LV01-图像-03-图片格式-03-02-JPEG编解码
本文主要是图片格式——JPEG编解码的相关笔记,若笔记中有错误或者不合适的地方,欢迎批评指正😃。
点击查看使用工具及版本
| PC端开发环境 | Windows | Windows11 |
| Ubuntu | Ubuntu20.04.6的64位版本 | |
| VMware® Workstation 17 Pro | 17.0.0 build-20800274 | |
| 终端软件 | MobaXterm(Professional Edition v23.0 Build 5042 (license)) | |
| Win32DiskImager | Win32DiskImager v1.0 | |
| Linux开发板环境 | Linux开发板 | 正点原子 i.MX6ULL Linux 阿尔法开发板 |
| uboot | NXP官方提供的uboot,NXP提供的版本为uboot-imx-rel_imx_4.1.15_2.1.0_ga(使用的uboot版本为U-Boot 2016.03) | |
| linux内核 | linux-4.15(NXP官方提供) |
点击查看本文参考资料
- 通用
| 参考资料 | 相关链接 |
| JPEG官网? | jpeg.org |
| JPEG文件格式参考文档 | JPEG File Interchange Format (JFIF) ---在线文档 |
| JPEG File Interchange Format (JFIF) ---本地文档 |
点击查看相关文件下载
| --- | --- |
一、编解码简介
1. 编解码基本流程
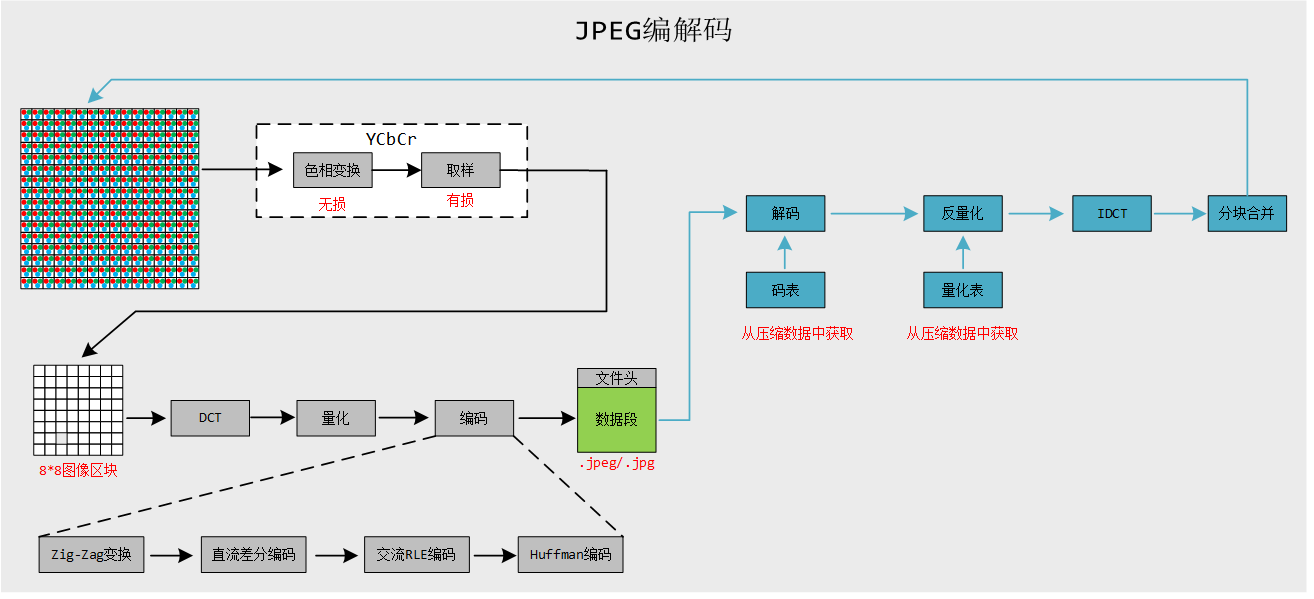
2. 色彩模型转换
这一节笔记主要是jpeg的编码,但是还是要在这里再简单了解一下色彩模型的转换。为什么要做色彩模型转换?前面学习YUV的时候有了解过,这是因为人眼的视杆细胞(对亮度敏感)的数量远多于视锥细胞(对颜色敏感),因此适当压缩颜色信息可以有效减少数据量。
现在采用的色彩空间变换有三种:YIQ,YUV 和 YCrCb。每一种色彩空间都产生一种亮度分量信号和两种色度分量信号,而每一种变换使用的参数都是为了适应某种类型的显示设备。
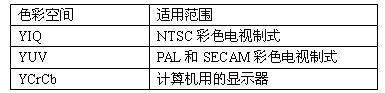
YUV 不是哪个英文单词的缩写,而只是符号,Y 表示亮度,UV 用来表示色差,U、V 是构成彩色的两个分量;YUV 表示法的重要性是它的亮度信号(Y)和色度信号(U、V)是相互独立的,也就是 Y 信号分量构成的黑白灰度图与用 U、V 信号构成的另外两幅单色图是相互独立的。由于 Y、U、V 是独立的,所以可以对这些单色图分别进行编码。此外,黑白电视能接收彩色电视信号也就是利用了 YUV 分量之间的独立性。

例如,要存储 RGB 8∶8∶8的彩色图像,即 R、G 和 B 分量都用8位二进制数(1个字节)表示,图像的大小为640×480像素,那么所需要的存储容量为640×480×(1+1+1)=921 600字节,即900KB,其中(1+1+1)表示 RGB 各占一个字节。
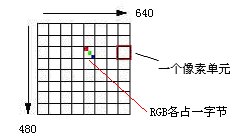
如果用 YUV411 来表示同一幅彩色图像,Y 分量仍然为640×480,并且 Y 分量仍然用8位表示,而对每四个相邻像素(2×2)的 U、V 值分别用相同的一个值表示,那么存储同样的一幅图像所需的存储空间就减少到640×480×(1+1/(2*2)+1/(2*2))=460 800字节,即450KB。也就是把数据压缩了一半。

无论是用 YIQ、YUV 和 YCrCb 还是其他模型来表示的彩色图像,由于现在所有的显示器都采用 RGB 值来驱动,这就要求在显示每个像素之前,须要把彩色分量值转换成 RGB 值。在RGB和YUV怎么转换?
