LV05-05-进程通信-02-管道
本文主要是进程通信——管道的相关笔记,若笔记中有错误或者不合适的地方,欢迎批评指正😃。
点击查看使用工具及版本
| Windows | windows11 |
| Ubuntu | Ubuntu16.04的64位版本 |
| VMware® Workstation 16 Pro | 16.2.3 build-19376536 |
| SecureCRT | Version 8.7.2 (x64 build 2214) - 正式版-2020年5月14日 |
| 开发板 | 正点原子 i.MX6ULL Linux阿尔法开发板 |
| uboot | NXP官方提供的uboot,NXP提供的版本为uboot-imx-rel_imx_4.1.15_2.1.0_ga(使用的uboot版本为U-Boot 2016.03) |
| linux内核 | linux-4.15(NXP官方提供) |
| STM32开发板 | 正点原子战舰V3(STM32F103ZET6) |
点击查看本文参考资料
| 参考方向 | 参考原文 |
| --- | --- |
点击查看相关文件下载
| --- | --- |
一、Linux 管道
1. 无名管道
我们前边在学习Linux命令的时候,有学习过这么一个符号|,这就是管道,例如,
1 | ps -elf | grep a.out |
它的功能是将前一个命令(ps -elf)的输出,作为后一个命令(grep a.out)的输入,不难看出管道传输数据是单向的,如果想相互通信,我们需要创建两个管道才行。上面这种管道是没有名字,所以|表示的管道称为匿名管道,也可以叫无名管道,用完了就销毁。
2. 有名管道
管道还有另外一个类型是命名管道,也被叫做 FIFO,也可以叫有名管道。因为数据是先进先出的传输方式。
2.1 创建有名管道
2.1.1 命令说明
在使用命名管道前,先需要通过 mkfifo 命令来创建,并且指定管道名字,可以在终端输入以下命令:
1 | mkfifo <管道名称> |
2.1.2 使用实例
我们可以执行以下命令:
1 | mkfifo myFifo |
要是在Windows共享文件夹目录(/mnt/hgfs/Sharedfiles)下创建的话可能会收到如下提示:
1 | mkfifo: 无法创建先进先出文件'myFifo': 没有那个文件或目录 |
归根结底是因为用的是共享文件夹,而Windows的文件系统又不支持管道文件。创建的管道文件路径必须设为linux的本地文件夹。所以我们不要在共享目录下创建就可以啦,创建完成后我们使用ls -alh查看一下创建的文件详细信息:
1 | 总用量 8.0K |
会发现,有名管道文件类型为p,也就是 pipe(管道) 的意思。
2.2 数据读写
2.2.1 命令说明
- 向管道写入数据
1 | echo "data" > 已创建的管道名称 # 可以包含路径 |
