怎么保护共享资源,防止竞争?若笔记中有错误或者不合适的地方,欢迎批评指正😃。
点击查看使用工具及版本
PC端开发环境 Windows Windows11 Ubuntu Ubuntu20.04.2的64位版本 VMware® Workstation 17 Pro 17.6.0 build-24238078 终端软件 MobaXterm(Professional Edition v23.0 Build 5042 (license)) Win32DiskImager Win32DiskImager v1.0 Linux开发板环境 Linux开发板 正点原子 i.MX6ULL Linux 阿尔法开发板 uboot NXP官方提供的uboot,使用的uboot版本为U-Boot 2019.04 linux内核 linux-4.19.71(NXP官方提供)
点击查看本文参考资料
点击查看相关文件下载
一、原子操作 1. 什么是原子操作 “原子” 是化学世界中不可再分的最小微粒, 一切物质都由原子组成。 在 Linux 内核中的原子操作可以理解为“不可被拆分的操作” , 就是不能被更高等级中断抢夺优先的操作。
一般原子操作用于变量或者位操作。假如现在要对无符号整形变量 a 赋值,值为 3,对于 C 语言来讲很简单,直接就是:
但是 C 语言要先编译为成汇编指令, ARM 架构不支持直接对寄存器进行读写操作,比如要借助寄存器 R0、 R1 等来完成赋值操作。假设变量 a 的地址为 0X3000000,“a=3”这一行 C语言可能会被编译为如下所示的汇编代码:
1 2 3 ldr r0, =0X30000000 /* 变量 a 地址 */ ldr r1, = 3 /* 要写入的值 */ str r1, [r0] /* 将 3 写入到 a 变量中 */
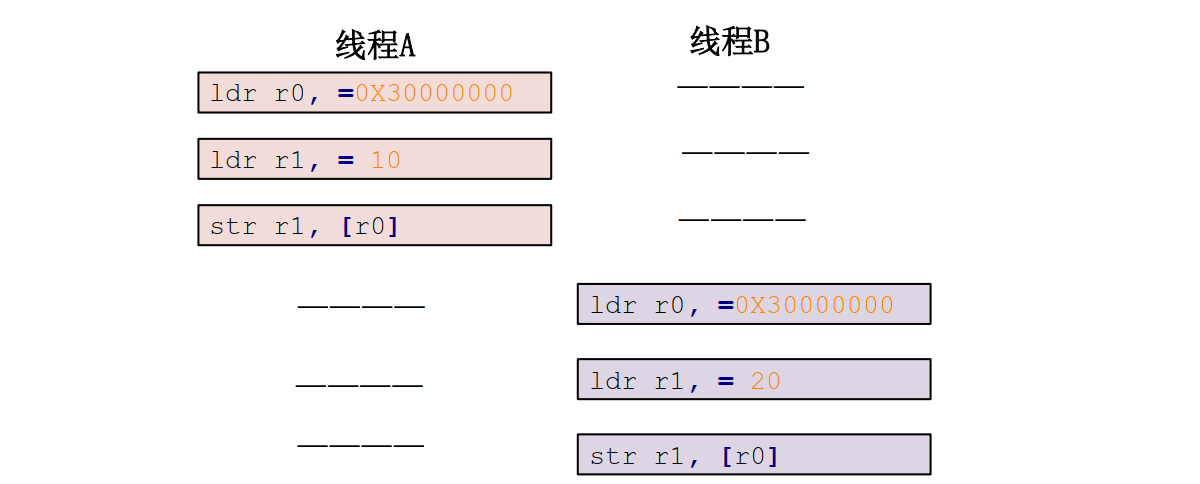
只是一个简单的举例说明,实际的结果要比示例代码复杂的多。从上述代码可以看出, C 语言里面简简单单的一句“a=3”,编译成汇编文件以后变成了 3 句,那么程序在执行的时候肯定是按照汇编语句一条一条的执行。假设现在线程 A要向 a 变量写入 10 这个值,而线程 B 也要向 a 变量写入 20 这个值,我们理想中的执行顺序如图所示:
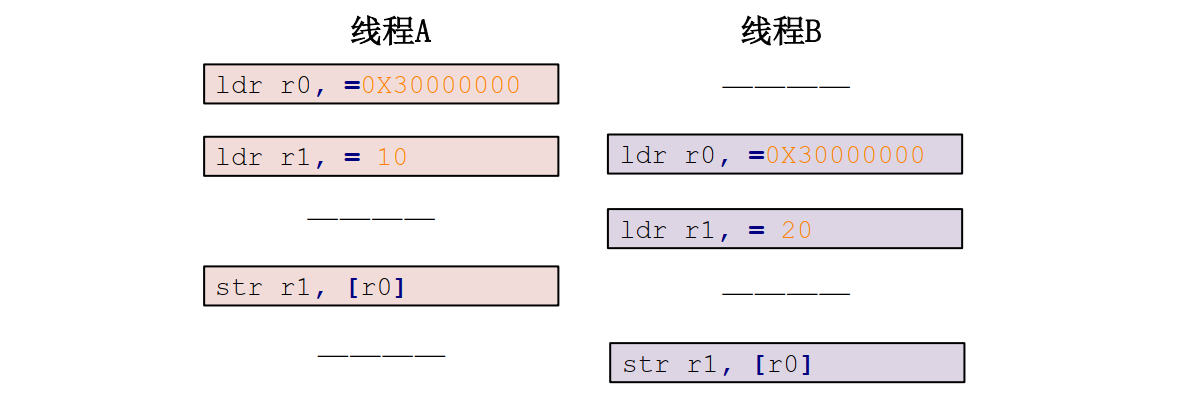
按照上图所示的流程,确实可以实现线程 A 将 a 变量设置为 10,线程 B 将 a 变量设置为 20。但是实际上的执行流程可能如下所示:
按照图这个图所示的流程,线程 A 最终将变量 a 设置为了 20,而并不是要求的 10!线程B 没有问题。这就是一个最简单的设置变量值的并发与竞争的例子,要解决这个问题就要保证那三行汇编指令作为一个整体运行,也就是作为一个原子存在 。
2. 相关数据结构与API Linux 内核提供了一组原子操作 API 函数来完成此功能, Linux 内核提供了两组原子操作 API 函数,一组是对整形变量进行操作的,一组是对位进行操作的,我们接下来看一下这些 API 函数和相关的数据结构。
在 Linux 内核中使用 atomic_t 和 atomic64_t 结构体分别来完成 32 位系统和 64 位系统的整形数据原子操作 , 两个结构体定义在 types.h - include/linux/types.h 文件中
1 2 3 4 5 6 7 8 9 typedef struct { int counter; } atomic_t ; #ifdef CONFIG_64BIT typedef struct { long counter; } atomic64_t ; #endif
2.2 原子整形操作API 如果要使用原子操作 API 函数,首先要先定义一个 atomic_t 的变量,如下所示 :
也可以在定义原子变量的时候给原子变量赋初值,如下所示 :
1 atomic_t b = ATOMIC_INIT(0 );
原子变量有了,接下来就是对原子变量进行操作,比如读、写、增加、减少等等, Linux 内核提供了大量的原子操作 API 函数,其实这些大部分都是宏:
函数
描述
ATOMIC_INIT(int i)
定义原子变量的时候对其初始化, 赋值为 i
int atomic_read(atomic_t *v)
读取 v 的值, 并且返回。
void atomic_set(atomic_t *v, int i)
向原子变量 v 写入 i 值。
void atomic_add(int i, atomic_t *v)
原子变量 v 加上 i 值。
void atomic_sub(int i, atomic_t *v)
原子变量 v 减去 i 值。
void atomic_inc(atomic_t *v)
原子变量 v 加 1
void atomic_dec(atomic_t *v)
原子变量 v 减 1
int atomic_dec_return(atomic_t *v)
原子变量 v 减 1, 并返回 v 的值。
int atomic_inc_return(atomic_t *v)
原子变量 v 加 1, 并返回 v 的值。
int atomic_sub_and_test(int i, atomic_t *v)
原子变量 v 减 i, 如果结果为 0 就返回真, 否则返回假
int atomic_dec_and_test(atomic_t *v)
原子变量 v 减 1, 如果结果为 0 就返回真, 否则返回假
int atomic_inc_and_test(atomic_t *v)
原子变量 v 加 1, 如果结果为 0 就返回真, 否则返回假
int atomic_add_negative(int i, atomic_t *v)
原子变量 v 加 i, 如果结果为负就返回真, 否则返回
这些都分散定义在这些头文件,它们是:
atomic.h - include/linux/atomic.h
atomic.h - include/asm-generic/atomic.h
相应的也提供了 64 位原子变量的操作 API 函数,这里我们就不详细了解,和上表中的 API 函数有用法一样,只是将“atomic_”前缀换为“atomic64_”,将 int 换为 long long。如果使用的是 64 位的 SOC,那么就要使用 64 位的原子操作函数。原子变量和相应的 API 函数使用起来很简单,参考如下:
1 2 3 4 atomic_t v = ATOMIC_INIT(0 ); atomic_set (&v, 10 ); atomic_read (&v); atomic_inc (&v);
2.3 原子位操作 API 位操作也是很常用的操作, Linux 内核也提供了一系列的原子位操作 API 函数,只不过原子位操作不像原子整形变量那样有个 atomic_t 的数据结构,原子位操作是直接对内存进行操作, API 函数如下:
函数
描述
void set_bit(int nr, void *p)
将 p 地址的第 nr 位置 1。
void clear_bit(int nr,void *p)
将 p 地址的第 nr 位清零。
void change_bit(int nr, void *p)
将 p 地址的第 nr 位进行翻转。
int test_bit(int nr, void *p)
获取 p 地址的第 nr 位的值。
int test_and_set_bit(int nr, void *p)
将 p 地址的第 nr 位置 1,并且返回 nr 位原来的值。
int test_and_clear_bit(int nr, void *p)
将 p 地址的第 nr 位清零,并且返回 nr 位原来的值。
int test_and_change_bit(int nr, void *p)
将 p 地址的第 nr 位翻转,并且返回 nr 位原来的值。
Tips:
atomic.h - include/asm-generic/bitops/atomic.h
non-atomic.h - include/asm-generic/bitops/non-atomic.h
3. 原子操作demo 3.1 demo源码 在 xxx_open()函数和 xxx_release()函数中加入原子整形变量 v 的赋值代码, 并且在 open()函数中加入原子整形变量 v 的判断代码, 从而实现同一时间内只允许一个应用打开该设备节点, 以此来防止共享资源竞争的产生。
07_concurrency/03_atomic · 苏木/imx6ull-driver-demo - 码云 - 开源中国
3.2 开发板验证 我们将编译得到的sdriver_demo.ko、app_demo.out拷贝到开发板。
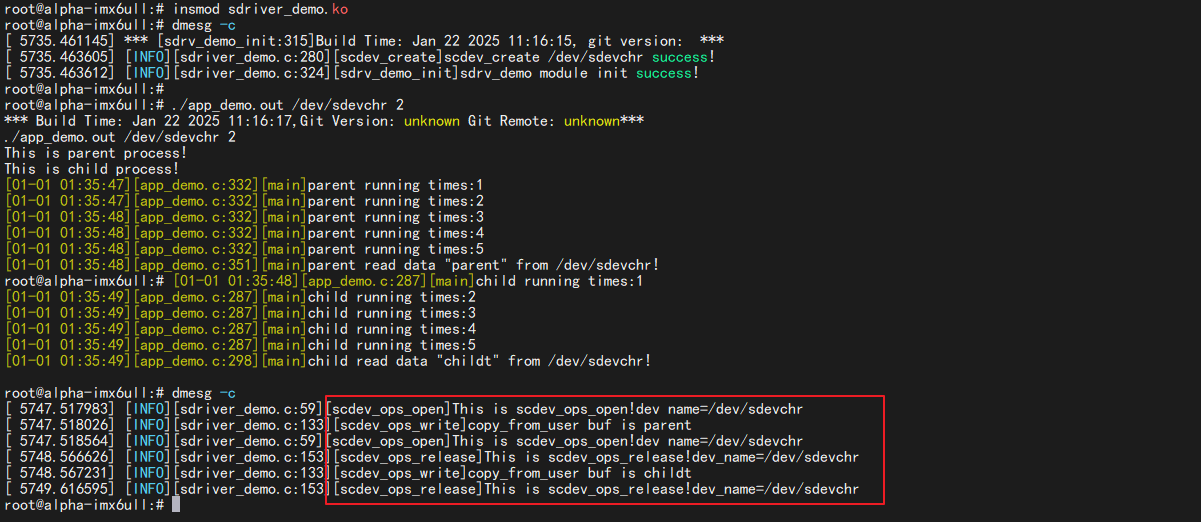
1 ./app_demo.out /dev/sdevchr 2 0 sumu1
在open的时候,原子变量变为0,在release的时候,原子变量的值恢复到1。
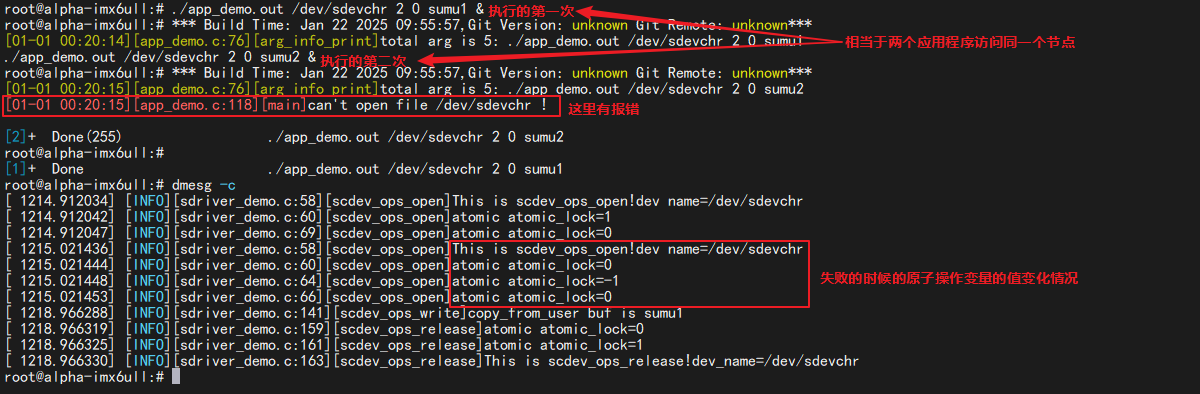
1 2 ./app_demo.out /dev/sdevchr 2 0 sumu1 & ./app_demo.out /dev/sdevchr 2 0 sumu2 &