标准有BT601,BT656,BT709等,这些标准不仅包含颜色空间,还包含帧率,分辨率等内容,这里仅仅学习颜色空间的部分。那么JPEG用的是哪一个?参考《ITU-T T.871》第7节“Conversion to and from RGB”这里说的很清楚用的是BT601,但是和BT601有一点区别,BT601的YUV取值范围是16到235,JPEG中的取值范围是0到255。书中给出的公式如下

如果在代码中使用这个公式转换色彩模型最终编码出来的JPEG图片颜色会出问题:
1 | luma = 0.299f * r + 0.587f * g + 0.114f * b; |
使用这个公式才能得到正确的结果:
1 | luma = 0.299f * r + 0.587f * g + 0.114f * b - 128; |
查看 《ITU-T T.81》 的 A.3.1 节“Level shift”(这里我没找到,后面找到了再补充吧),这里提到数据需要 -2^(P-1) 的偏移,也就是说8位数据要减去128。这个看网上也可以写成矩阵的形式:

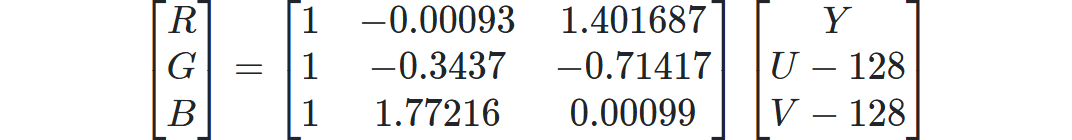
其中:
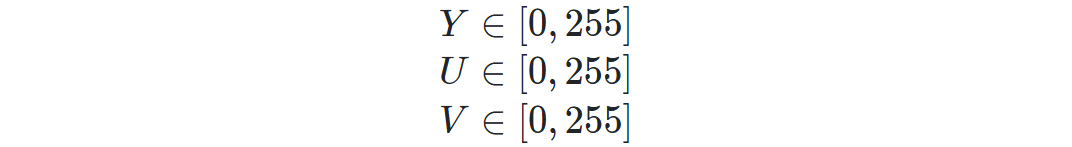
总体来说,上面了解的这些内容,主要就是对原始图片,可以先进行色彩空间的处理,使采集到的图像数据有所减少。实际上,JPEG 算法与色彩空间无关,色彩空间是涉及到图像采样的问题,它和数据的压缩并没有直接的关系。因此其实,“RGB 到 YUV 变换”和“YUV 到 RGB 变换”不包含在 JPEG 算法中。JPEG 算法处理的彩色图像是单独的彩色分量图像,因此它可以压缩来自不同色彩空间的数据,如 RGB,YcbCr 和 CMYK。
3. 色彩深度 color depth
在图像中,它是由很多个点来组成的,那么存储每个像素点所用的位数就叫做像素深度。对一个图片,这个值是可以有所不同的,从而会使得图片的数据有多和少的区别。
一幅彩色图像的每个像素用 R,G,B 三个分量表示,若每个分量用8位,那么一个像素共用3X8=24位表示,就说像素的深度为24 bit,每个像素可以是2的24次方=16 777 216种颜色中的一种。表示一个像素的位数越多,它能表达的颜色数目就越多。
在用二进制数表示彩色图像的像素时,除 R,G,B 分量用固定位数表示外,往往还增加1位或几位作为属性(Attribute)位。例如,RGB 5∶5∶5表示一个像素时,用2个字节共16位表示,其中 R,G,B 各占5位,剩下一位作为属性位。在这种情况下,像素深度为16位,而图像深度为15 位。