- 从管道读取数据
1 | cat < 已创建的管道名称 # 可以包含路径 |
【注意事项】我们必须在管道所在的目录下执行上边的读写命令,或者就是指明创建的管道的路径。
2.2.2 使用实例
下边的演示,在管道文件myFifo所在的目录中进行。我们在终端执行以下命令:
1 | echo "fanhua" > myFifo |
输入命令后,按下回车,我们会发现终端停住了,这是因为管道里的内容没有被读取,只有当管道里的数据被读完后,命令才可以正常退出。我们开启另一个终端,输入以下命令:
1 | cat < myFifo |
然后,终端会有以下数据输出:
1 | fanhua |
这个时候,我们会发现,写入数据的终端命令正常退出了,管道中的数据已经读取了,我们再读会出现什么情况?管道中没有数据的时候再执行一次读取命令,那么这个终端就会停住,直到另一个终端向管道写入数据,便会直接读取数据然后退出。
我们可以看出,管道这种通信方式效率低,不适合进程间频繁地交换数据。当然,它的好处就是简单,同时也我们很容易得知管道里的数据已经被另一个进程读取了。
3. 管道大小查看
那么既然管道是一种文件,它的最大大小是多少呢?我们可以使用如下命令查看:
1 | ulimit -a |
然后终端会有如下信息提示:
1 | real-time non-blocking time (microseconds, -R) unlimited |
其中有一个pipe size,可以看到是8x521byte=4k。但是当我们查看man手册的时候,使用如下命令:
1 | man 7 pipe |
然后找到Pipe capacity部分,有如下说明:
1 | A pipe has a limited capacity. If the pipe is full, then a write(2) will block or fail, depending on whether the O_NONBLOCK flag is set (see below). Different implementations have different limits for the pipe capacity. Applications should not rely on a particular capacity: an application should be designed so that a reading process consumes data as soon as it is available, so that a writing process does not remain blocked. |
其实看的不是很明白,后边挺老师讲的时候,说最大是64K。于是便查阅了很多资料吗,了解到管道容量分为pipe capacity 和 pipe_buf 。这两者的区别在于pipe_buf定义的是内核管道缓冲区的大小,这个值的大小是由内核设定的,这个值仅需一条命令就可以查到;而pipe capacity指的是管道的最大值,即容量,是内核内存中的一个缓冲区。