可以看到应用程序在打开第二次 /dev/sdevchr 文件的时候, 出现了“can’t open file /dev/sdevchr !”打印, 证明文件打开失败, 只有在第一个应用关闭相应的文件之后, 下一个应用才能打开, 通过限制同一时间内设备访问数量, 来对共享资源进行保护。
二、自旋锁 1. 什么是自旋锁 1.1 自旋锁的基本概念 原子操作只能对整形变量或者位进行保护,但是,在实际的使用环境中怎么可能只有整形变量或位这么简单的临界区呢?
举个例子,设备结构体变量就不是整型变量,我们对于结构体中成员变量的操作也要保证原子性,在线程 A 对结构体变量使用期间,应该禁止其他的线程来访问此结构体变量,这些工作原子操作都不能胜任,这个时候怎么办?这就到了这一部分要学习的自旋锁了。
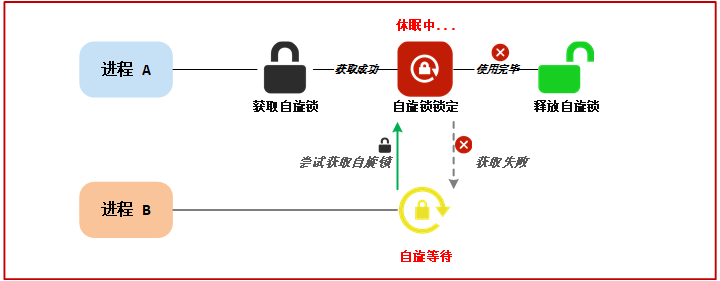
自旋锁是为了保护共享资源提出的一种锁机制。 自旋锁(spin lock) 是一种非阻塞锁, 也就是说, 如果某线程需要获取锁, 但该锁已经被其他线程占用时, 该线程不会被挂起, 而是在不断的消耗 CPU 资源, 不停的试图获取锁。
也就是,当一个线程要访问某个共享资源的时候首先要先获取相应的锁, 锁只能被一个线程持有,只要此线程不释放持有的锁,那么其他的线程就不能获取此锁。对于自旋锁而言,如果自旋锁正在被线程 A 持有,线程 B 想要获取自旋锁,那么线程 B 就会处于忙 循环-旋转-等待 状态,线程 B 不会进入休眠状态或者说去做其他的处理,而是会一直傻傻的在那里“转圈圈”的等待锁可用。
比如现在有个公用电话亭,一次肯定只能进去一个人打电话,现在电话亭里面有人正在打电话,相当于获得了自旋锁。此时我们到了电话亭门口,因为里面有人,所以我们不能进去打电话,相当于没有获取自旋锁,这个时候我们肯定是站在原地等待,我们可能因为无聊的等待而转圈圈消遣时光,反正就是哪里也不能去,要一直等到里面的人打完电话出来。终于,里面的人打完电话出来了,相当于释放了自旋锁,这个时候我们就可以使用电话亭打电话了,相当于获取到了自旋锁。
1.2 自旋锁的实现 linux上的自旋锁有三种实现:
(1)在单cpu,不可抢占内核中,自旋锁为空操作。
(2)在单cpu,可抢占内核中,自旋锁实现为“禁止内核抢占”,并不实现“自旋”。
(3)在多cpu,可抢占内核中,自旋锁实现为“禁止内核抢占” + “自旋”。
2. 短时间加锁场景? 在有些场景中, 同步资源(用来保持一致性的两个或多个资源)的锁定时间很短, 为了这一小段时间去切换线程, 线程挂起和恢复现场的花费可能会让系统得不偿失。 如果计算机有多个CPU 核心, 能够让两个或以上的线程同时并行执行, 这样我们就可以让后面那个请求锁的线程不放弃 CPU 的执行时间, 直到持有锁的线程释放锁, 后面请求锁的线程才可以获取锁。
为了让后面那个请求锁的线程“稍等一下”, 我们需让它进行自旋, 如果在自旋完成后前面锁定同步资源的线程已经释放了锁, 那么该线程便不必阻塞, 并且直接获取同步资源, 从而避免切换线程的开销。 这就是自旋锁。
从这里我们可以看到自旋锁的一个缺点:那就等待自旋锁的线程会一直处于自旋状态,这样会浪费处理器时间,降低系统性能,所以自旋锁的持有时间不能太长 。自旋锁适用于短时期的轻量级加锁,如果遇到需要长时间持有锁的场景那就需要换其他的方法了,我们后面再说。
3. 相关数据结构与API Linux 内核使用结构体 struct spinlock 表示自旋锁:
1 2 3 4 5 6 7 8 9 10 11 12 13 typedef struct spinlock { union { struct raw_spinlock rlock ; #ifdef CONFIG_DEBUG_LOCK_ALLOC # define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map)) struct { u8 __padding[LOCK_PADSIZE]; struct lockdep_map dep_map ; }; #endif }; } spinlock_t ;
在使用自旋锁之前,肯定要先定义一个自旋锁变量,定义方法如下所示:
3.2 自旋锁相关 API 自旋锁相关函数定义在 spinlock.h - include/linux/spinlock.h :
函数
描述
DEFINE_SPINLOCK(spinlock_t lock)
定义并初始化一个自选变量。
int spin_lock_init(spinlock_t *lock)
初始化自旋锁。
void spin_lock(spinlock_t *lock)
获取指定的自旋锁,也叫做加锁。
void spin_unlock(spinlock_t *lock)
释放指定的自旋锁。
int spin_trylock(spinlock_t *lock)
尝试获取指定的自旋锁,如果没有获取到就返回 0
int spin_is_locked(spinlock_t *lock)
检查指定的自旋锁是否被获取,如果没有被获取就返回非 0,否则返回 0。
表中的自旋锁API函数适用于SMP或支持抢占的单CPU下线程之间的并发访问,也就是用于线程与线程之间,被自旋锁保护的临界区一定不能调用任何能够引起睡眠和阻塞的API 函数,否则的话会可能会导致死锁 现象的发生。
4. 其他类型的锁 在自旋锁的基础上还衍生出了其他特定场合使用的锁,这些锁在驱动中其实用的不多,更多的是在 Linux 内核中使用。
4.1 读写自旋锁 4.1.1 基本概念 现在有个学生信息表,此表存放着学生的年龄、家庭住址、班级等信息,此表可以随时被修改和读取。此表肯定是数据,那么必须要对其进行保护,如果我们现在使用自旋锁对其进行保护。每次只能一个读操作或者写操作,但是,实际上此表是可以并发读取的。只需要保证在修改此表的时候没人读取,或者在其他人读取此表的时候没有人修改此表就行了。也就是此表的读和写不能同时进行,但是可以多人并发的读取此表。像这样,当某个数据结构符合读/写或生产者/消费者模型的时候就可以使用读写自旋锁。
读写自旋锁为读和写操作提供了不同的锁,一次只能允许一个写操作,也就是只能一个线程持有写锁,而且不能进行读操作。但是当没有写操作的时候允许一个或多个线程持有读锁,可以进行并发的读操作。
4.1.2 数据结构 Linux 内核使用 rwlock_t 结构体表示读写锁,结构体定义如下:
1 2 3 4 5 6 7 8 9 10 typedef struct { arch_rwlock_t raw_lock; #ifdef CONFIG_DEBUG_SPINLOCK unsigned int magic, owner_cpu; void *owner; #endif #ifdef CONFIG_DEBUG_LOCK_ALLOC struct lockdep_map dep_map ; #endif } rwlock_t ;
4.1.3 相关API 读写锁操作 API 函数分为两部分,一个是给读使用的,一个是给写使用的,这些 API 函数如下:
函数
描述
DEFINE_RWLOCK(rwlock_t lock)
定义并初始化读写锁
void rwlock_init(rwlock_t *lock)
初始化读写锁。
函数
描述
void read_lock(rwlock_t *lock)
获取读锁。
void read_unlock(rwlock_t *lock)
释放读锁。
void read_lock_irq(rwlock_t *lock)
禁止本地中断,并且获取读锁。
void read_unlock_irq(rwlock_t *lock)
打开本地中断,并且释放读锁。
void read_lock_irqsave(rwlock_t *lock, unsigned long flags)
保存中断状态,禁止本地中断,并获取读锁。
void read_unlock_irqrestore(rwlock_t *lock, unsigned long flags)
将中断状态恢复到以前的状态,并且激活本地中断,释放读锁。
void read_lock_bh(rwlock_t *lock)
关闭下半部,并获取读锁。
void read_unlock_bh(rwlock_t *lock)
打开下半部,并释放读锁。
函数
描述
void write_lock(rwlock_t *lock)
获取写锁。
void write_unlock(rwlock_t *lock)
释放写锁。
void write_lock_irq(rwlock_t *lock)
禁止本地中断,并且获取写锁。
void write_unlock_irq(rwlock_t *lock)
打开本地中断,并且释放写锁。
void write_lock_irqsave(rwlock_t *lock, unsigned long flags)
保存中断状态,禁止本地中断,并获取写锁。
void write_unlock_irqrestore(rwlock_t *lock, unsigned long flags)
将中断状态恢复到以前的状态,并且激活本地中断,释放读锁。