在用32位表示一个像素时,若 R,G,B 分别用8位表示,剩下的8位常称为 alpha 通道(alpha channel)位,或称为覆盖(overlay)位、中断位、属性位。它的用法可用一个预乘 α 通道(premultiplied alpha)的例子说明。假如一个像素(A,R,G,B)的四个分量都用归一化的数值表示,(A,R,G,B)为(1,1,0,0)时显示红色。当像素为 (0.5,1,0,0)时,预乘的结果就变成(0.5,0.5,0,0),这表示原来该像素显示的红色的强度为1,而现在显示的红色的强度降了一半。
这个 alpha 值,在这里就用来表示该像素如何产生特技效果。
总体来说,图像的宽高、分辨率越高,就是组成一幅图的像素越多,则图像文件越大;像素深度越深,就是表达单个像素的颜色和亮度的位数越多,图像文件就越大。
只有黑白两种颜色的图像称为单色图像(monochrome),每个像素的像素值用1位存储,它的值只有“0”或者“1”,一幅640×480的单色图像需要占据37.5 KB的存储空间。
而灰度图像,即有色深的黑白图像,如果每个像素的像素值用一个字节表示,而不是仅仅只有一位,那么灰度值级数就等于256级,每个像素可以是0 - 255之间的任何一个值,一幅640×480的灰度图像就需要占用300 KB的存储空间,类似上面说到过的 Y 分量。
二、JPEG编码原理
这里只详细学习编码过程,解码其实就是逆过程。
1. 图像分块
将原始图像分为8*8的小块, 每个block里有64pixels,每个块构成一个数据单元(DU)如下图:
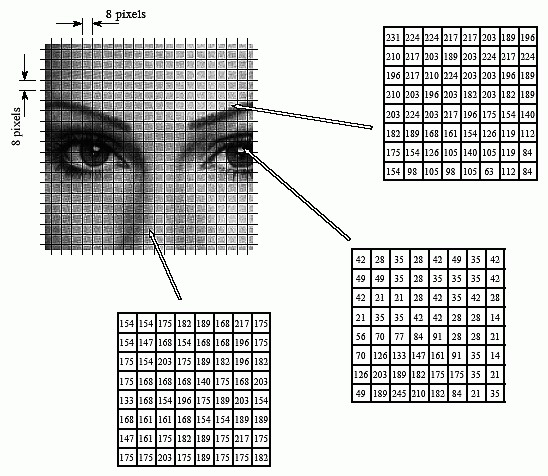
就是划分后,整个图像就是这样的:
我们知道为了降低静态图像数据量,我们可以采用YUV色彩格式,JPEG支持下面几种:
灰度图,单分量
YUV444,采样因子水平2:2:2 垂直2:2:2
YUV422,采样因子水平2:2:2 垂直2:1:1
YUV420,采样因子水平2:1:1 垂直2:1:1
那么对于YUV数据来说,并不一定是1个Y对应一个U和V,那这怎么分块?
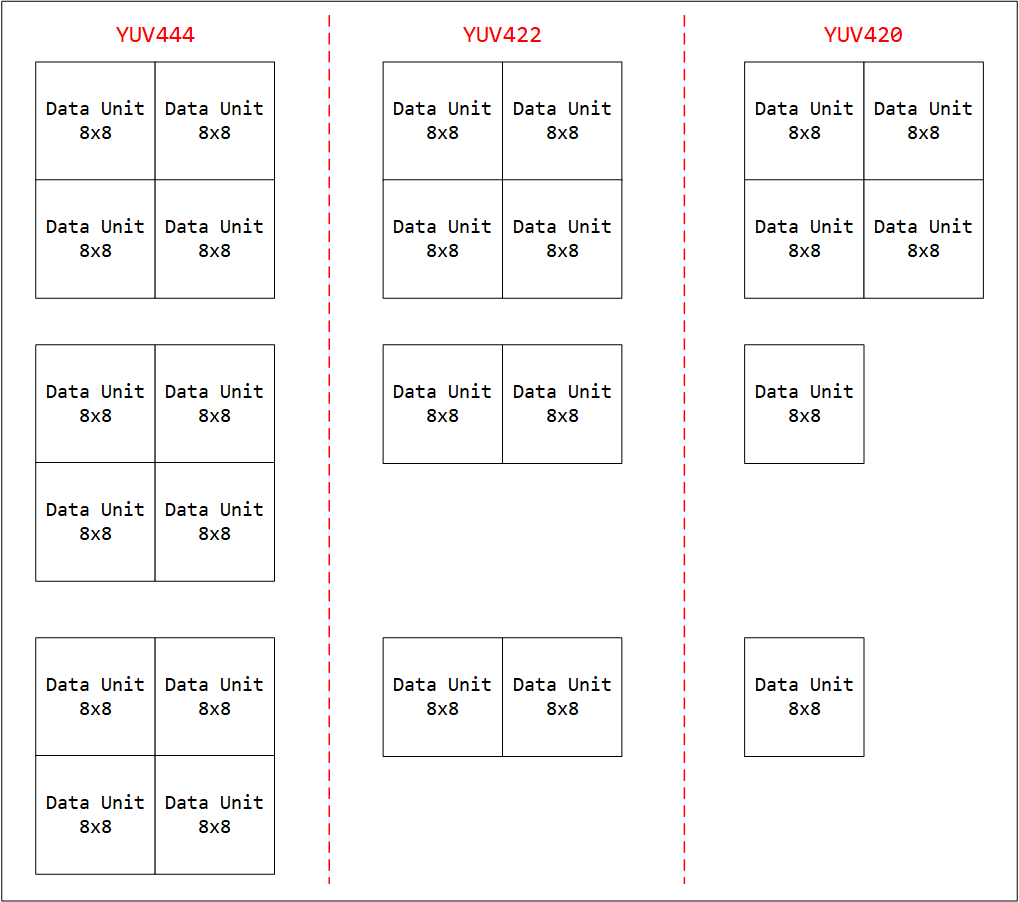
不管是YUV444、YVV422还是YUV420,他们进行分块的时候YUV三个分量都是按照8x8进行分块,以YUV420为例,8x8个Y数据,8x8个U数据和8x8个V数据分别构成DU(Y)、DU(U)和DU(V)。
但是这三种采样方式对应的最小编码单元MCU不同,因为这三种格式一个完整的像素点对应的YUV分量数是不同的。需要按照水平和垂直采样因子决定MCU格式,例如YUV420为H-2:1:1,V-2:1:1,表示Y分量2x2个DU、U分量1x1 、V分量1x1构成一个MCU。即4个DU(Y)、1个DU(U)和1个DU(V)可构成一个最小编码单元(MCU)。