二、管道的概念
上线了解了linux中的管道的相关操作,接下来我们来学习一下管道的概念。
管道是UNIX系统上最古老的IPC方法,它在20世纪70年代早期UNIX的第三个版本上就出现了。把一个进程连接到另一个进程的数据流称为管道,管道被抽象成一个文件,称为管道文件(pipe)。
管道可以分为两种:无名(匿名)管道和有名管道。两者的特点如下:
只能用于具有亲缘关系的进程之间的通信(父子进程,兄弟进程)。
是单工的通信模式,具有固定的读端和写端,只能一端读,一端写(程序实现设计好)。
无名管道创建时会返回两个文件描述符,分别用于读写管道。
管道可以用于多于
2个进程共享。
有名管道可以使非亲缘的两个进程互相通信;
通过路径名来操作,在文件系统中可见,但内容存放在内存中;
文件
IO来操作有名管道;遵循先进先出规则;
不支持
leek操作;单工读写。
【注意事项】不管是匿名管道还是命名管道,进程写入的数据都是缓存在内核中,另一个进程读取数据时候自然也是从内核中获取,同时通信数据都遵循先进先出原则,不支持 lseek 之类的文件定位操作。另外他们都是单工读写的,若要实现双向的数据传输,可以使用两个管道。
三、无名管道
1. 无名管道创建
1.1 pipe()
1.1.1 函数说明
在linux下可以使用man pipe 命令查看该函数的帮助手册。
1 | /* 需包含的头文件 */ |
【函数说明】该函数创建一个无名管道,创建之后会产生两个文件描述符,就相当于直接打开了可以直接使用,使用完毕后会自动销毁。
【函数参数】
pipefd[2]:int类型,是一个大小为2的数组,pipefd[0]和pipefd[1]表示两个文件描述符,分别代表管道的两端,一般代表含义如下:
| pipefd[0] | 管道读端 |
| pipefd[1] | 管道写端 |
【返回值】int类型,成功返回0,失败返回-1,并设置errno。
【使用格式】一般情况下基本使用格式如下:
1 | /* 需要包含的头文件 */ |
【注意事项】创建的匿名管道是特殊的文件,只存在于内存,不存于文件系统中。
1.1.2 使用实例
点击查看实例
1 |
|
在终端执行以下命令编译程序:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
然后,终端会有以下信息显示:
1 | pfd[0]=3,pfd[1]=4 |
2. 无名管道读写
2.1 read()
2.1.1 函数说明
在linux下可以使用man 2 read命令查看该函数的帮助手册。
1 | /* 需包含的头文件 */ |
【函数说明】该函数从文件描述符指向的文件中读指定字节数据。
【函数参数】