void write_lock_bh(rwlock_t *lock)
关闭下半部,并获取读锁。
void write_unlock_bh(rwlock_t *lock)
打开下半部,并释放读锁。
4.2 顺序锁 4.2.1 基本概念 顺序锁在读写锁的基础上衍生而来的,使用读写锁的时候读操作和写操作不能同时进行。使用顺序锁的话可以允许在写的时候进行读操作,也就是实现同时读写,但是不允许同时进行并发的写操作。虽然顺序锁的读和写操作可以同时进行,但是如果在读的过程中发生了写操作,最好重新进行读取,保证数据完整性。顺序锁保护的资源不能是指针,因为如果在写操作的时候可能会导致指针无效,而这个时候恰巧有读操作访问指针的话就可能导致意外发生,比如读取野指针导致系统崩溃。
4.2.2 数据结构 Linux 内核使用 seqlock_t 结构体表示顺序锁 :
1 2 3 4 typedef struct { struct seqcount seqcount ; spinlock_t lock; } seqlock_t ;
4.2.3 相关API
函数
描述
DEFINE_SEQLOCK(seqlock_t sl)
定义并初始化顺序锁
void seqlock_ini seqlock_t *sl)
初始化顺序锁。
函数
描述
void write_seqlock(seqlock_t *sl)
获取写顺序锁。
void write_sequnlock(seqlock_t *sl)
释放写顺序锁。
void write_seqlock_irq(seqlock_t *sl)
禁止本地中断,并且获取写顺序锁
void write_sequnlock_irq(seqlock_t *sl)
打开本地中断,并且释放写顺序锁。
void write_seqlock_irqsave(seqlock_t *sl, unsigned long flags)
保存中断状态,禁止本地中断,并获取写顺序锁。
void write_sequnlock_irqrestore(seqlock_t *sl, unsigned long flags)
将中断状态恢复到以前的状态,并且激活本地中断,释放写顺序锁。
void write_seqlock_bh(seqlock_t *sl)
关闭下半部,并获取写读锁。
void write_sequnlock_bh(seqlock_t *sl)
打开下半部,并释放写读锁。
函数
描述
unsigned read_seqbegin(const seqlock_t *sl)
读单元访问共享资源的时候调用此函数,此函数会返回顺序锁的顺序号。
unsigned read_seqretry(const seqlock_t *sl, unsigned start)
读结束以后调用此函数检查在读的过程中有没有对资源进行写操作,如果有的话就要重读
5. 死锁问题? 5.1 什么是死锁 死锁是指两个或多个事物在同一资源上相互占用, 并请求锁定对方的资源, 从而导致恶性循环的现象。 当多个进程因竞争资源而造成的一种僵局(互相等待) , 若无外力作用, 这些进程都将无法向前推进, 这种情况就是死锁。
5.2 进程切换
在非抢占式内核中,如果一个进程在内核态运行,其只有在以下两种情况会被切换:
(1)其运行完成(返回用户空间)
(2)主动让出cpu(即主动调用schedule或内核中的任务阻塞——这同样也会导致调用schedule)
在抢占式内核中,如果一个进程在内核态运行,其只有在以下四种情况会被切换:
(1)其运行完成(返回用户空间)
(2)主动让出cpu(即主动调用schedule或内核中的任务阻塞——这同样也会导致调用schedule)
(3)当从中断处理程序正在执行,且返回内核空间之前(此时可抢占标志premptcount须为0) 。
(4)当内核代码再一次具有可抢占性的时候,如解锁及使能软中断等。
禁止内核抢占只是关闭“可抢占标志”,而不是禁止进程切换。显式使用schedule或进程阻塞(此也会导致调用schedule)时,还是会发生进程调度的。
5.3 自旋锁的死锁 5.3.1 情况一 对于多核抢占与多核非抢占的情况,在使用自旋锁时,其情况基本是一致的。因为在多核抢占的情况下,使用自旋锁会禁止内核抢占,这样多核抢占就相当于多核非抢占的情况。
自旋锁会自动禁止抢占,也就说当线程 A得到锁以后会暂时禁止内核抢占。如果线程 A 在持有锁期间进入了休眠状态,那么进程 A 会自动放弃 CPU 使用权。进程 B 开始运行,进程 B 也想要获取锁,但是此时锁被 A 进程持有,而且内核抢占还被禁止了!进程 B 无法被调度出去,那么进程 A 就无法运行,锁也就无法释放,好了,死锁发生了! 如下图:
在单cpu内核上不会出现上述情况,因为单cpu上的自旋锁实际没有“自旋功能”。
相应的解决办法是, 在自旋锁的使用过程中要尽可能短的时间内拥有自旋锁, 而且不能在临界区中调用导致线程休眠的函数。
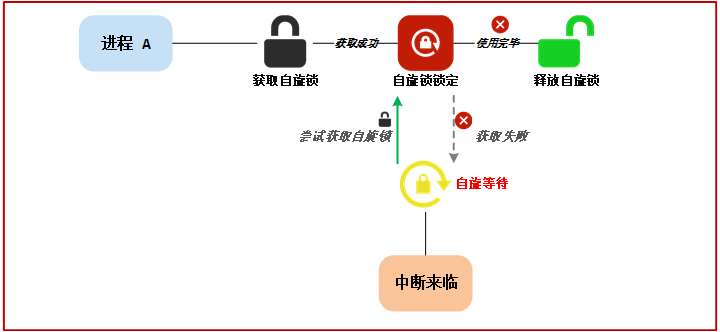
5.3.2 情况二 第二种情况是进程 A 拥有自旋锁, 中断到来, CPU 执行中断函数, 进程A切换到中断处理函数, 在中断处理函数中又需要获得自旋锁, 访问共享资源, 此时中断处理函数无法获得锁, 只能自旋, 如下图所示:
对于中断引发的死锁, 最好的解决方法就是在获取锁之前关闭本地中断, Linux 内核在 spinlock.h - include/linux/spinlock.h 文件中提供了相应的 API 函数 :
函数
描述
void spin_lock_irq(spinlock_t *lock)
禁止本地中断, 并获取自旋锁。
void spin_unlock_irq(spinlock_t *lock)
激活本地中断, 并释放自旋锁。
void spin_lock_irqsave(spinlock_t *lock, unsigned long flags)
恢复中断状态, 关闭中断并获取自旋锁。
void spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags)
将中断状态恢复到以前的状态, 打开中断并释放自旋锁
void spin_lock_bh(spinlock_t *lock)
关闭下半部, 获取自旋锁
void spin_unlock_bh(spinlock_t *lock)
打开下半部, 获取自旋锁
由于 Linux 内核运行是非常复杂的, 很难确定某个时刻的中断状态, 因此建议使用spin_lock_irqsave 、spin_unlock_irqrestore, 因为这一组函数会保存中断状态, 在释放锁的时候会恢复中断状态。
6. 注意事项 ①、因为在等待自旋锁的时候处于“自旋”状态,因此锁的持有时间不能太长,一定要短,否则的话会降低系统性能。如果临界区比较大,运行时间比较长的话要选择其他的并发处理方式,比如稍后要学习的信号量和互斥体。
②、自旋锁保护的临界区内不能调用任何可能导致线程休眠的 API 函数,否则的话可能导致死锁。
③、不能递归申请自旋锁,因为一旦通过递归的方式申请一个我们正在持有的锁,那么我们就必须“自旋”,等待锁被释放,然而正处于“自旋”状态,根本没法释放锁。结果就是自己把自己锁死了!
④、在编写驱动程序的时候我们必须考虑到驱动的可移植性,因此不管用的是单核的还是多核的 SOC,都将其当做多核 SOC 来编写驱动程序。
7. 自旋锁demo 加了锁之后,内部休眠太久的话,会卡死并产生崩溃,崩溃应该是死锁导致的,但是要是把锁加在内部循环的地方,会有不一样的效果,大概可以演示自旋锁的效果。这里有两个正常demo,两个异常的demo,异常的两个可以当做死锁的实例。
7.1 正常使用的demo1 7.1.1 demo源码 7.1.1.1 sdriver_demo.c 点击查看详情
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 #include <linux/init.h> #include <linux/kernel.h> #include <linux/module.h> #include <linux/fs.h> #include <linux/cdev.h> #include <linux/uaccess.h> #include <linux/delay.h> #include "./timestamp_autogenerated.h" #include "./version_autogenerated.h" #include "./sdrv_common.h" #ifndef PRT #define PRT printk #endif #ifndef PRTE #define PRTE printk #endif #define CHRDEV_NAME "sdev" #define CLASS_NAME "sclass" #define DEVICE_NAME "sdevchr" #define BUFSIZE 32 #define CMD_TEST0 _IO('S' , 0) #define CMD_TEST1 _IOW('S' , 1, int) #define CMD_TEST2 _IOR('S' , 2, int) #define CMD_TEST3 _IOW('S' , 3, int) struct __CMD_TEST { int a; int b; int c; }; typedef struct __CHAR_DEVICE { dev_t dev_num; struct cdev s_cdev ; struct class *class ; struct device *device ; char buf[BUFSIZE]; ulong run_cnt; spinlock_t s_lock; } _CHAR_DEVICE; _CHAR_DEVICE g_chrdev = {0 }; static int scdev_ops_open (struct inode *pInode, struct file *pFile) { PRT("This is scdev_ops_open!