1 | Y:SHY=2 SVY=2 |
据存放方式为
1 | DU(Y) DU(Y) ... DU(Y) DU(U) ... DU(U) DU(V) ... DU(V) |
Tips:每16x16个像素块构成一个MCU
2. DCT-离散余弦变换
2.1 基本原理
将图像从色彩域转换到频率域,常用的变换方法有:

这里我们用的是DCT离散余弦变换。和FFT一样,DCT也是将信号从时域到频域的变换,不同的是DCT中变换结果没有复数,全是实数。每8*8个original pixels都变成了另外8*8个数字,变换后的每一个数都是由original 64 data通过basis function组合而得的,如下图所示为DCT谱中6个元素的由来。
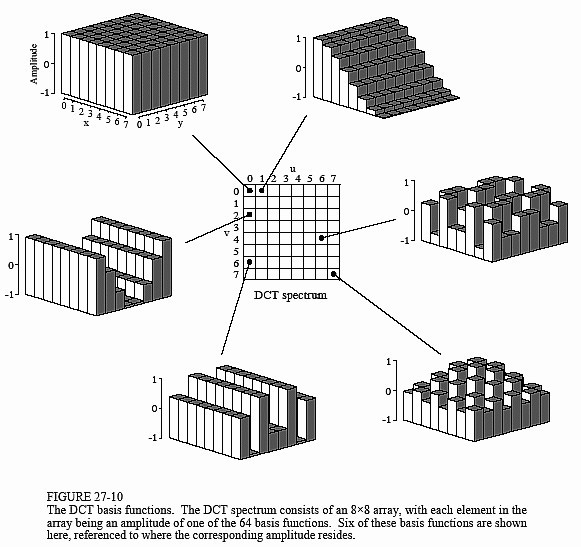
将低频部分集中在每个8*8块的左上角,高频部分在右下角,所谓JPEG的有损压缩,损的是量化过程中的高频部分。为什么呢?因为有这样一个前提:低频部分比高频部分要重要得多,romove 50%的高频信息可能对于编码信息只损失了5%。
二维DCT变换公式如下:
$$
\begin{aligned}
F(u,v)=c(u)c(v)\sum_{i = 0}^{N-1}\sum_{j = 0}^{N-1}f(i,j)cos[\frac{(2i+1)\pi}{2N}u]cos[\frac{(2j+1)\pi}{2N}v]
\end{aligned}
$$
$$
\begin{aligned}
f(i,j)= \sum_{u = 0}^{N-1}\sum_{v = 0}^{N-1}c(u)c(v)F(u,v)cos[\frac{(2i+1)\pi}{2N}u]cos[\frac{(2j+1)\pi}{2N}v]
\end{aligned}
$$
$$
c(u) =
\begin{cases}
\sqrt{\frac{1}{N}}, & \text{u = 0} \\
\sqrt{\frac{2}{N}}, & \text{u $\neq$ 0}
\end{cases}
$$
$$
c(v) =
\begin{cases}
\sqrt{\frac{1}{N}}, & \text{v = 0} \\
\sqrt{\frac{2}{N}}, & \text{v $\neq$ 0}
\end{cases}
$$
2.2 实例1
来看个实例:


对于二维灰度图像进行DCT变换,就能得到图像的频谱图:
低阶(变化幅度小)的部分反映在DCT的左上方
高阶(变化幅度大)的部分反映在DCT的右下方。
由于人眼对高阶部分不敏感,依靠低阶部分就能基本识别出图像内容,所以JPEG进行压缩的时候,基本上只存储DCT变换后的左上部分,而右下部分则直接丢弃.