fd:int类型,表示文件描述符。buf:void *类型,表示接收数据的缓冲区。count:size_t类型,为需要读取的字节数,不应超过buf的长度。
【返回值】ssize_t类型,成功返回读取的字节数;失败返回-1, 错误代码存入errno 中, 而文件读写位置则无法预期;读到文件末尾时或者count为0时,将返回0。
【使用格式】一般情况下基本使用格式如下:
1 | /* 需要包含的头文件 */ |
【注意事项】
(1)读取过程中,未读完count字节时,若遇到换行,则会一起读取。
(2)对于⼀个数组,总是要自动分配⼀个\0作为结束,所以实际有效的buf长度就成为sizeof(buf) - 1了,最好就是在读取完成后自己加上一个\0,以防止后边打印出现乱码的情况。
(3)文件读写位置会随读取到的字节移动。
2.1.2 使用实例
暂无。
2.2 write()
2.2.1 函数说明
在linux下可以使用man 3 write 命令查看该函数的帮助手册。
1 | /* 需包含的头文件 */ |
【函数说明】该函数会将指定字节数据写入到文件描述符所指向的文件中去。
【函数参数】
fd:int类型,表示文件描述符。buf:void *类型,表示要写入数据的缓冲区。count:size_t类型,为需要读取的字节数。
【返回值】ssize_t类型,成功返回实际写入字节数,失败返回-1, 错误代码存入errno 中。
【使用格式】一般情况下基本使用格式如下:
1 | /* 需要包含的头文件 */ |
【注意事项】数据写入完毕后,文件指针指向文件尾部,此时直接读取文件,则什么也读不到,可以使用后边的函数移动指针,再进行读取。
2.2.2 使用实例
暂无。
2.3 管道读写实例
点击查看实例
1 |
|
在终端执行以下命令编译程序:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
然后,终端会有以下信息显示:
1 | pfd[READPIPE]=3,pfd[WRITEPIPE]=4 |
【注意事项】这里老师讲的时候好像说一个进程不能既写又读,但是自己测试的时候貌似既可以写又可以读。
3. 父子进程通信
上边我们已经创建了一个管道了,所谓的管道,其实就是内核里面的一串缓存。从管道的一段写入的数据,实际上是缓存在内核中的,另一端读取,也就是从内核中读取这段数据。另外,管道传输的数据是无格式的流且大小受限。
3.1 父进程创建管道
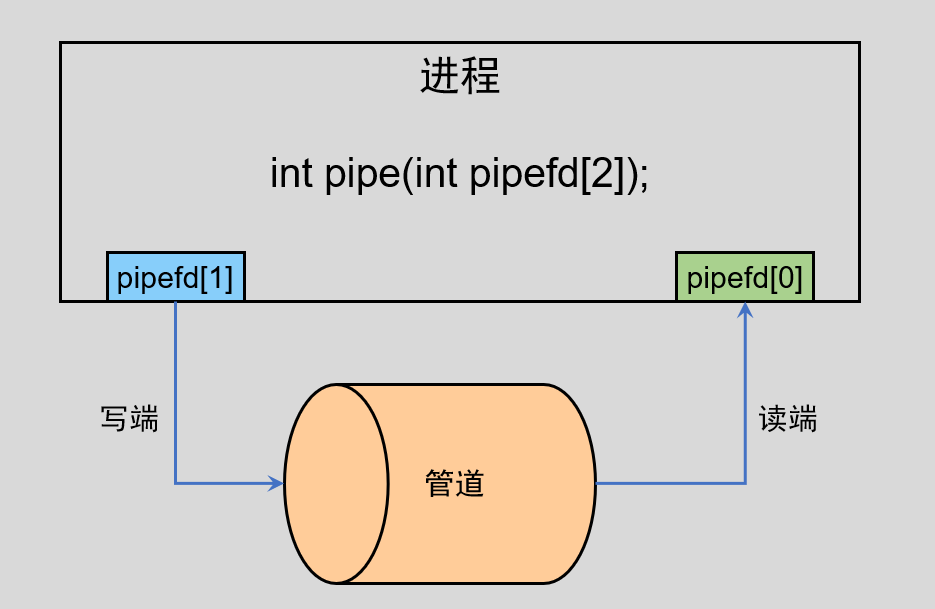
我们在一个进程中创建一个无名管道,会产生两个文件描述符,分别代表读写,如上图所示,并且是单向通信的,只能从写端写入,然后从读端读取,遵循先进先出的原则。
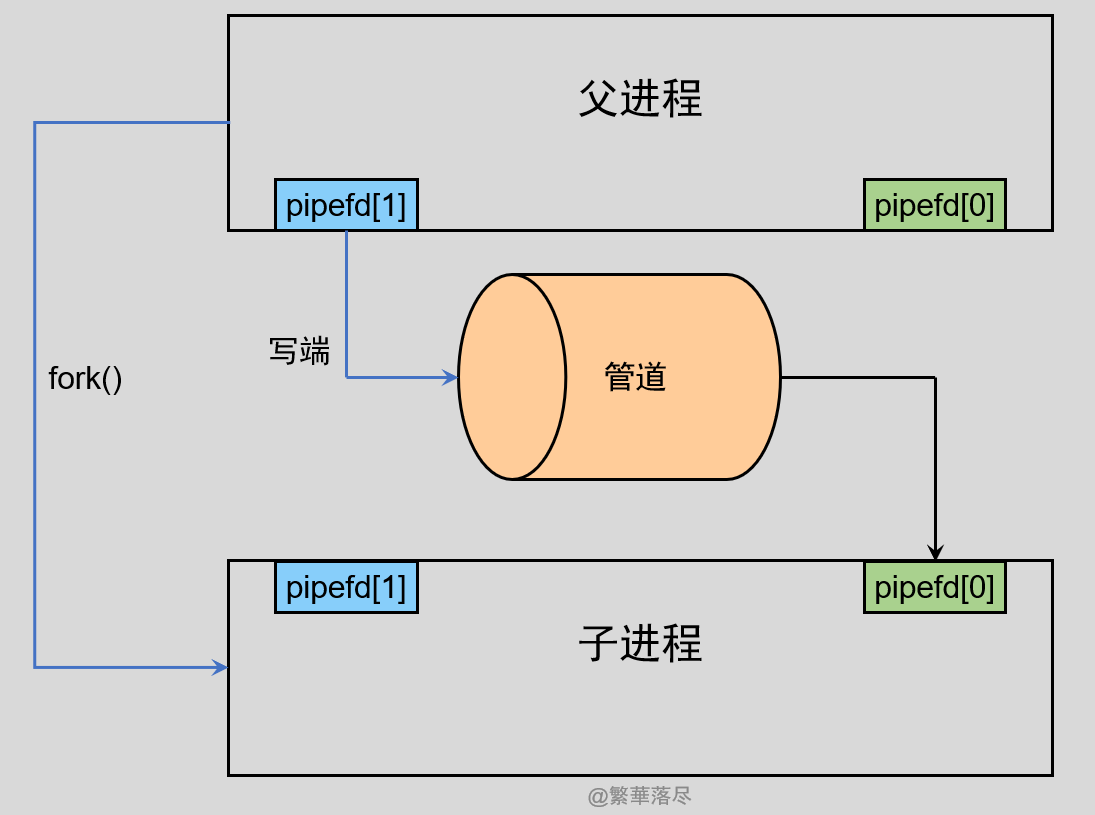
3.2 fork 出子进程
上边在父进程创建管道,那么再创建子进程的时候会变成什么样子呢?