\n" ); pFile->private_data = &g_chrdev; return 0 ; } static ssize_t scdev_ops_read (struct file *pFile, char __user *buf, size_t size, loff_t *off) { loff_t offset = *off; size_t count = size; _CHAR_DEVICE *p_chrdev=(_CHAR_DEVICE *)pFile->private_data; if (offset > BUFSIZE) { return 0 ; } if (count > BUFSIZE - offset) { count = BUFSIZE - offset; } if (copy_to_user(buf, p_chrdev->buf + offset, count)) { PRT("copy_to_user error!\n" ); return -1 ; } #if 0 int i = 0 ; for (i = 0 ; i < BUFSIZE; i++) { PRT("buf[%d] %c\n" , i, p_chrdev->buf[i]); } PRT("read offset is %llu, count is %d\n" , offset, count); #endif *off = *off + count; return count; } static ssize_t scdev_ops_write (struct file *pFile, const char __user *buf, size_t size, loff_t *off) { loff_t offset = *off; size_t count = size; int i = 0 ; _CHAR_DEVICE *p_chrdev=(_CHAR_DEVICE *)pFile->private_data; if (offset > BUFSIZE) { return 0 ; } if (count > BUFSIZE - offset) { count = BUFSIZE - offset; } if (copy_from_user(p_chrdev->buf + offset, buf, count)) { PRT("copy_to_user error \n" ); return -1 ; } kstrtoul_from_user(buf, count, 10 , &p_chrdev->run_cnt); spin_lock(&p_chrdev->s_lock); for (i = p_chrdev->run_cnt; i > 0 ; i--) { PRT("addr=0x%px run_cnt=%ld current is %d\n" , &p_chrdev->run_cnt, p_chrdev->run_cnt, i); mdelay(200 ); } spin_unlock(&p_chrdev->s_lock); #if 0 int i = 0 ; for (i = 0 ; i < BUFSIZE; i++) { PRT("buf[%d] %c\n" , i, p_chrdev->buf[i]); } PRT("write offset is %llu, count is %d\n" , offset, count); #endif *off = *off + count; return count; } static int scdev_ops_release (struct inode *pInode, struct file *pFile) { PRT("This is scdev_ops_release!\n" ); return 0 ; } static loff_t scdev_ops_llseek (struct file *pFile, loff_t offset, int whence) { loff_t new_offset = 0 ; switch (whence) { case SEEK_SET: if (offset < 0 || offset > BUFSIZE) { return -EINVAL; } new_offset = offset; break ; case SEEK_CUR: if ((pFile->f_pos + offset < 0 ) || (pFile->f_pos + offset > BUFSIZE)) { return -EINVAL; } new_offset = pFile->f_pos + offset; break ; case SEEK_END: if (pFile->f_pos + offset < 0 ) { return -EINVAL; } new_offset = BUFSIZE + offset; break ; default : break ; } pFile->f_pos = new_offset; return new_offset; } static long scdev_ops_ioctl (struct file *pFile, unsigned int cmd, unsigned long arg) { int val = 0 ; switch (cmd) { case CMD_TEST0: PRT("this is CMD_TEST0\n" ); break ; case CMD_TEST1: PRT("this is CMD_TEST1\n" ); PRT("arg is %ld\n" ,arg); break ; case CMD_TEST2: val = 1 ; PRT("this is CMD_TEST2\n" ); if (copy_to_user((int *)arg, &val, sizeof (val)) != 0 ) { PRT("copy_to_user error \n" ); } break ; case CMD_TEST3: { struct __CMD_TEST cmd_test3 =0 }; if (copy_from_user(&cmd_test3, (int *)arg, sizeof (cmd_test3)) != 0 ) { PRT("copy_from_user error\n" ); } PRT("cmd_test3.a = %d\n" , cmd_test3.a); PRT("cmd_test3.b = %d\n" , cmd_test3.b); PRT("cmd_test3.c = %d\n" , cmd_test3.c); break ; } default : break ; } return 0 ; } static struct file_operations g_scdev_ops = .owner = THIS_MODULE, .open = scdev_ops_open, .read = scdev_ops_read, .write = scdev_ops_write, .release = scdev_ops_release, .llseek = scdev_ops_llseek, .unlocked_ioctl = scdev_ops_ioctl, }; static int scdev_create (_CHAR_DEVICE *p_chrdev) { int ret; int major, minor; spin_lock_init(&p_chrdev->s_lock); ret = alloc_chrdev_region(&p_chrdev->dev_num, 0 , 1 , CHRDEV_NAME); if (ret < 0 ) { PRTE("alloc_chrdev_region is error!ret=%d\n" , ret); goto err_alloc_devno; } major = MAJOR(p_chrdev->dev_num); minor = MINOR(p_chrdev->dev_num); PRT("major is %d, minor is %d !