2.3 实例2
假设8*8的原始图像如下:
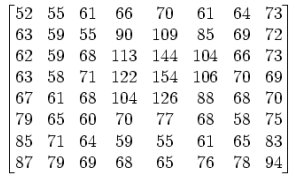
推移128后,使其范围变为 -128~127:

使用离散余弦变换,并四舍五入取最接近的整数:

上图就是将取样块由时间域转换为频率域的 DCT 系数块。DCT 将原始图像信息块转换成代表不同频率分量的系数集,这有两个优点:其一,信号常将其能量的大部分集中于频率域的一个小范围内,这样一来,描述不重要的分量只需要很少的比特数;其二,频率域分解映射了人类视觉系统的处理过程,并允许后继的量化过程满足其灵敏度的要求。
当u,v = 0 时,离散余弦正变换(DCT)后的系数若为F(0,0)=1,则离散余弦反变换(IDCT)后的重现函数 f(x,y)=1/8,是个常 数值,所以将 F(0,0) 称为直流(DC)系数;当 u,v≠0 时,正变换后的系数为 F(u,v)=0,则反变换后的重现函数 f(x,y) 不是常数,此时 正变换后的系数 F(u,v) 为交流(AC)系数。
DCT 后的64个 DCT 频率系数与 DCT 前的64个像素块相对应,DCT 过程的前后都是64个点,说明这个过程只是一个没有压缩作用的无损变换过程。
单独一个图像的全部 DCT 系数块的频谱几乎都集中在最左上角的系数块中。
DCT 输出的频率系数矩阵最左上角的直流 (DC)系数幅度最大,图中为-415;以 DC 系数为出发点向下、向右的其它 DCT 系数,离 DC 分量越远,频率越高,幅度值越小,图中最右下角为2,即图像信息的大部分集中于直流系数及其附近的低频频谱上,离 DC 系数越来越远的高频频谱几乎不含图像信息,甚至于只含杂波。
DCT 本身虽然没有压缩作用,却为以后压缩时的”取”、”舍” 奠定了必不可少的基础。
3. 量化
3.1 基本概念
量化过程实际上就是对 DCT 系数的一个优化过程。它是利用了人眼对高频部分不敏感的特性来实现数据的大幅简化。量化过程实际上是简单地把频率领域上每个成份,除以一个对于该成份的常数,且接着四舍五入取最接近的整数。这是整个过程中的主要有损运算。以这个结果来说,经常会把很多高频率的成份四舍五入而接近0,且剩下很多会变成小的正或负数。整个量化的目的是减小非“0”系数的幅度以及增加“0”值系数的数目。
量化是图像质量下降的最主要原因。
3.2 实例1

DQT变换后左上角值表明了该分块的平均值,通常被称为直流分量,其余的63个值为交流分量
3.2 实例2
对于《2. DCT-离散余弦变换》中的实例2,这里也进行一个量化的说明。因为人眼对亮度信号比对色差信号更敏感,因此使用了两种量化表:亮度量化值和色差量化值。
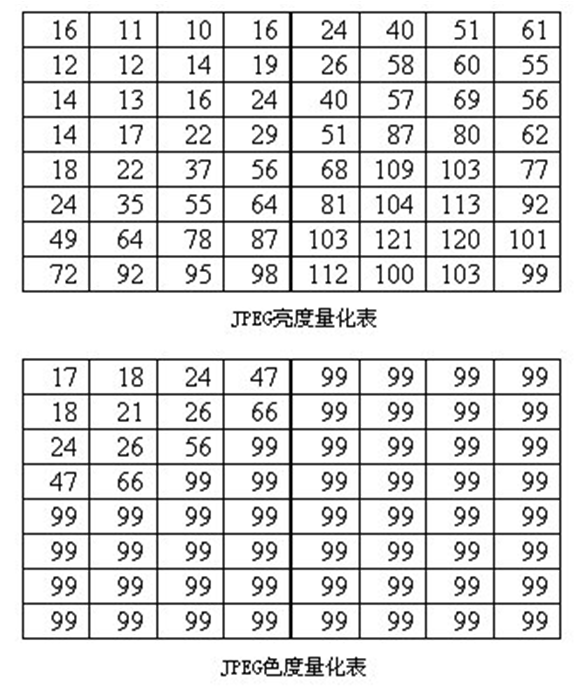
使用这个量化矩阵与前面所得到的 DCT 系数矩阵:
如,使用−415(DC系数)且四舍五入得到最接近的整数:
$$
[(\frac{-415}{16})]=[-25.9375]=-26
$$
公式中的[]表示取整运算。总体上来说,DCT 变换实际是空间域的低通滤波器。对 Y 分量采用细量化,对 UV 采用粗量化。量化表是控制 JPEG 压缩比的关键,这个步骤除掉了一些高频量;另一个重要原因是所有图片的点与点之间会有一个色彩过渡的过程,大量的图像信息被包含在低频率中,经过量化处理后,在高频率段,将出现大量连续的零。
4. 编码
4.1 编码分类
有两类数据需要做编码,直流分量和交流分量。
4.1.1 直流分量的编码
编码信息分两类,一类是每个8*8格子F中的[0,0]位置上元素,这是DC(直流分量),代表8*8个子块的平均值,JPEG中对F[0,0]单独编码,由于系数的数值比较大,两个相邻的8*8子块的DC系数相差很小,所以对它们采用差分编码DPCM(Difference Pulse Code Modulation),可以提高压缩比,也就是说对相邻的DU子块DC系数的差值进行编码,对差值进行编码所需要的位数会比对原值进行编码所需要的位数少了很多。假设某一个8*8图像块的DC系数值为15,而上一个8*8图像块的DC系数为12,则两者之间的差值为3。