前边学习进程的创建的时候,知道子进程会获得父进程所有文件描述符的副本,所以在创建子进程后,会出出现上图的情况。
3.3 混乱避免
可是上边的子进程和父进程共享文件描述后,在对管道读写的时候会出现混乱的,管道只能一端写入,另一端读出,而父进程和子进程都可以同时写入,也都可以读出。那么,为了避免这种情况,通常的做法是,一个进程用来写入,那么久关闭它的读端,另一个进程用来读取数据,那么就关闭它的写端,于是就会出现下边的情况:
3.4 使用实例
3.4.1 实例1
这个实例是一个父进程一个子进程之间通过无名管道通信。
点击查看实例
1 |
|
在终端执行以下命令编译程序:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
然后,终端会有以下信息显示:
1 | pfd[0]=3,pfd[1]=4 |
3.4.2 实例2
这个实例是一个父进程两个子进程之间通过无名管道通信。
点击查看实例
1 |
|
在终端执行以下命令编译程序:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
然后,终端会有以下信息显示:
1 | pfd[READPIPE]=3,pfd[WRITEPIPE]=4 |
可以发现,两个子进程向管道写入数据,都会被父进程读取出来。
4. 管道的大小
4.1 最多写多少字节?
在前边记录Linux管道一节的时候,提到过管道的大小,记得有一个疑问就是一个4k一个16页,是什么意思,管道到底有多大,我们可以写一个测试程序测试一下:
点击查看实例
1 |
|
在终端执行以下命令编译程序:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
然后,终端会有以下信息显示:
1 | pfd[0]=3,pfd[1]=4 |
可以发现,当我们只写不读的时候且count=65536的时候进程就会阻塞等待,这个时候就是管道已经被写满了,我们知道count=0的时候写入第一个字节数据,count=65535的时候写入最后一个数据,大小一共是65536/1024=64K。
【结论】我使用的环境是Ubuntu21.04的64位版本,测试结果表明,最多可写入64K字节的数据。
4.2 读4k-1个字节?
我后来有了这样一个疑问,当管道写满的时候,我读4k个字节以内数据吗,是不是就可以再写入相同数量个字节数据呢?(为啥是4K为分界,可以看本篇笔记的Linux管道——管道大小查看一小节。
点击查看实例
1 |
|
在终端执行以下命令编译程序:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
然后,终端会有以下信息显示:
1 | pfd[0]=3,pfd[1]=4 |
可以发现,还是之前的样子,写入到第65536个字节数据的时候,程序阻塞,等过10s后,子进程运行,读取4k-1个字节的数据,但是程序之后继续阻塞,并未有数据写入。
【结论】管道写满的时候,读取4k以内个字节并不能结束父进程阻塞,依然无法继续写入。
4.3 读4K个字节?
我后来有了这样一个疑问,当管道写满的时候,我读4k个字节数据呢?(为啥是4K为分界,可以看本篇笔记的 Linux管道——管道大小查看一小节)
点击查看实例
1 |
|
在终端执行以下命令编译程序:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
然后,终端会有以下信息显示:
1 | pfd[0]=3,pfd[1]=4 |
可以发现,还是之前的样子,写入到第65536个字节数据的时候,程序阻塞,等过10s后,子进程运行,读取4k个字节的数据,程序之后继续写入到第69632个数据时继续阻塞,这中间写入了69631-65535=4096也就是4k个字节数据。
【结论】读取数据大于等于4k时,管道才能继续写入相应字节数据。
5. 无名管道特性
5.1 读写端固定
5.1.1 说明
无名管道的读写段端是固定的:
| pipefd[0] | 管道读端 |
| pipefd[1] | 管道写端 |
实际上两个文件描述符,可以有以下四种组合情况(下边的四种情况都是考虑管道中无数据):