\n" , major, minor); cdev_init(&p_chrdev->s_cdev, &g_scdev_ops); p_chrdev->s_cdev.owner = THIS_MODULE; ret = cdev_add(&p_chrdev->s_cdev, p_chrdev->dev_num, 1 ); if (ret < 0 ) { PRTE("cdev_add is error !ret=%d\n" , ret); goto err_cdev_add; } p_chrdev->class = if (IS_ERR(p_chrdev->class)) { ret = PTR_ERR(p_chrdev->class); goto err_class_create; } p_chrdev->device = device_create(p_chrdev->class, NULL , p_chrdev->dev_num, NULL , "%s" , DEVICE_NAME); if (IS_ERR(p_chrdev->device)) { ret = PTR_ERR(p_chrdev->class); goto err_device_create; } PRT("scdev_create /dev/%s success!\n" , DEVICE_NAME); return 0 ; err_device_create: class_destroy(p_chrdev->class); err_class_create: cdev_del(&p_chrdev->s_cdev); err_cdev_add: unregister_chrdev_region(p_chrdev->dev_num, 1 ); err_alloc_devno: return ret; } static void scdev_destroy (_CHAR_DEVICE *p_chrdev) { cdev_del(&p_chrdev->s_cdev); unregister_chrdev_region(p_chrdev->dev_num, 1 ); device_destroy(p_chrdev->class, p_chrdev->dev_num); class_destroy(p_chrdev->class); PRT("scdev_destroy success!\n" ); } static __init int sdrv_demo_init (void ) { int ret = 0 ; printk("*** [%s:%d]Build Time: %s %s, git version:%s ***\n" , __FUNCTION__, __LINE__, KERNEL_KO_DATE, KERNEL_KO_TIME, KERNEL_KO_VERSION); ret = scdev_create(&g_chrdev); if (ret < 0 ) { PRT("Failed to scdev_create!ret=%d\n" , ret); goto err_scdev_create; } PRT("sdrv_demo module init success!\n" ); return 0 ; err_scdev_create: return ret; } static __exit void sdrv_demo_exit (void ) { scdev_destroy(&g_chrdev); PRT("sdrv_demo module exit!\n" ); } module_init(sdrv_demo_init); module_exit(sdrv_demo_exit); MODULE_LICENSE("GPL v2" ); MODULE_AUTHOR("sumu" ); MODULE_DESCRIPTION("Description" ); MODULE_ALIAS("module's other name" );
7.1.1.2 app_demo.c 点击查看详情
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <fcntl.h> #include <sys/types.h> #include <sys/stat.h> #include <sys/ioctl.h> #define BUFSIZE 32 void usage_info (void ) { printf ("\n" ); printf ("+++++++++++++++++++++++++++++++++++++++++\n" ); printf ("+ help information @sumu +\n" ); printf ("+++++++++++++++++++++++++++++++++++++++++\n" ); printf ("help:\n" ); printf ("use format: ./app_name /dev/device_name arg1 ... \n" ); printf (" ./app_demo.out /dev/sdevice run_cnt # run_cnt为运行次数 \n" ); printf ("\n" ); printf ("command info:\n" ); printf (" (1)load module : insmod module_name.ko\n" ); printf (" (2)unload module: rmmod module_name.ko\n" ); printf (" (3)show module : lsmod\n" ); printf (" (4)view device : cat /proc/devices\n" ); printf (" (5)create device node: mknod /dev/device_name c major_num secondary_num \n" ); printf (" (6)show device node : ls /dev/device_name \n" ); printf (" (7)show device vlass : ls /sys/class \n" ); printf ("+++++++++++++++++++++++++++++++++++++++++\n" ); } int main (int argc, char *argv[]) { int ret = 0 ; int fd = -1 ; pid_t pid = 0 ; char *filename = NULL ; char writebuf[BUFSIZE] = {0 }; printf ("*** Build Time: %s %s,Git Version: %s Git Remote: %s***\n" , __DATE__, __TIME__, GIT_VERSION, GIT_PATH); if (argc <= 2 ) { usage_info(); return -1 ; } filename = argv[1 ]; snprintf (writebuf, sizeof (writebuf), "%s" , argv[2 ]); printf ("%s %s %s\n" , argv[0 ], filename, argv[2 ]); pid = fork(); if (pid < 0 ) { printf ("fork error!!\n" ); return -1 ; } if (0 == pid) { printf ("This is child process!\n" ); fd = open(filename, O_RDWR); if (fd < 0 ) { printf ("can't open file %s !\n" , filename); return -1 ; } ret = write(fd, writebuf, strlen (writebuf)); if (ret < 0 ) { printf ("write file %s failed!\n" , filename); } ret = close(fd); if (ret < 0 ) { printf ("can't close file %s !\n" , filename); return -1 ; } } #if 1 else { printf ("This is parent process!\n" ); fd = open(filename, O_RDWR); if (fd < 0 ) { printf ("can't open file %s !\n" , filename); return -1 ; } ret = write(fd, writebuf, strlen (writebuf)); if (ret < 0 ) { printf ("write file %s failed!\n" , filename); } ret = close(fd); if (ret < 0 ) { printf ("can't close file %s !\n" , filename); return -1 ; } } #endif return 0 ; }
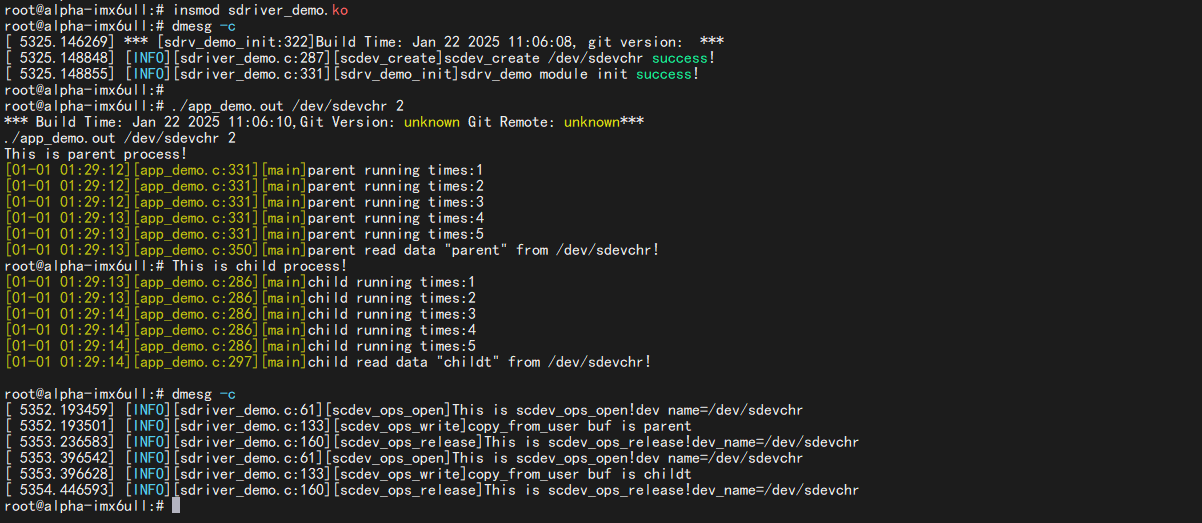