Tips:JPEG对直流分量采用差分编码的形式处理,后一个DU块的直流分量只记录与前一个DU块直流分量的差值
4.1.2 交流分量的编码
另一类是8*8块的其它63个子块,即交流(AC)系数,采用 行程编码(游程编码Run-length encode,RLE)。这里出现一个问题:这63个系数应该按照怎么样的顺序排列?为了保证低频分量先出现,高频分量后出现,以增加行程中连续“0”的个数,这63个元素采用了“之”字型(Zig-Zag)的排列方法,如下图所示。
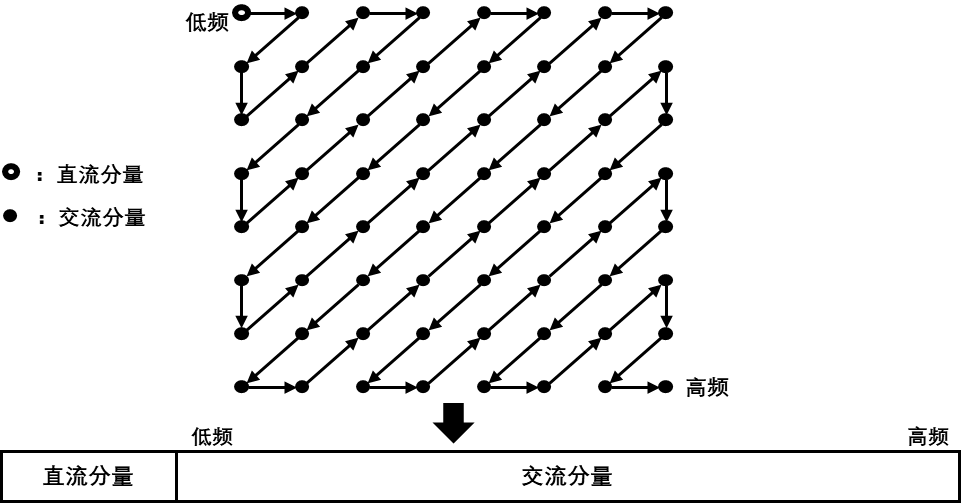
为什么要进行Zig-Zag变换?
答:会连续出现多个0,这样很有利于使用简单而直观的行程编码(RLE:Run Length Coding)对它们进行编码。
量化之后的数据交流分量大部分值都趋近于0,经过Zig-Zag变换后,数据中存在大量连续的0,非常适合采用RLE编码提高压缩率。
4.2 数据存储
JPEG在进行数据存储的过程中,不直接存储数值,而是按照二进制数值+数值比特数的方式表达,例如
- 3会表达成2-11b,其中2表示占用2个bit,值为二进制11;
- -6表示为3-001b,负数表达方式为取反的正数对应的二进制数值取反,-6的正数为6,二进制为110b,取反就是001b。

这个表可以暂时称为VLI(Variable-length Code)表。
4.3 行程编码简介
Run Length Encoding,行程编码又称“运行长度编码”或“游程编码”,它是一种无损压缩编码。用于更进一步降低数据的传输量。利用该编码方式,可以将一个字符串中重复出现的连续字符用两个字节来代替,其中,第一个字节代表重复的次数,第二个字节代表被重复的字符串。
举例来说,一组资料串”AAAABBBCCDEEEE”,由4个A、3个B、2个C、1个D、4个E组成,经过变动长度编码法可将资料压缩为4A3B2C1D4E(由14个单位转成10个单位)。
简言之,其优点在于将重复性高的资料量压缩成小单位;然而,其缺点在于:若该资料出现频率不高,可能导致压缩结果资料量比原始资料大,例如:原始资料”ABCDE”,压缩结果为”1A1B1C1D1E”(由5个单位转成10个单位)。
在JPEG编码中,假设RLC编码之后得到了一个(M,N)的数据对,其中M是两个非零AC系数之间连续的0的个数(即,行程长度),N是下一个非零的AC系数的值。采用这样的方式进行表示,是因为AC系数当中有大量的0,而采用Zig-zag扫描也会使得AC系数中有很多连续的0的存在,如此一来,便非常适合于用RLE进行编码。对经过“Z”字形编排过的数据,即可以用行程编码来对其进行大幅度的数据压缩。
我们来用一个简单的例子来详细说明一下:
1 | 57,45,0,0,0,0,23,0,-30,-16,0,0,1,0,0,0,0 ,0 ,0 ,0,...,0 |
可以表示为
1 | (0,57) ; (0,45) ; (4,23) ; (1,-30) ; (0,-16) ; (2,1) ; (0,0) |
即每组数字的头一个表示0的个数,而且为了能更有利于后续的处理,必须是 4 bit,就是说,只能是 0~15,这是的这个行程编码的一个特点。如果AC系数之间连续0的个数超过16,则用一个扩展字节(15,0)来表示16连续的0。
AC系数的中间格式
根据前面提到的数据存储表格,对于前面的字符串:
只处理每对数右边的那个数据,对其进行编码,查找上面的数据存储编码表格,可以发现,57在第6组当中,因此,可以将其写成(0,6),57的形式,该形式,称之为AC系数的中间格式。同样的(0,45)的中间格式为:(0,6),45;(1,-30)的中间格式为:(1,5),-30;