| 管道写端 | 管道读端 | 出现的情况 |
| pipefd[0](读) | pipefd[0](读) | 读端写,读端读,会阻塞(若管道之前有数据,那么是可以正常被读出来的,但是读完之后会阻塞) |
| pipefd[0](读) | pipefd[1](写) | 读端写,写端读,会阻塞 |
| pipefd[1](写) | pipefd[0](读) | 写端写,读端读,可以正常读写 |
| pipefd[1](写) | pipefd[1](写) | 写端写,写端读,会一直写入数据,但是无法读取 |
【注意事项】
(1)管道中有数据才能读,否则读取就会阻塞,所以我们下边需要保证先写入,后读取,下边是一个示例程序,直接修改测试即可。
(2)由于读写端的固定,这也导致了数据只能单向传输。
5.1.2 测试实例
点击查看实例
1 |
|
在终端执行以下命令编译程序:
1 | gcc test.c -Wall # 生成可执行文件 a.out |
然后,查看终端信息显示即可。
5.2 读管道特性
5.2.1 说明
这一部分主要是通过实例来得出结论,实例会放在后边,这里先给出结论。对于读管道的特性有两种情况:
- 管道中有数据
read将返回实际读到的字节数。
- 管道中无数据
(1)管道写端被全部关闭时,read返回0 (好像读到文件结尾一样)。
(2)写端没有全部被关闭时,read阻塞等待(不久的将来可能有数据递达,此时会让出cpu)
5.2.2 使用实例
上边两种情况的验证,可以看下边的实例。
点击查看实例源码
1 |
|
上面有两个宏定义,分别代表的含义如下:
| F_WRITE_PFD | 0,不关闭父进程写端,1,关闭父进程写端 |
| F_WRITE_DATA | 0,父进程不写入数据,1,父进程5s写入一次数据 |
在父子进程中,子进程用于读取数据,所以子进程原本就关闭了自己的管道写入端,还剩下管道读取端;父进程用于写入数据,所以父进程原本就关闭了自己的读取端,还剩下管道写入端。
宏F_WRITE_PFD就决定父进程是否关闭自己的写入端,选择关闭时,整个管道的写入端关闭,无法再写入数据。
宏F_WRITE_DATA决定了父进程中是否写入数据,但是当写端全部关闭时,即便在父进程中开启了数据写入,也不会有数据写到管道中。
【结论的验证与宏的对应情况】
- 管道中有数据
read将返回实际读到的字节数。此条结论对应宏的情况如下:
1 |
- 管道中无数据
(1)管道写端被全部关闭时,read返回0 (好像读到文件结尾一样)。此条结论对应宏的情况如下:
1 |
这种情况下,F_WRITE_DATA的值并没有什么意义,因为写端已经关闭了,不管是否有写入数据的部分,管道中都不会有数据写入。
(2)写端没有全部被关闭时,read阻塞等待(不久的将来可能有数据递达,此时会让出cpu)。此条结论对应宏的情况如下:
1 |
F_WRITE_DATA为0时,将会一直等待读取,而为1时,只要有数据写入就会被读取。
5.3 写管道特性
5.3.1 说明
对于写管道的特性有两种情况:
- 管道读端全部被关闭
进程异常终止(也可使用捕捉SIGPIPE信号,使进程不终止)。
- 管道读端没有全部关闭
(1)管道已满,write阻塞。(管道大小64K,不过也不一定,也可以使用相关命令查看,本篇笔记前边的管道数据大小查看有提过)
(2)管道未满,write将数据写入,并返回实际写入的字节数。
5.3.2 使用实例
上边两种情况的验证,可以看下边的实例。
点击查看实例
1 |
|
上面有两个宏定义,分别代表的含义如下:
| C_READ_PFD | 0,不关闭子进程读端,1,关闭子进程读端 |
| PIPE_FULL | 0,不将管道写满,1,将管道写满 |
在父子进程中,子进程用于读取数据,所以子进程原本就关闭了自己的管道写入端,还剩下管道读取端;父进程用于写入数据,所以父进程原本就关闭了自己的读取端,还剩下管道写入端。
宏C_READ_PFD就决定子进程是否关闭自己的读取端,选择关闭时,整个管道的读取端关闭,无法再读取数据。
宏PIPE_FULL决定了父进程中是否写入数据直到管道写满。
【结论的验证与宏的对应情况】
- 管道读端全部被关闭
进程异常终止(也可使用捕捉SIGPIPE信号,使进程不终止)。此条结论对应宏的情况如下:
1 |
这种情况下,程序在写入一次后就终止了。
- 管道读端没有全部关闭
(1)管道已满,write阻塞。(管道大小64K,不过也不一定,也可以使用相关命令查看,本篇笔记前边的管道数据大小查看有提过)
此条结论对应宏的情况如下:
1 |
这种情况下其实与上边测试管道大小的的时候是一样的,管道只写不读,当管道写满后程序开始阻塞。若想继续写入,则需要读取管道中至少4k字节的数据才能写入。
(2)管道未满,write将数据写入,并返回实际写入的字节数。此条结论对应宏的情况如下:
1 |
这种情况下,就是正常的写入读取操作。
四、有名管道
有名管道主要用于非亲缘的两个进程互相通信。
1. 有名管道创建
1.1 mkfifo()
1.1.1 函数说明
在linux下可以使用man 3 mkfifo 命令查看该函数的帮助手册。
1 | /* 需包含的头文件 */ |
【函数说明】该函数用于创建一个有名管道,创建的有名管道文件也可以称为FIFO文件。
【函数参数】
pathname:const char *类型,有名管道文件存放的路径(包括管道名称),需要注意的是,这里不要放在共享目录下。mode:mode_t类型,有名管道文件权限,为8进制表示法。新建的有名管道文件权限会受到umask值影响,实际权限是mode - umaks。
点击查看什么是 umask
在类unix系统中,umask是确定掩码设置的命令,该掩码用来设定文件或目录的初始权限。umask确定了文件创建时的初始权限:
1 | 文件或目录的初始权限 = 文件或目录的最大默认权限 - umask权限 |
文件初始默认权限为0666,目录为0777,若用户umask为0002,则新创建的文件或目录在没有指定的情况下默认权限分别为0664、0775)。
在Linux下,我们可以使用umask命令来查看当前用户默认的umask值,同时也可以在umask命令后面跟上需要设置的umask值来重新设置umask。
【返回值】int类型,成功返回0,失败返回-1,并设置errno。
【使用格式】一般情况下基本使用格式如下:
1 | /* 需要包含的头文件 */ |
【注意事项】
(1)文件路径不要定在虚拟机中Linux与Windows的共享目录中。
(2)该文件必须不存在。
1.1.2 使用实例
暂无。
2. 有名管道打开
2.1 open()
2.1.1 函数说明
在linux下可以使用man 2 open 命令查看该函数的帮助手册。
1 | /* 需包含的头文件 */ |
【函数说明】该函数。
【函数参数】
pathname:const char *类型,表示需要被打开的文件名(可包括路径名)。flags:int类型,表示打开文件所采用的操作。
点击查看详细的 flag 常量
flag常量常见可取的值
| O_RDONLY | 只读方式打开文件。 | 这三个参数互斥 |
| O_WRONLY | 可写方式打开文件。 | |
| O_RDWR | 读写方式打开文件。 | |
| O_CREAT | 如果该文件不存在,就创建一个新的文件,并用第三的参数为其设置权限。 | |
| O_EXCL | 如果使用O_CREAT时文件存在,则可返回错误消息。这一参数可测试文件是否存在。 | |
| O_NOCTTY | 使用本参数时,如文件为终端,那么终端不可以作为调用open()系统调用的那个进程的控制终端。 | |
| O_TRUNC | 如文件已经存在,那么打开文件时先删除文件中原有数据。 | |
| O_APPEND | 以添加方式打开文件,所以对文件的写操作都在文件的末尾进行。 | |
| O_NONBLOCK | 以非阻塞的方式打开文件。 | |
【注意事项】前三个参数必须指定,且只能指定一个,后边的几个可以与前边搭配使用。
flag常量与标准I/O文件打开权限关系、
| r | O_RDONLY | |
| r+ | O_RDWR | |
| w | O_WRONLY | O_CREAT | O_TRUNC, 0664 | |
| w+ | O_RDWR | O_CREAT | O_TRUNC, 0664 | |
| a | O_WRONLY | O_CREAT | O_APPEND, 0664 | |