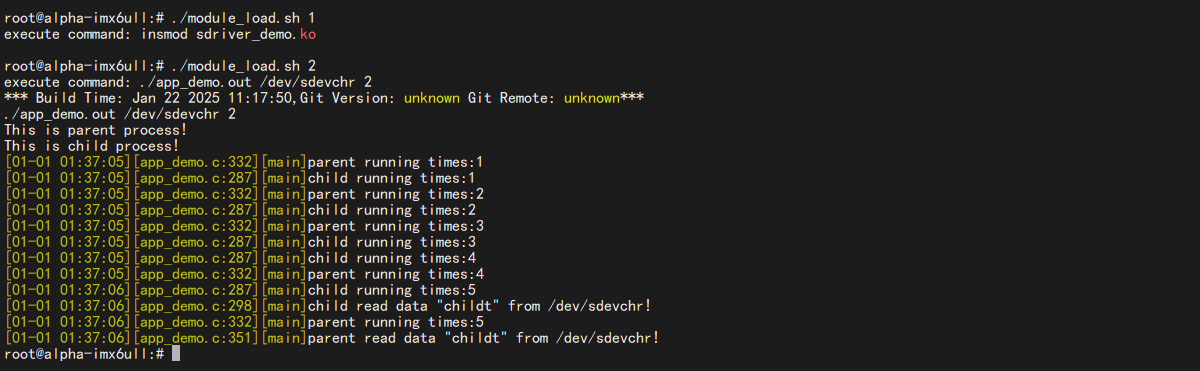
7.1.2 开发板验证 我们将编译得到的sdriver_demo.ko、app_demo.out拷贝到开发板。
(2)这里换了种写法,app_demo.out 会创建子进程运行
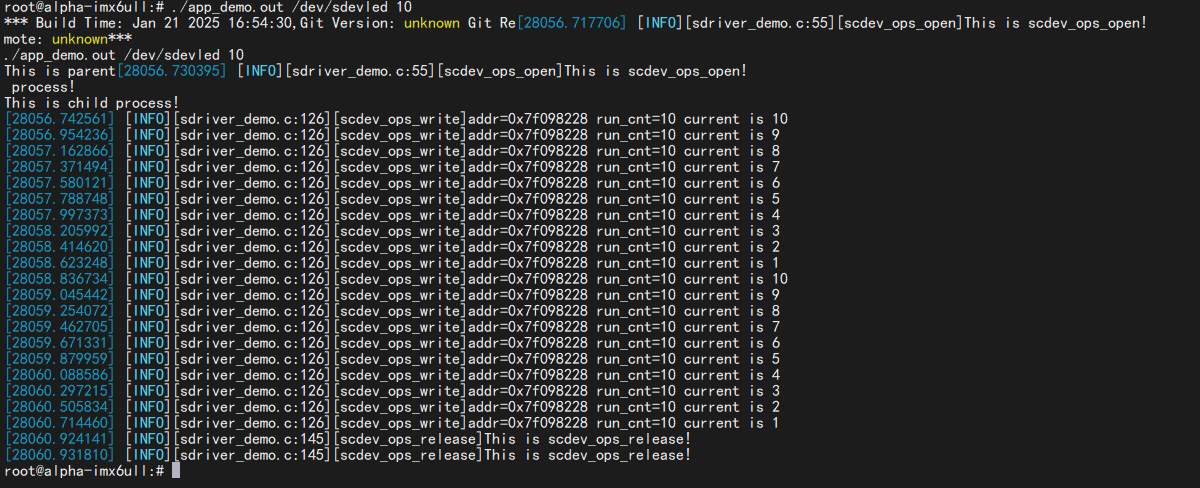
1 ./app_demo.out /dev/sdevchr 10
可以看到不再是像之前竞争演示那样交替打印了,是等一个打完再打另一个。
7.2 正常使用的demo2 这个demo是定义了一个变量,操作它的时候,用自旋锁锁定,保证操作的时候不会被打断而出现问题,相当于前面的原子操作,但是比原子操作能保护的范围更大些。
7.2.1 demo源码 07_concurrency/04_spin_lock_3 · 苏木/imx6ull-driver-demo - 码云 - 开源中国
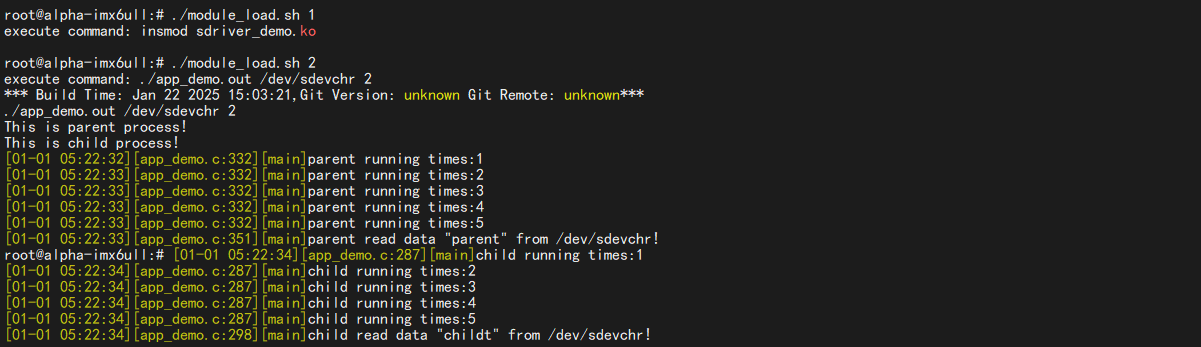
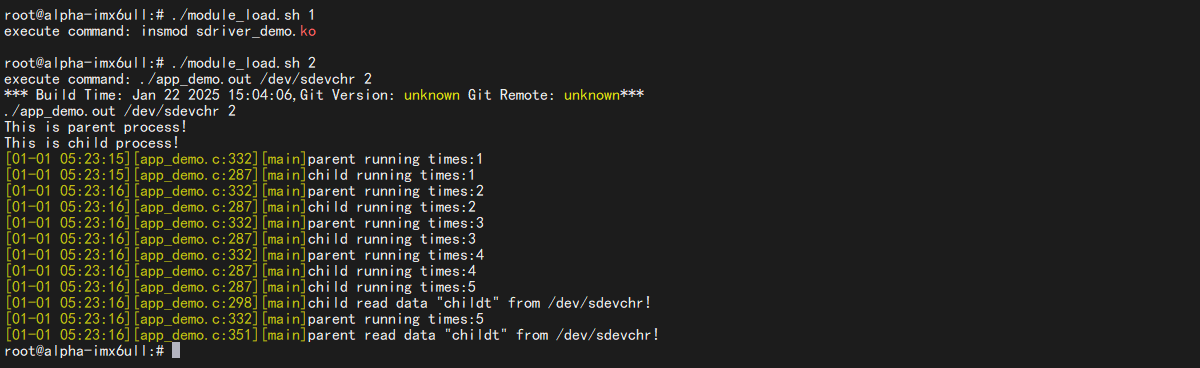
7.2.2 开发板验证 我们将编译得到的sdriver_demo.ko、app_demo.out拷贝到开发板。
(2)这里换了种写法,app_demo.out 会创建子进程运行
1 ./app_demo.out /dev/sdevchr 2 # 这个参数没啥意义,我在内部写死了
usleep(1000*200*6)时,父子进程依次运行:
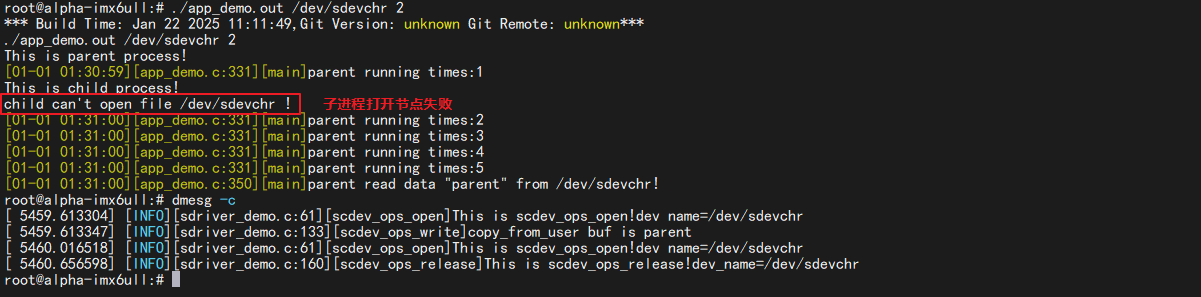
usleep(1000*200*2)时,子进程运行失败:
修改app_demo.c中下图位置的休眠时间可以控制子进程的运行时间,当父进程运行完再运行子进程时,子进程运行正常,当父进程未运行完毕就开始运行子进程,子进程就会打开节点失败,达到共享资源保护的目的。
7.3 死锁的demo 7.3.1 demo源码 这个demo是第一种情况, 即拥有自旋锁的进程 A 在内核态休眠了, 内核调度 B 进程, 碰巧 B 进程也要获得自旋锁, 依次产生死锁。
07_concurrency/04_spin_lock_1 · 苏木/imx6ull-driver-demo - 码云 - 开源中国
07_concurrency/04_spin_lock_2 · 苏木/imx6ull-driver-demo - 码云 - 开源中国
7.3.2 开发板验证 这个demo是在内核进行长时间休眠,会导致崩溃,先不管了,知道死锁的原理就可以了。崩溃的信息可以看这里,这里有一个:07_concurrency/04_spin_lock_1/debug_log.md · 苏木/imx6ull-driver-demo - 码云 - 开源中国
三、信号量 1. 什么是信号量 1.1 一个例子 举个例子,某个停车场有 100 个停车位,这 100 个停车位大家都可以用,对于大家来说这100 个停车位就是共享资源。假设现在这个停车场正常运行,我们要把车停到这个这个停车场肯定要先看一下现在停了多少车了?还有没有停车位?当前停车数量就是一个信号量,具体的停车数量就是这个信号量值,当这个值到 100 的时候说明停车场满了。停车场满的时我们可以等一会看看有没有其他的车开出停车场,当有车开出停车场的时候停车数量就会减一,也就是说信号量减一,此时我们就可以把车停进去了,我们把车停进去以后停车数量就会加一,也就是信号量加一。这就是一个典型的使用信号量进行共享资源管理的案例,在这个案例中使用的就是计数型信号量。
1.2 信号量 信号量是操作系统中最典型的用于同步和互斥的手段, 本质上是一个全局变量 , 信号量的值表示控制访问资源的线程数, 可以根据实际情况来自行设置。
如果在初始化的时候将信号量量值设置为大于 1, 那么这个信号量就是计数型信号量 , 允许多个线程同时访问共享资源,不能用于互斥访问。
如果将信号量量值设置为 1, 那么这个信号量就是二值信号量 , 同一时间内只允许一个线程访问共享资源, 可以用于互斥访问。
注意! 信号量的值不能小于 0。 当信号量的值为 0 时, 想访问共享资源的线程必须等待, 直到信号量大于 0 时, 等待的线程才可以访问。 当访问共享资源时, 信号量执行“减一”操作, 访问完成后再执行“加一” 操作 。
2. 信号量的特点 相比于自旋锁,信号量可以使线程进入休眠状态,比如 A 与 B、 C 合租了一套房子,这个房子只有一个卫生间,一次只能一个人使用。某一天早上 A 去上卫生间了,过了一会 B 也想用卫生间,因为 A 在卫生间里面,所以 B 只能等到 A 用来了才能进去。 B 要么就一直在卫生间门口等着,等 A 出来,这个时候就相当于自旋锁。 B 也可以告诉 A,让 A 出来以后通知他一下,然后 B 继续回房间睡觉,这个时候相当于信号量。
可以看出,使用信号量会提高处理器的使用效率,毕竟不用一直傻乎乎的在那里“自旋”等待。但是,信号量的开销要比自旋锁大,因为信号量使线程进入休眠状态以后会切换线程,切换线程就会有开销。总结一下信号量的特点:
①、因为信号量可以使等待资源线程进入休眠状态,因此适用于那些占用资源比较久的场合。
②、因此信号量不能用于中断中,因为信号量会引起休眠,中断不能休眠。
③、如果共享资源的持有时间比较短,那就不适合使用信号量了,因为频繁的休眠、切换线程引起的开销要远大于信号量带来的那点优势。
3. 相关数据结构与API Linux 内核使用 struct semaphore 结构体表示信号量:
1 2 3 4 5 6 struct semaphore { raw_spinlock_t lock; unsigned int count; struct list_head wait_list ; };
3.2 相关API 信号量相关的API函数声明可以在 semaphore.h - include/linux/semaphore.h 中找到:
函数
描述
DEFINE_SEAMPHORE(name)
定义一个信号量,并且设置信号量的值为 1。
void sema_init(struct semaphore *sem, int val)
初始化信号量 sem,设置信号量值为 val。
void down(struct semaphore *sem)
获取信号量,因为会导致休眠,因此不能在中断中使用。
int down_trylock(struct semaphore *sem);
尝试获取信号量,如果能获取到信号量就获取,并且返回 0。如果不能就返回非 0,并且不会进入休眠。
int down_interruptible(struct semaphore *sem)
获取信号量,和 down 类似,只是使用 down 进入休眠状态的线程不能被信号打断。而使用此函数进入休眠以后是可以被信号打断的。
void up(struct semaphore *sem)
释放信号量
3.3 使用示例 1 2 3 4 5 struct semaphore sem ;sema_init(&sem, 1 ); down(&sem); up(&sem);
4. 信号量demo 4.1 demo源码 07_concurrency/05_semaphore · 苏木/imx6ull-driver-demo - 码云 - 开源中国
4.2 开发板验证 我们将编译得到的sdriver_demo.ko、app_demo.out拷贝到开发板。
1 ./app_demo.out /dev/sdevchr 2
可以看到是一个执行完再执行另一个。没有信号量保护的时候是这样的:
四、互斥锁 1. 什么是互斥锁 比如公司部门里, 我在使用着打印机打印东西的同时(还没有打印完) , 别人刚好也在此刻使用打印机打印东西, 如果不做任何处理的话,打印出来的东西肯定是错乱的。 那么怎么解决这种情况呢? 只要我在打印着的时候别人是不允许打印的, 只有等我打印结束后别人才允许打印。 这个过程有点类似于, 把打印机放在一个房间里, 给这个房间安把锁, 这个锁默认是打开的。 当 A 需要打印时, 他先过来检查这把锁有没有锁着, 没有的话就进去, 同时上锁在房间里打印。 而在这时, 刚好 B 也需要打印, B 同样先检查锁, 发现锁是锁住的, 他就在门外等着。 而当 A 打印结束后, 他会开锁出来, 这时候 B 才进去上锁打印。
现在应该就知道互斥锁是什么了,也可以叫互斥体,后面我还是叫互斥锁吧。互斥锁会导致休眠, 所以在中断里面不能用互斥锁。 同一时刻只能有一个线程持有互斥锁,并且只有持有者才可以解锁, 并且不允许递归上锁和解锁。
我们将信号量量值设置为 1, 最终实现的就是互斥效果,虽然两者功能相同但是具体的实现方式是不同的, 但是使用互斥锁效率更高、更简洁, 所以如果使用到的信号量“量值”为 1, 一般将其修改为使用互斥锁实现。
当有多个线程几乎同时修改某一个共享数据的时候, 需要进行同步控制。 线程同步能够保证多个线程安全访问竞争资源, 最简单的同步机制是引入互斥锁。 互斥锁为资源引入一个状态:锁定或者非锁定。 某个线程要更改共享数据时, 先将其锁定, 此时资源的状态为“锁定” , 其他线程不能更改; 直到该线程释放资源, 将资源的状态变成“非锁定” , 其他的线程才能再次锁定该资源。 互斥锁保证了每次只有一个线程进行写入操作, 从而保证了多线程情况下数据的正确性, 能够保证多个线程访问共享数据不会出现资源竞争及数据错误。
