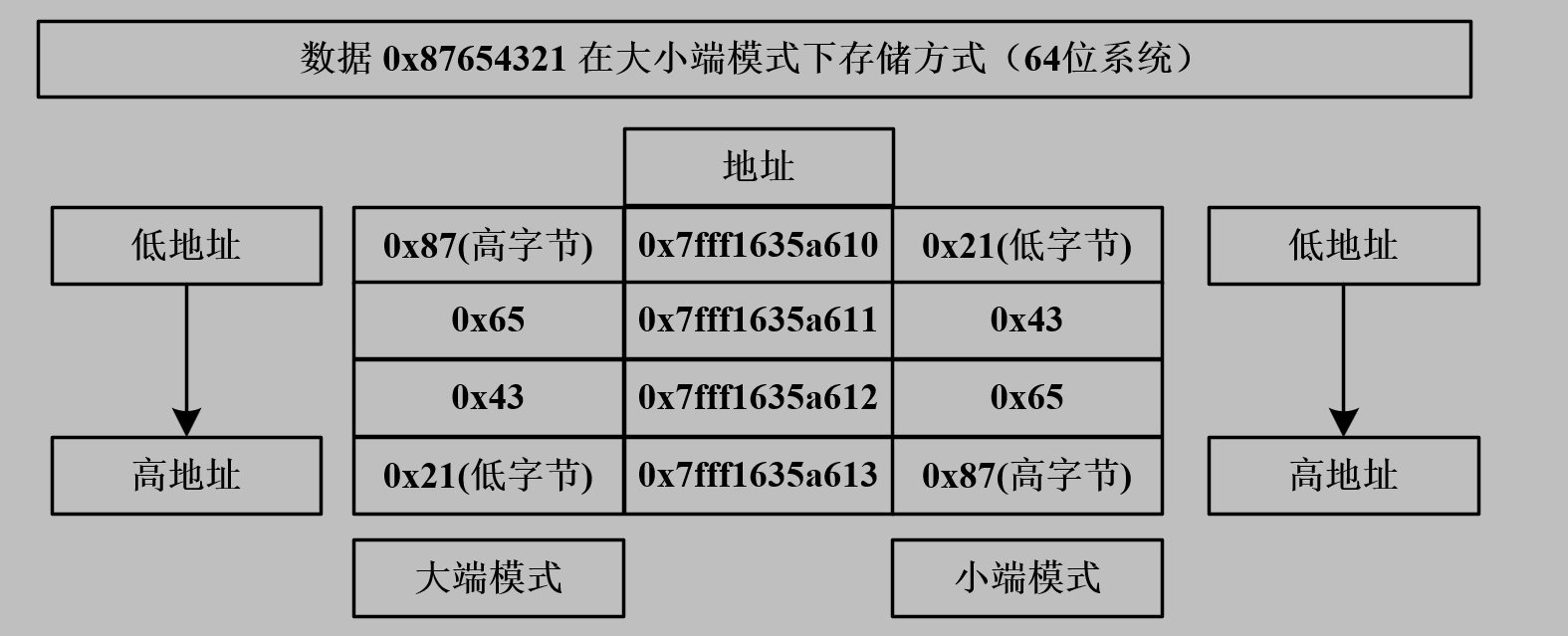
可以看到:
大端模式就是:高地址→低字节,低地址→高字节
小端模式就是:高地址→高字节,低地址→低字节
【记法】高存高,低存低,为小端;高存低,低存高,为大端
三、为什么有大小端?
计算机中的数据是以字节( Byte )为单位存储的,每个地址单元都对应着一个字节,一个字节为 8bit 。
目前 CPU 的位数(就是一次能处理的数据的位数)都超过了 8 位(一个字节), PC 机、服务器的 CPU 基本都是 64 位的,嵌入式系统或单片机系统仍然在使用 32 位和 16 位的 CPU 。
在 C 语言中除了 8bit 的 char 之外,还有 16bit 的 short 型, 32bit 的long型(要看具体的编译器)。对于位数大于 8 位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何存储多个字节的问题。因此就导致了大端存储模式和小端存储模式。
在网上看到有说计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的,所以,计算机的内部处理都是小端字节序。但是,人类还是习惯读写大端字节序,所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
四、如何判断?
那我们的电脑或者是要使用的 CPU 是大端还是小端呢?我们又要如何判断呢?其实我们可以写个测试程序来判断大小端模式。
1. 通过指针判断
int 占 4 个字节,而 char 类型的指针是占一个字节的,如果我们把 int 强传为 char 类型的指针,只会保存一个字节的数据,那么我们只需要判断 char 里面的第一个字节和 int 里面的第一个字节是否是一致即可判断。如果一致则为小端模式,反之为大端模式。
这里以 C 语言为例,
1 |
|
2. 通过共用体判断
共用体中的成员共用一片内存,所以我们可以定义一个int类型成员,再定义一个char类型成员,给int类型成员赋值,然后读char类型成员,这样就可以读低地址中的一个字节数据,若是对应int类型成员数据的高位,说明低地址存了高位,这就是大端模式,相反为小端模式。
1 |
|
五、大小端转换
1.库函数
在C语言库中,有完成大小端转换的函数,他们也被称为字节序转换函数,主要用于网络编程中,因为在网络传输中,一般要求是大端,而inter处理器是小端,network to host理解为大端转小端,而 host to network 理解为小端转大端。
1 | uint32_t htonl(uint32_t hostlong); /* 主机字节序--->网络字节序 */ |
- h 为 host ,表示主机字节顺序;
- n 为 net ,表示网络字节顺序;
- l 表示无符号整型数据;
- s 表示无符号短整型数据。
2.自己实现
思路就是把高位放到低位,低位放到高位,这里通过移位来实现:
1 |
|