我们再来看一个例子帮助理解:
2
3
4
5
6
7
8
9
10
11
12
(1)
DU数据为:5, -3, 2, 0, 0, 0, 1, 0, 0, 0, 2,其余为0
对非0值编码:3-101b, 2-00b, 2-10b, 0, 0, 0, 1-1b, 0, 0, 0, 2-10b,其余为0
RLE编码:3-101b, (0,2)-00b, (0,2)-10b, (3,1)-1b, (3, 2)-10b, (EOB)
组合:(0x3)-101b, (0x02)-00b, (0x02)-10b, (0x31)-1b, (0x32)-10b,(0x00)
(2)
DU数据: 2, 3, 0, -1, 0, 0, 4, 其余为0
对非0值编码:2-10b, 2-11b, 0, 1-0b, 0, 0, 3-100b, 其余为0
RLE编码:2-10b, (0,2)-11b, (1,1)-0b, (2,3)-100b, (EOB)
组合:(0x2)-10b, (0x02)-11b, (0x11)-0b, (0x23)-100b, (0x00)
4.4 熵编码
4.4.1 基本概念
在得到DC系数的中间格式和AC系数的中间格式之后,为进一步压缩图象数据,有必要对两者进行熵编码。JPEG标准具体规定了两种熵编码方式:范数Huffman编码和算术编码。JPEG基本系统规定采用范数Huffman编码(因为不存在专利问题),但JPEG标准并没有限制JPEG算法必须用Huffman编码方式或者算术编码方式。
范数Huffman 编码即 Canonical Huffman Code,现在流行的很多压缩方法都使用了范式哈夫曼编码技术,如 GZIB、ZLIB、PNG、JPEG、MPEG 等。
范数Huffman编码有如下特性:
码字从0开始
码字按照码字长度,由短到长排列
相同长度的码字依次递增
较长的码字,由前一长度最后一个码字+1后,乘2的位数差值次幂生成
范数Huffman 编码可以通过查表完成,如下图:
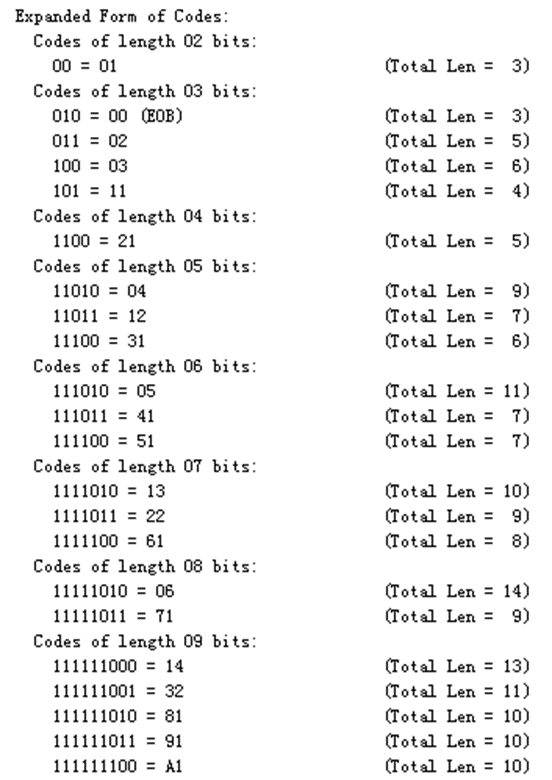
4.4.2 实例1
我们来看一个实例,还是上一节的一个:
1 | 组合: (0x3)-101b, (0x02)-00b, (0x02)-10b, (0x31)-1b, (0x32)-10b, (0x00) |
4.4.3 实例2
再来看一个实例吧,帮助理解。下表是例子所用的AC系数的Huffman表,这里并不是很全,网上搜一下就有很全的了。
| run/size value (RSV) | VLC length | Variable-length Code (VLC) | run/size value (RSV) | VLC length | Variable-length Code (VLC) |
|---|---|---|---|---|---|
| 0/1 | 2 | 00 | 3/2 | 9 | 111110111 |
| 0/2 | 2 | 01 | 8/1 | 9 | 111111000 |
| 0/3 | 3 | 100 | 9/1 | 9 | 111111001 |
| 0/0 | 4 | 1010 | A/1 | 9 | 111111010 |
| 0/4 | 4 | 1011 | 0/8 | 10 | 1111110110 |
| 1/1 | 4 | 1100 | 2/3 | 10 | 1111110111 |
| 0/5 | 5 | 11010 | 4/2 | 10 | 1111111000 |
| 1/2 | 5 | 11011 | B/1 | 10 | 1111111001 |
| 2/1 | 5 | 11100 | C/1 | 10 | 1111111010 |