2. 相关数据结构与API Linux 内核使用 struct mutex 来表示互斥锁:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct mutex { atomic_long_t owner; spinlock_t wait_lock; #ifdef CONFIG_MUTEX_SPIN_ON_OWNER struct optimistic_spin_queue osq ; #endif struct list_head wait_list ; #ifdef CONFIG_DEBUG_MUTEXES void *magic; #endif #ifdef CONFIG_DEBUG_LOCK_ALLOC struct lockdep_map dep_map ; #endif };
2.2 互斥锁相关API 相关的API在 mutex.h - include/linux/mutex.h 中有对应的声明或者定义:
函数
描述
DEFINE_MUTEX(name)
定义并初始化一个 mutex 变量。
void mutex_init(mutex *lock)
初始化 mutex。
void mutex_lock(struct mutex *lock)
获取 mutex,也就是给 mutex 上锁。如果获取不到就进休眠。
void mutex_unlock(struct mutex *lock)
释放 mutex,也就给 mutex 解锁。
int mutex_trylock(struct mutex *lock)
尝试获取 mutex,如果成功就返回 1,如果失败就返回 0。
int mutex_is_locked(struct mutex *lock)
判断 mutex 是否被获取,如果是的话就返回1,否则返回 0。
int mutex_lock_interruptible(struct mutex *lock)
使用此函数获取信号量失败进入休眠以后可以被信号打断。
2.3 使用示例 1 2 3 4 5 6 struct mutex lock ;mutex_init(&lock); mutex_lock(&lock); mutex_unlock(&lock);
3. 注意事项 在使用 mutex 的时候要注意如下几点:
①、 mutex 可以导致休眠,因此不能在中断中使用 mutex,中断中只能使用自旋锁。
②、和信号量一样, mutex 保护的临界区可以调用引起阻塞的 API 函数。
③、因为一次只有一个线程可以持有 mutex,因此,必须由 mutex 的持有者释放 mutex。并且 mutex 不能递归上锁和解锁。
4. 互斥锁demo 4.1 demo源码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 #include <linux/init.h> #include <linux/kernel.h> #include <linux/module.h> #include <linux/fs.h> #include <linux/cdev.h> #include <linux/uaccess.h> #include <linux/delay.h> #include <linux/mutex.h> #include "./timestamp_autogenerated.h" #include "./version_autogenerated.h" #include "./sdrv_common.h" #ifndef PRT #define PRT printk #endif #ifndef PRTE #define PRTE printk #endif #define CHRDEV_NAME "sdev" #define CLASS_NAME "sclass" #define DEVICE_NAME "sdevchr" #define BUFSIZE 32 #define MUTEX_FLAG 0 #define CMD_TEST0 _IO('S' , 0) #define CMD_TEST1 _IOW('S' , 1, int) #define CMD_TEST2 _IOR('S' , 2, int) #define CMD_TEST3 _IOW('S' , 3, int) struct __CMD_TEST { int a; int b; int c; }; typedef struct __CHAR_DEVICE { char dev_name[32 ]; dev_t dev_num; struct cdev s_cdev ; struct class *class ; struct device *device ; char buf[BUFSIZE]; struct mutex mutex_lock ; } _CHAR_DEVICE; _CHAR_DEVICE g_chrdev = {0 }; static int scdev_ops_open (struct inode *pInode, struct file *pFile) { PRT("This is scdev_ops_open!dev name=%s\n" , g_chrdev.dev_name); pFile->private_data = &g_chrdev; #if MUTEX_FLAG == 1 if (mutex_lock_interruptible(&g_chrdev.mutex_lock)) { return -ERESTARTSYS; } #if 0 mutex_lock(&g_chrdev.lock); #endif #endif return 0 ; } static ssize_t scdev_ops_read (struct file *pFile, char __user *buf, size_t size, loff_t *off) { loff_t offset = *off; size_t count = size; _CHAR_DEVICE *p_chrdev=(_CHAR_DEVICE *)pFile->private_data; if (offset > BUFSIZE) { return 0 ; } if (count > BUFSIZE - offset) { count = BUFSIZE - offset; } if (copy_to_user(buf, p_chrdev->buf + offset, count)) { PRT("copy_to_user error!\n" ); return -1 ; } #if 0 int i = 0 ; for (i = 0 ; i < BUFSIZE; i++) { PRT("buf[%d] %c\n" , i, p_chrdev->buf[i]); } PRT("read offset is %llu, count is %d\n" , offset, count); #endif *off = *off + count; return count; } static ssize_t scdev_ops_write (struct file *pFile, const char __user *buf, size_t size, loff_t *off) { loff_t offset = *off; size_t count = size; _CHAR_DEVICE *p_chrdev=(_CHAR_DEVICE *)pFile->private_data; if (offset > BUFSIZE) { return 0 ; } if (count > BUFSIZE - offset) { count = BUFSIZE - offset; } if (copy_from_user(p_chrdev->buf + offset, buf, count)) { PRT("copy_to_user error \n" ); return -1 ; } PRT("copy_from_user buf is %s\n" , p_chrdev->buf + offset); #if 0 int i = 0 ; for (i = 0 ; i < BUFSIZE; i++) { PRT("buf[%d] %c\n" , i, p_chrdev->buf[i]); } PRT("write offset is %llu, count is %d\n" , offset, count); #endif *off = *off + count; return count; } static int scdev_ops_release (struct inode *pInode, struct file *pFile) { _CHAR_DEVICE *p_chrdev=(_CHAR_DEVICE *)pFile->private_data; #if MUTEX_FLAG == 1 