| a+ | O_RDWR | O_CREAT | O_APPEND, 0664 | |
mode:mode_t类型,表示被打开文件的存取权限,为8进制表示法。此参数只有在建立新文件时有效。新建文件时的权限会受到umask值影响,实际权限是mode - umaks。
【返回值】int类型,成功时返回文件描述符(非负整数);出错时返回EOF(一般是-1)。
【使用格式】一般情况下基本使用格式如下:
1 | /* 需要包含的头文件 */ |
【注意事项】该函数可以打开设备文件,但是不能创建设备文件。
2.2 使用说明
此函数是文件IO中的相关函数,在对有名管道文件进行操作时,需要注意以下几点:
(1)程序不能以O_RDWR(读写)模式打开FIFO文件进行读写操作,而其行为也未明确定义,因为如一个管道以读/写方式打开,进程可以读回自己的输出,同时我们通常使用FIFO只是为了单向的数据传递。
(2)open函数的打开方式还可以有以下情况的搭配:
1 | open(const char *path, O_RDONLY); //1 |
第二个参数中的选项O_NONBLOCK,选项O_NONBLOCK表示非阻塞,加上这个选项后,表示open调用是非阻塞的,如果没有这个选项,则表示open调用是阻塞的。
(3)对于以只读方式(O_RDONLY)打开的FIFO文件,如果open调用是阻塞的(即第二个参数为O_RDONLY),除非有一个进程以写方式打开同一个FIFO,否则它不会返回;如果open调用是非阻塞的的(即第二个参数为O_RDONLY | O_NONBLOCK),则即使没有其他进程以写方式打开同一个FIFO文件,open调用将成功并立即返回。
(4)对于以只写方式(O_WRONLY)打开的FIFO文件,如果open调用是阻塞的(即第二个参数为O_WRONLY),open调用将被阻塞,直到有一个进程以只读方式打开同一个FIFO文件为止;如果open调用是非阻塞的(即第二个参数为O_WRONLY | O_NONBLOCK),open总会立即返回,但如果没有其他进程以只读方式打开同一个FIFO文件,open调用将返回-1,并且FIFO也不会被打开。
(5)据完整性,如果有多个进程写同一个管道,使用O_WRONLY方式打开管道,如果写入的数据长度小于等于PIPE_BUF(4K),或者写入全部字节,或者一个字节都不写入,这样系统就可以确保数据决不会交错在一起。
3. 有名管道读写
3.1 读写函数
先说一下读写吧,有名管道的读写与无名管道一样,当打开之后,可以通过read函数读取管道中的数据,可以使用write函数来写入数据。
1 | /* 需包含的头文件 */ |
3.2 使用实例
下边的实例实现了两个进程的通信。
点击查看实例
【说明】对于以只读方式(O_RDONLY)打开的FIFO文件:如果open调用是阻塞的(即第二个参数为O_RDONLY),除非有一个进程以写方式打开同一个FIFO,否则它不会返回;如果open调用是非阻塞的的(即第二个参数为O_RDONLY | O_NONBLOCK),则即使没有其他进程以写方式打开同一个FIFO文件,open调用将成功并立即返回。
1 | /* 头文件 */ |
【说明】对于以只写方式(O_WRONLY)打开的FIFO文件,如果open调用是阻塞的(即第二个参数为O_WRONLY),open调用将被阻塞,直到有一个进程以只读方式打开同一个FIFO文件为止;如果open调用是非阻塞的(即第二个参数为O_WRONLY | O_NONBLOCK),open总会立即返回,但如果没有其他进程以只读方式打开同一个FIFO文件,open调用将返回-1,并且FIFO也不会被打开。
1 | /* 头文件 */ |
1 | CC = gcc |
在终端执行以下命令编译程序:
1 | make # 编译程序,将会生成两个可执行程序 |
然后,两个终端都会阻塞等待另一个进程打开有名管到文件,之后我们在运行写入管道可执行程序的终端中输入数据,便可以在另一个终端中收到了。
【注意事项】需要注意的是,尽量不要设置不阻塞,否则现象并不明显,很可能会出现以下问题:
1 | open: No such device or address |