| 3/1 | 6 | 111010 | 1/5 | 11 | 11111110110 |
| 4/1 | 6 | 111011 | 5/2 | 11 | 11111110111 |
| 0/6 | 7 | 1111000 | D/1 | 11 | 11111111000 |
| 1/3 | 7 | 1111001 | F/0 | 11 | 11111111001 |
| 5/1 | 7 | 1111010 | 2/4 | 12 | 111111110100 |
| 6/1 | 7 | 1111011 | 3/3 | 12 | 111111110101 |
| 0/7 | 8 | 11111000 | 6/2 | 12 | 111111110110 |
| 2/2 | 8 | 11111001 | 7/2 | 12 | 111111110111 |
| 7/1 | 8 | 11111010 | 8/2 | 15 | 111111111000000 |
| 1/4 | 9 | 111110110 | the rest 125 VLCs | 16 | ··· |
假设一个图像块经过量化以后得到以下的系数矩阵:
1 | 15 0 -1 0 0 0 0 0 |
显然,DC系数为15,假设前一个8*8的图像块的DC系数量化值为12,则当前DC系统同上一个DC系数之间的差值为3,通过查找VLI编码表,可以得到DC系数的中间格式为(2)(3),这里的2代表后面的数字(3)的编码长度为2位;
之后,通过Zig-zag扫描之后,遇到第一个非0的AC系数为-2,遇到0的个数为1,AC系数经过RLC编码后可表示为(1,-2),通过查找VLI表发现,-2在第2组,因此,该AC系数的中间格式为(1,2)-2;
其余的点类似,可以求得这个8*8子块熵编码的中间格式为
1 | (DC)(2)(3);AC(1,2)(-2),(0,1)(-1),(0,1)(-1),(0,1)(-1),(2,1)(-1),(EOB)(0,0) |
对于DC系数的中间格式(2)(3)而言,数字2查DC亮度Huffman表得到011,数字3通过查找VLI编码表得到其被编码为11;
对于AC系数的中间格式(1,2)(-2)而言,(1,2)查AC亮度Huffman表得到11011,-2通过查找VLI编码表得到其被编码为01;
对于AC系数的中间格式(0,1)(-1)而言,(0,1)查AC亮度Huffman表得到00,数字-1通过查找VLI编码表得到其被编码为0;
对于AC系数的中间格式(2,1)(1)而言,(2,1)查AC亮度Huffman表得到11100,数字-1通过查找VLI编码表得到其被编码为0;
对于AC系数的中间格式(0,0)而言,查AC亮度Huffman表得到1010;
因此,最后这个8*8子块亮度信息压缩后的数据流为
1 | 01111,1101101,000,000,000,111000,1010 |
总共31比特,其压缩比是64*8/31=16.5,大约每个像素用半个比特。
5. 参考资料
三、JPEG解码原理
1. 解码实例1
解码就是一个逆过程,这里不详细去了解了,以上面这组数据为例:
1 | 组合: (0x3)-101b, (0x02)-00b, (0x02)-10b, (0x31)-1b, (0x32)-10b, (0x00) |
大概流程就是:
1、解码直流分量,解熵编码,从Huffman表第一个长度2bit开始,读入2bit-10b
2、10b表中没有记录,读入下一长度3bit-100b,查找100b对应的码字为0x3
3、继续读取3bit101b,转换成数值为5
4、解码交流分量,解熵编码,得到熵解码结果0x02,高4bit为0,表明前面没有0,低4bit为2,表明后面数值位数为2,读取2bit-00b,转换后值为-3
5、依次解码知道遇到EOB符号结束,后续的交流分量补0。
2. 解码实例2