mutex_unlock(&p_chrdev->mutex_lock); #endif PRT("This is scdev_ops_release!dev_name=%s\n" , p_chrdev->dev_name); return 0 ; } static loff_t scdev_ops_llseek (struct file *pFile, loff_t offset, int whence) { loff_t new_offset = 0 ; switch (whence) { case SEEK_SET: if (offset < 0 || offset > BUFSIZE) { return -EINVAL; } new_offset = offset; break ; case SEEK_CUR: if ((pFile->f_pos + offset < 0 ) || (pFile->f_pos + offset > BUFSIZE)) { return -EINVAL; } new_offset = pFile->f_pos + offset; break ; case SEEK_END: if (pFile->f_pos + offset < 0 ) { return -EINVAL; } new_offset = BUFSIZE + offset; break ; default : break ; } pFile->f_pos = new_offset; return new_offset; } static long scdev_ops_ioctl (struct file *pFile, unsigned int cmd, unsigned long arg) { int val = 0 ; switch (cmd) { case CMD_TEST0: PRT("this is CMD_TEST0\n" ); break ; case CMD_TEST1: PRT("this is CMD_TEST1\n" ); PRT("arg is %ld\n" ,arg); break ; case CMD_TEST2: val = 1 ; PRT("this is CMD_TEST2\n" ); if (copy_to_user((int *)arg, &val, sizeof (val)) != 0 ) { PRT("copy_to_user error \n" ); } break ; case CMD_TEST3: { struct __CMD_TEST cmd_test3 =0 }; if (copy_from_user(&cmd_test3, (int *)arg, sizeof (cmd_test3)) != 0 ) { PRT("copy_from_user error\n" ); } PRT("cmd_test3.a = %d\n" , cmd_test3.a); PRT("cmd_test3.b = %d\n" , cmd_test3.b); PRT("cmd_test3.c = %d\n" , cmd_test3.c); break ; } default : break ; } return 0 ; } static struct file_operations g_scdev_ops = .owner = THIS_MODULE, .open = scdev_ops_open, .read = scdev_ops_read, .write = scdev_ops_write, .release = scdev_ops_release, .llseek = scdev_ops_llseek, .unlocked_ioctl = scdev_ops_ioctl, }; static int scdev_create (_CHAR_DEVICE *p_chrdev) { int ret; int major, minor; #if MUTEX_FLAG == 1 mutex_init(&p_chrdev->mutex_lock); #endif ret = alloc_chrdev_region(&p_chrdev->dev_num, 0 , 1 , CHRDEV_NAME); if (ret < 0 ) { PRTE("alloc_chrdev_region is error!ret=%d\n" , ret); goto err_alloc_devno; } major = MAJOR(p_chrdev->dev_num); minor = MINOR(p_chrdev->dev_num); cdev_init(&p_chrdev->s_cdev, &g_scdev_ops); p_chrdev->s_cdev.owner = THIS_MODULE; ret = cdev_add(&p_chrdev->s_cdev, p_chrdev->dev_num, 1 ); if (ret < 0 ) { PRTE("cdev_add is error !ret=%d\n" , ret); goto err_cdev_add; } p_chrdev->class = if (IS_ERR(p_chrdev->class)) { ret = PTR_ERR(p_chrdev->class); goto err_class_create; } p_chrdev->device = device_create(p_chrdev->class, NULL , p_chrdev->dev_num, NULL , "%s" , DEVICE_NAME); if (IS_ERR(p_chrdev->device)) { ret = PTR_ERR(p_chrdev->class); goto err_device_create; } snprintf (p_chrdev->dev_name, sizeof (p_chrdev->dev_name), "/dev/%s" , DEVICE_NAME); PRT("scdev_create %s success!\n" , p_chrdev->dev_name); return 0 ; err_device_create: class_destroy(p_chrdev->class); err_class_create: cdev_del(&p_chrdev->s_cdev); err_cdev_add: unregister_chrdev_region(p_chrdev->dev_num, 1 ); err_alloc_devno: return ret; } static void scdev_destroy (_CHAR_DEVICE *p_chrdev) { cdev_del(&p_chrdev->s_cdev); unregister_chrdev_region(p_chrdev->dev_num, 1 ); device_destroy(p_chrdev->class, p_chrdev->dev_num); class_destroy(p_chrdev->class); PRT("scdev_destroy success!\n" ); } static __init int sdrv_demo_init (void ) { int ret = 0 ; printk("*** [%s:%d]Build Time: %s %s, git version:%s ***\n" , __FUNCTION__, __LINE__, KERNEL_KO_DATE, KERNEL_KO_TIME, KERNEL_KO_VERSION); ret = scdev_create(&g_chrdev); if (ret < 0 ) { PRTE("Failed to scdev_create!ret=%d\n" , ret); goto err_scdev_create; } PRT("sdrv_demo module init success!\n" ); return 0 ; err_scdev_create: return ret; } static __exit void sdrv_demo_exit (void ) { scdev_destroy(&g_chrdev); PRT("sdrv_demo module exit!\n" ); } module_init(sdrv_demo_init); module_exit(sdrv_demo_exit); MODULE_LICENSE("GPL v2" ); MODULE_AUTHOR("sumu" ); MODULE_DESCRIPTION("Description" ); MODULE_ALIAS("module's other name" );
4.2 开发板验证 其实这个现象和信号量是一样的,我们将编译得到的sdriver_demo.ko、app_demo.out拷贝到开发板。
1 ./app_demo.out /dev/sdevchr 2
可以看到是一个执行完再执行另一个。没有互斥锁保护的时候是这样的:
参考资料:
自旋锁在抢占(或非抢占)单核和多核中的作用_多核系统中,任务可以通过自旋锁或者中断的方式独占cpu-CSDN博客